
Un modèle de surveillance des maladies non transmissibles au Canada :
Le Système pilote de surveillance du diabète des Prairies
Vol 25 No 1, 2004
Robert C James, James F Blanchard, Dawn Campbell, Clarence Clottey, William Osei, Lawrence W Svenson et Thomas W Noseworthy
Résumé
Le projet pilote de surveillance du diabète des Prairies a été mis sur pied dans le but de concevoir et de tester un prototype de système de surveillance dans une population générale d'une maladie chronique (le diabète sucré) à l'aide de données administratives. Le modèle canadien de système de surveillance de la santé publique pour les maladies chroniques décrit dans le présent document consiste en un processus par lequel les données administratives et les données liées aux demandes de remboursement des médecins tirées des programmes provinciaux d'assurance-maladie sont fusionnées en un fichier récapitulatif individuel annuel (FRIA). Ce processus permet de produire un dossier récapitulatif pour chacune des personnes assurées dans une province donnée. Le FRIA sert de base à différentes estimations, notamment celles qui ont trait à l'incidence, à la prévalence, à la mortalité, aux complications et à l'utilisation des services de santé. Le modèle a permis de produire des estimations interprovinciales comparables de plusieurs paramètres se rattachant au diabète pour l'ensemble de la population dans les provinces de l'Alberta, du Manitoba et de la Saskatchewan. Le traitement des données identifiables sur la santé a été effectué dans les provinces où les données ont été produites. La combinaison des résultats des provinces s'est faite en agrégeant davantage les données sommaires de chaque province et non pas en groupant les données individuelles identifiables. Sur le plan des extrants préliminaires sur le diabète sucré, le modèle semble produire des estimations cohérentes des paramètres clés du diabète et fait ressortir les différences prévues au niveau des services de santé et des résultats sur le plan de la santé, par état morbide. Trois caractéristiques du modèle font qu'il est tout indiqué en tant que source d'information pour la surveillance des maladies non transmissibles au Canada : a) il utilise au maximum les données existantes; b) il inclut à la fois les personnes atteintes de la maladie en question et celles qui ne le sont pas et c) il respecte les dispositions législatives provinciales en matière de données personnelles sur la santé, tout en permettant la communication de données interprovinciales sur une population.
Mots-clés : diabète sucré; données administratives; données sur une population; maladies chroniques; maladie non transmissible; surveillance de la santé publique
Introduction
Les données estimatives sur la santé et la maladie basées sur une population sont les principaux résultats qui découlent des activités de surveillance de la santé publique1. Toutefois, il arrive souvent qu'on manque d'estimations fiables sur les affections chroniques importantes, notamment en ce qui a trait aux maladies concomitantes, à la mortalité prématurée, aux coûts directs et indirects, aux mesures de l'incidence, de la prévalence, de la durée et de la rémission, ainsi qu'aux taux de létalité2. Cette lacune reflète la pénurie de modèles de surveillance des maladies chroniques basée sur une population. En guise de solution à ce problème, une analyse secondaire des données sur la population provenant des systèmes d'assurance-maladie provinciaux a été proposée3. Cette analyse secondaire semble particulièrement intéressante pour le Canada, vu que les programmes d'assurance-maladie provinciaux et territoriaux donnent un aperçu de la situation à l'échelle de toute une population : en effet, tous les résidents du Canada bénéficient d'une assurance-maladie, à l'exception d'exclusions spécifiques des régimes d'assurance provinciaux, par exemple les membres des forces armées et du corps de police national. Chaque province ou territoire met sur pied son propre système d'assurance, et chacun de ces systèmes génère un quelconque identificateur personnel unique, qui confirme l'admissibilité de la personne à l'assurance. Tous les systèmes de collecte de données des services de soins ambulatoires et des hôpitaux utilisent cet identificateur unique.
Plusieurs chercheurs se sont servis des données administratives pour leurs études sur des maladies chroniques particulières4-10. Le système de surveillance du diabète du Manitoba, en collaboration avec les établissements d'enseignement supérieur et le gouvernement, a fourni des estimations des taux d'incidence, de prévalence et de complication du diabète, ainsi que des projections du fardeau qu'il représentera4,5,11,12. Divers établissements de recherche canadiens ont donné des estimations épidémiologiques de plusieurs affections à partir de bases de données administratives; ces projets étant essentiellement intermittents et axés sur la recherche, ils ne sauraient combler le besoin d'une surveillance longitudinale de la santé, basée sur une population. Qui plus est, ces projets de recherche ne sont généralement pas intégrés aux activités de surveillance interprovinciales ou nationales de la santé publique. On aurait avantage à mettre sur pied des initiatives continues de surveillance de la santé publique à l'échelle interprovinciale et nationale, fondées sur des données administratives.
Le groupe chargé du système pilote de surveillance du diabète des Prairies a été mis sur pied dans le but de concevoir et de tester une méthode de surveillance d'une affection chronique précise, le diabète sucré, basée sur une population, reposant sur des données administratives et pouvant être appliquée à toutes les provinces et aux territoires. Au départ, le groupe avait l'intention d'appliquer le système actuel de surveillance du diabète du Manitoba à la Saskatchewan et à l'Alberta, et ainsi, de faciliter le compte rendu des données interprovinciales4,5; mais, les choses ont évolué et le «modèle du Manitoba» s'est considérablement élargi. Cet article a pour objet de décrire le modèle révisé, ses caractéristiques et ses limites et de présenter quelques-uns des résultats des analyses des données interprovinciales sur le diabète, basées sur une population.
Le modèle
Deux zones différentes caractérisent ce modèle de surveillance (figure 1). La Zone 1 (représentée par le carré) montre l'existence d'informations individuelles basées sur une population, généralement accessibles par le biais de l'administration des services de santé financés à même les fonds publics. Au Canada, ce sont généralement les provinces et les territoires qui détiennent ces informations. Un nombre minime d'organismes au sein du gouvernement fédéral sont aussi gardiens de données personnelles sur la santé pour un groupe restreint de populations, y compris les détenus fédéraux et les membres des forces armées et du corps de police national. Bien que tous ces organismes pourraient être intégrés dans la Zone 1, notre expérience et cet article se limite aux provinces et aux territoires. La Zone 2 (représentée par le cercle) montre les utilisateurs des données de surveillance qui n'ont pas accès aux informations individuelles; au Canada, la Zone 2 comprend le grand public, beaucoup de groupes de défense des droits en matière de santé, les services d'évaluation et de planification des ministères de la Santé provinciaux et le gouvernement fédéral, compte tenu du rôle qu'il exerce sur le plan des politiques et de la planification en matière de santé à l'échelle nationale. Il est important de noter que, selon leur besoin de détenir des données individuelles sur la santé, différents organismes au sein d'une unité administrative (comme par exemple, une province) peuvent être répartis dans des zones différentes.
FIGURE 1
Représentation schématique du modèle de surveillance d'une maladie chronique illustrant l'utilisation des fichiers d'entrée de données sur les soins médicaux/ambulatoires («M»), des données hospitalières («H») et des listes des clients pour la production d'un fichier récapitulatif individuel annuel (FRIA)
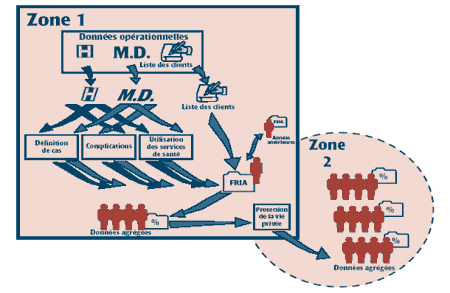
Dans la Zone 1, le modèle consiste en une série d'étapes de manipulation des données sur les transactions individuelles. Au cours du processus, l'unité d'observation produit des données récapitulatives individuelles à partir d'intrants individuels basés sur des transactions; par la suite, ces données récapitulatives sont agrégées pour produire des informations sur les populations.
Dans le modèle, seules les données agrégées sont transférées de la Zone 1 à la Zone 2, confirmant ainsi le fait que les activités des organismes de la Zone 2 n'ont pas besoin de données individuelles sur la santé pour leurs activités. Les ensembles de données agrégées servent surtout à donner des renseignements stratifiés d'une manière adéquate, notamment des nombres, des taux, des sommes et d'autres statistiques sur la distribution selon des paramètres épidémiologiques (par exemple, les taux d'incidence et de prévalence se rattachant à l'affection à l'étude).
Nous traiterons maintenant en détail de chacune des zones et des étapes du processus.
Zone 1
La Zone 1 comporte quatre processus essentiels : l'acquisition des données brutes, la manipulation des données, l'élaboration du produit clé (le fichier récapitulatif individuel annuel [FRIA]) et la production de divers ensembles de données agrégées à partir du FRIA. Chacun de ces quatre processus mérite une analyse détaillée.
Entrées de données. Le modèle exige que les principales bases de données opérationnelles à l'appui des systèmes d'assurance-maladie au sein d'une administration puissent être copiées et soient accessibles à des fins de surveillance. Il faut qu'il existe au moins trois fichiers principaux : une liste globale des personnes assurées (la liste des clients), s'accompagnant de listes des soins médicaux/ambulatoires (indiqués par la lettre «M») et des services hospitaliers («H») fournis à ces personnes. Ces fichiers doivent avoir pour caractéristiques essentielles un identificateur personnel unique permettant le couplage des données entre les fichiers, une liste des personnes assurées qui constitue un recensement fiable des personnes admissibles à l'assurance et des renseignements sur l'âge, le sexe, le lieu, les périodes d'assurance et, pour les personnes décédées, la date du décès. Enfin, les bases de données sur les soins ambulatoires et les sorties des hôpitaux doivent contenir des renseignements sur les diagnostics. (Ces conditions sont remplies dans bon nombre des provinces et territoires canadiens, mais pas dans tous; les progrès réalisés récemment en ce qui concerne un dossier électronique national de santé devraient favoriser l'observation de ces conditions à l'échelle nationale.)
Manipulation des données. Une fois les données acquises, la deuxième étape consiste à trier et à coupler les entrées selon l'identificateur personnel, puis à manipuler et à résumer ces entrées de manière à obtenir des données récapitulatives annuelles qui appuieront trois activités distinctes : 1) l'identification de cas, 2) la mesure du recours aux services de santé et 3) la détection des complications ou des maladies concomitantes. L'application de ces trois activités aux deux intrants pour les services donne en tout six processus, chacun reposant sur une logique et des extrants distincts. Les détails concernant le fonctionnement de ces six processus de manipulation des données, y compris la spécification des définitions de cas et les complications et les services de santé qui sont saisis, ne sont pas définis par le modèle et doivent être élaborés et validés pour chaque nouvelle activité de surveillance d'une maladie.
Création d'un fichier récapitulatif individuel annuel (FRIA). Pour produire un FRIA, on combine les extrants des six processus décrits à l'information résumée à partir de la liste des clients (qui comprend normalement l'âge, le sexe et l'état matrimonial de la personne) et des données des années antérieures du fichier récapitulatif. (Il arrive, dans de rares cas, qu'on ne puisse établir de lien entre les transactions et une personne identifiée sur la liste des clients; ces transactions sont supprimées, et le nombre de transactions supprimées est enregistré.) Le FRIA contient un dossier pour chaque personne ayant bénéficié de l'assurance-maladie dans la province ou le territoire participant au cours de l'année, peu importe si la personne a eu recours ou non à des services de santé cette année-là. Dans ce fichier, l'unité d'observation est l'individu. Chacun des dossiers contenu dans le FRIA renferme habituellement les nombres et les montants de certains services de santé utilisés par la personne, les dates des diagnostics posés et des événements ou des complications survenus au cours de l'année, ainsi que des données démographiques.
Agrégation et estimation des taux. Le FRIA constitue la base à partir de laquelle on peut produire divers ensembles de données agrégées, qui incluraient normalement des taux, des nombres et la caractérisation de la distribution dans les groupes de population stratifiés selon l'âge, le sexe, la région géographique et l'état morbide imputé. Comme le FRIA comprend un dossier sur chaque personne au sein d'une province ou d'un territoire, il fournit des estimations de la population à risque de résultats particuliers pour la santé.
Le FRIA permet de calculer divers dénominateurs possibles, notamment les estimations de la population moyenne et les estimations relatives aux personnes-années d'observation. Certaines provinces ou certains territoires peuvent préférer des sources externes de dénominateurs, telles que les chiffres de population basés sur le recensement. Les provinces ou les territoires dont les listes de clients ne rendent pas compte avec exactitude de la structure de la population peuvent vouloir se fonder sur les données du recensement ou d'autres sources de dénominateurs.
Les ensembles de données du FRIA permettraient généralement de produire divers types d'estimations agrégées, entre autres les estimations des taux d'incidence, de prévalence et de mortalité, ainsi que la caractérisation de la distribution des honoraires médicaux et des journées d'hospitalisation. Encore une fois, ces paramètres peuvent être stratifiés selon les caractéristiques géographiques et démographiques et l'état morbide imputé.
Zone 2
La Zone 2 a pour but de donner un contexte au transfert des données agrégées pour les utilisateurs qui ne sont pas les gardiens des données individuelles. En vertu de ce modèle, on vérifierait les ensembles de données agrégées préparés en vue de leur transfert de la Zone 1 à la Zone 2 afin de s'assurer qu'il n'y a pas de risques de divulgation par recoupements à l'intérieur de la Zone 1, et ce n'est qu'alors qu'on les diffuserait dans la Zone 2. Les stratifications appropriées des principales variables démographiques, comme l'âge ou la région géographique, peuvent être définies de façon ponctuelle, selon les variables disponibles à partir de la liste des clients, de manière à permettre un maximum de souplesse sur le plan de la communication des résultats tout en assurant la protection des renseignements personnels. Les autres points à prendre en considération peuvent inclure l'uniformité du compte rendu des données entre les organismes de la Zone 1.
Lorsqu'il s'agit d'assurer la confidentialité des ensembles de données agrégées, il existe une vaste gamme d'options, notamment la pratique reconnue depuis longtemps consistant à supprimer les cellules renfermant de petits chiffres, et plusieurs autres méthodes plus récentes13.
Questions liées à la mise en oeuvre
Le modèle a été mis en ?uvre au moyen du logiciel SAS® (marque de commerce déposée de SAS Institute Inc.). Il s'agit d'un ensemble de logiciels commun aux trois participants de la Zone 1 - les provinces des Prairies, soit l'Alberta, le Manitoba et la Saskatchewan. On a également créé un petit ensemble de codes, propres à chaque province, qui a facilité l'utilisation d'un dictionnaire de données commun aux trois provinces (chacune ayant des solutions informatiques et des dictionnaires de données distincts) et qui a permis de prendre en compte divers détails locaux, tels que les noms des fichiers et le nombre d'années d'entrée de données. (Les détails concernant le logiciel peuvent être obtenus sur demande auprès des auteurs.) Un ensemble de logiciels commun aux provinces a simplifié l'élaboration et la répartition et a amélioré la comparabilité.
Le traitement des données identifiables sur la santé a été effectué dans les provinces où les données ont été produites. La combinaison des résultats des provinces s'est faite en agrégeant davantage les fichiers récapitulatifs de chaque province et non pas en groupant les données individuelles identifiables des provinces. Ni les transactions ni les dossiers du FRIA n'ont été transférés à l'extérieur de leurs provinces d'origine.
Seul un petit ensemble des six modes d'entrée/processus envisagés par le modèle a été inclus dans le projet pilote. Par exemple, on n'a entrepris aucune évaluation des complications ou des maladies concomitantes à l'aide de l'information sur les diagnostics trouvée dans les données sur les services médicaux/ambulatoires. Le modèle, tel qu'il a été mis en ?uvre, a suffit à reproduire le modèle de surveillance initial utilisé au Manitoba4,5.
Un exemple
Méthodologie
Le logiciel créé pour mettre en ?uvre le modèle a été fourni aux ministères provinciaux de la santé de l'Alberta, du Manitoba et de la Saskatchewan. Ce logiciel utilisait une définition de cas de diabète légèrement différente de celle du Manitoba : on a considéré que les adultes étaient atteints de diabète à partir du moment où l'on relevait un seul diagnostic de diabète dans un dossier de sortie d'hôpital ou plusieurs diagnostics de diabète dans les données sur les soins médicaux/ambulatoires sur une période de deux ans. Blanchard et ses collaborateurs4 ont proposé initialement cette définition de cas. Dans des études subséquentes, Hux et ses collaborateurs ont estimé que cette définition avait un degré de spécificité de 97 % et un degré de sensibilité de 86 %14. Le dénominateur des taux signalés a été calculé à partir des personnes-années d'observation - une mesure disponible dans le FRIA. Nous faisons état des données les plus récentes disponibles pour ce projet pilote (1997 ou 1998, selon la province). Vu qu'il s'agit d'un projet pilote, les estimations ne sont fournies que pour donner un exemple des extrants produits grâce à ce modèle; les résultats significatifs pourront faire l'objet d'une étude plus poussée.
Résultats et analyse
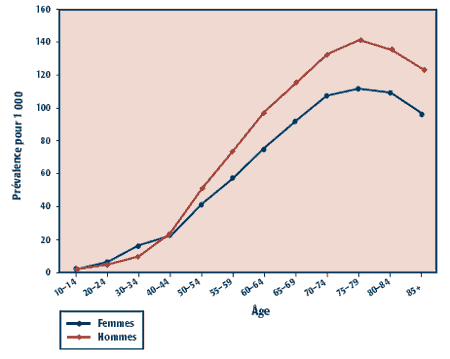
La figure 2 illustre les taux de prévalence estimés du diabète, selon le sexe, combinés pour les trois provinces. Le taux de prévalence augmente petit à petit chez les hommes et chez les femmes, jusqu'à la fourchette d'âge des 75 à 79 ans, après quoi, il affiche une faible baisse. Chez les femmes, ce taux est légèrement plus élevé dans le groupe des 20 à 40 ans, mais ce résultat est vraisemblablement attribuable à la façon dont le diabète gestationnel a été pris en compte dans le cadre du projet pilote. Par la suite, les taux de prévalence sont plus élevés chez les hommes que chez les femmes.
FIGURE 2
Prévalence estimative annuelle du diabète sucré dans les provinces des Prairies, selon l?âge et le sexe, d?après les données administratives
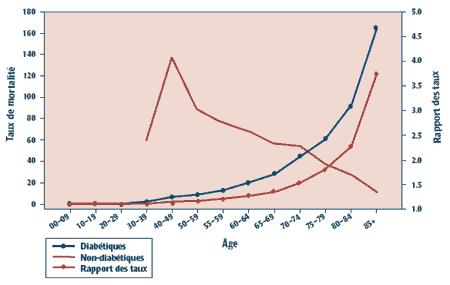
La figure 3 présente les taux de mortalité annuels chez les populations diabétique et non diabétique dans les provinces des Prairies et révèle une hausse au fur et à mesure que les deux populations avancent en âge. Chez les diabétiques, le taux de mortalité est systématiquement supérieur à celui des non-diabétiques. Le rapport des taux peut se calculer en divisant les taux de mortalité selon l'âge et le sexe dans la population diabétique par les mêmes taux dans la population non diabétique. Avant l'âge de 70 ans, le rapport des taux diminue pour passer d'environ cinq dans le groupe d'âge des 40 ans à environ deux dans les groupes d'âge de 70 ans et plus. Le fait de pouvoir faire état des taux de mortalité dans les populations diabétique et non diabétique et d'estimer les rapports comparatifs des taux montre à quel point il est important d'inclure l'ensemble de la population dans le FRIA et dans les ensembles de données agrégées.
FIGURE 3
Taux annuels estimatifs de mortalité, selon l?âge, par diagnostic de diabète, pour les provinces des Prairies, d?après les données administratives
Les résultats de cet exemple correspondent aux tendances prévues dans l'épidémiologie du diabète, notamment en ce qui concerne la prévalence plus élevée de la maladie chez les personnes plus âgées et les taux de mortalité plus hauts dans la population diabétique que dans la population non diabétique.
Analyse
La prévention et la prise en charge d'une maladie chronique exigent une surveillance continue, comparable et systématique. Dans les pays qui sont des fédérations, il est important que la surveillance soit comparable entre les provinces ou les États. Bien que plusieurs centres de recherche en santé aient rendu compte de temps à autre d'estimations épidémiologiques ayant trait à des maladies particulières, leurs rapports ne constituent pas des activités de surveillance de la santé publique et consistent habituellement en des analyses sporadiques, axées sur la recherche et portant sur une seule province ou un seul État. Jusqu'à présent, on n'a pas adapté ces initiatives afin qu'elles tiennent compte des difficultés techniques et stratégiques d'une surveillance continue dans toutes les provinces ou dans tous les États. Aucun rapport n'a été publié sur des modèles qui tiennent compte des problèmes d'ordre technique, stratégique et liés aux compétences que pose la surveillance interprovinciale comparable d'une maladie chronique. Nous décrivons un tel modèle et nous rendons compte des résultats préliminaires d'un prototype de système de surveillance du diabète sucré.
Le modèle en question comporte trois caractéristiques importantes qui nous permettent de déduire qu'il serait tout indiqué pour la surveillance des maladies chroniques : il maximise l'utilité des données existantes; il inclut aussi bien les personnes atteintes d'une maladie que les personnes qui n'en sont pas atteintes, permettant de ce fait de déterminer dans une population les différences dans les résultats et dans l'utilisation des services de santé; enfin, il définit des rôles distincts et appropriés pour ceux qui ont la garde des données personnelles en matière de santé et pour ceux qui n'en ont pas la garde. De cette façon, il propose des rôles distincts pour les provinces, les territoires et le gouvernement fédéral, qui sont en accord avec les réalités législatives et constitutionnelles canadiennes.
Non seulement le modèle permet de produire un registre des personnes ayant reçu un diagnostic de maladie présentant un intérêt, mais il va au-delà de la notion classique de registre en incluant les non-cas et en saisissant les données sur les complications, les services de santé et les résultats pour la santé. Cette approche permet d'estimer les fractions étiologiques de divers résultats et les rapports des taux d'utilisation des services de santé, qui peuvent être reliés à certaines maladies présentant un intérêt. Par exemple, avec ce modèle, on devrait pouvoir estimer la proportion du fardeau pour la population d'une complication donnée, telle que l'amputation d'un membre inférieur, intervention qui doit parfois être pratiquée chez des diabétiques. Les registres actuels basés uniquement sur les cas n'incluent habituellement pas les non-cas et ne permettent donc pas de procéder à ces types d'analyse.
Le modèle a cependant ses limites. Il faut toujours prendre en considération la qualité du diagnostic et d'autres renseignements contenus dans les fichiers des services hospitaliers et des soins médicaux/ ambulatoires. Les registres provinciaux des personnes assurées par le régime d'assurance-maladie doivent être relativement complets. Des estimations inexactes de la population établies à partir des listes des personnes assurées ou de l'information incomplète sur les diagnostics peuvent donner lieu à des estimations épidémiologiques erronées.
Il faut admettre que les données administratives portent surtout sur les diagnostics, les interventions et l'utilisation des ressources, plutôt que sur les facteurs de risque, le comportement ou d'autres paramètres cliniques pertinents. La création de dossiers médicaux électroniques peut combler des lacunes importantes au niveau de la disponibilité et de la qualité des données. La collecte de données primaires et des enquêtes représentatives axées sur des cohortes servant à étudier des maladies précises peuvent s'avérer des méthodes utiles pour obtenir les covariables qui font défaut dans les données administratives.
La réduction des données personnelles sur la santé dans des fichiers annuels représente une autre limite du modèle, en ce sens qu'elle fait perdre de vue l'ordre des événements au cours d'une année donnée. Lorsque la réduction des données fait obstadle à des analyses spécifiques, il faudrait avoir accès à des données non récapitulatives sur les transactions.
Pour le moment, le modèle ne prévoit aucun mécanisme pour le transfert de données récapitulatives individuelles sur la santé entre les organismes de la Zone 1. Cela peut signifier que, selon ce modèle, les migrants atteints d'affections courantes peuvent être classés à tort comme des cas nouveaux dans leur province de destination. Une méthode de transmission des données individuelles récapitulatives sur la santé aux organismes de la Zone 1 permettra d'améliorer le modèle (et, de ce fait, de produire des estimations plus robustes), en particulier lorsque des individus migrent entre les provinces ou les territoires.
On peut aussi reprocher au modèle de ne pas fournir des données individuelles au gouvernement fédéral. Bien que notre manipulation des données des organismes de la Zone 1 permette de surmonter plusieurs obstacles techniques à ce genre de transferts, nous avons décidé de limiter les données individuelles à ces organismes en nous fondant sur notre évaluation du contexte politique canadien. Si des données nominatives sont transférées entre les gouvernements provinciaux, territoriaux et fédéral, ces données portent sur des maladies déjà inscrites dans les annexes des lois et règlements sur la santé publique. Nous ne sommes pas au courant des transferts, entre les organismes de la Zone 1 ou au gouvernement fédéral, de données nominatives qui se rattachent à des maladies non inscrites aux annexes, telles que le diabète.
D'après notre expérience, les exigences législatives provinciales et territoriales en matière de partage des données varient grandement; il en va de même du consentement à partager des données personnelles identifiables sur la santé. Plus particulièrement, nous recon- naissons qu'il existe des questions d'ordre politique importantes qui n'ont pas encore été entièrement résolues en ce qui concerne le partage des données entre les organismes de la Zone 1 et avec le gouvernement fédéral. La protection offerte en vertu de la Loi sur la statistique fédérale peut permettre une centralisation des données des provinces advenant le cas ou, pour une raison d'ordre épidémiologique, il faudrait fusionner des données. On pourrait alors invoquer comme argument qu'il faut faire en sorte que les cas ne soient pas comptés en double ou classés à tort comme des cas nouveaux lorsque les individus migrent d'une province ou d'un territoire à l'autre. Les commissaires provinciaux à la protection de la vie privée ont un rôle crucial à jouer à cet égard.
Le principal avantage de ce modèle est qu'il peut être appliqué à d'autres maladies que le diabète. De toute évidence, les occasions ne manquent pas de mettre à l'essai ce modèle pour d'autres maladies non transmissibles et d'autres états épisodiques, notamment les blessures. Plusieurs autres affections chroniques importantes peuvent aussi se prêter à cette approche. Toutefois, le recours à cette méthode pour augmenter le nombre d'affections faisant l'objet d'une surveillance devrait s'accompagner d'une validation continue des définitions de cas, d'une amélioration de la qualité des paramètres de la santé, de programmes actifs de recherche sur les limites et les points forts de tels modèles, de programmes de collecte de données primaires couplées et d'une analyse minutieuse des extrants de tels modèles. En conjuguant ces différents moyens, on devrait être mieux à même de quantifier les tendances dans les maladies chroniques au Canada.
L'utilisation de ce modèle ne rend pas pour autant inutile les enquêtes représentatives. En fait, l'intégration de ces méthodes accroît l'utilité des données d'enquête et des données administratives. Par exemple, le couplage de ces deux types de données fournit l'occasion de comparer les données autodéclarées aux données administratives. L'information sur les diagnostics ne permettra pas de répondre aux questions concernant les affections qui ne donnent pas lieu à des codes de diagnostic spécifiques; en revanche, des enquêtes représentatives comprenant des prélèvements biologiques seraient utiles. Une coordination étroite des données admi- nistratives et des méthodes d'enquête est fortement recommandée.
Ce modèle et les résultats obtenus constituent une validation de principe, montrant qu'on peut exercer une surveillance interprovinciale de la santé publique basée sur des données administratives sans que les données personnelles sur la santé soient partagées entre les gouvernements. Il sera important de procéder à une validation continue, de même qu'à une validation des nouvelles affections. Toutefois, d'après les résultats, cette initiative pourrait contribuer dans une large mesure à esquisser, plus tôt que prévu, un tableau national multidimensionnel de l'état de santé de la population, même si ces méthodes ne peuvent, à elles seules, permettre de brosser un tableau complet. Enfin, les méthodes décrites ici établissent le fondement des politiques, des compétences et de la technologie qui peuvent et qui devraient nous inciter à renforcer la capacité de surveillance de la santé publique dans l'ensemble du pays.
Remerciements
Les auteurs tiennent à remercier Mme Sylvia Bolt et la Dre Manya Sadouski pour l'aide précieuse qu'elles leur ont apportée.
Ce travail a été réalisé grâce à l'apport financier du Programme de soutien à l'infostructure de la santé de Santé Canada et de l'Alberta Health and Wellness.
Références
- Thacker SB, Berkelman RL. Public health surveillance in the United States. Epidemiol Rev 1988;10:164-90.
- Le fardeau économique de la maladie au Canada, 1998. Ottawa : Santé Canada, 2002.
- Forum national sur la santé (Canada). La santé au Canada : un héritage à faire fructifier. Ottawa : Forum national sur la santé, 1997.
- Blanchard JF, Ludwig S, Wajda A, Dean H, Anderson K, Kendall O, et coll. Incidence and prevalence of diabetes in Manitoba, 1986-1991. Diabetes Care 1996;19(8): 807-11.
- Blanchard JF, Dean H, Anderson K, Wajda A, Ludwig S, Depew N. Incidence and prevalence of diabetes in children aged 0-14 years in Manitoba, Canada, 1985-1993. Diabetes Care 1997;20(4): 512-5.
- Bernstein CN, Blanchard JF. The epidemiology of Crohn's disease. Gastroenterology 1999;116(6):1503-4.
- Svenson LW, Woodhead SE, Platt GH. Regional variations in the prevalence rates of multiple sclerosis in the province of Alberta, Canada. Neuroepidemiology 1994;13(1-2):8-13.
- Svenson LW, Platt GH, Woodhead SE. Geographic variations in the prevalence rates of Parkinson's disease in Alberta. Can J Neurol Sci 1993;20(4):307-11.
- Svenson LW, Cwik VA, Martin WR. The prevalence of motor neurone disease in the Province of Alberta. Can J Neurol Sci 1999;26(2):119-22.
- Spady DW, Schopflocher DP, Svenson LW, Thompson AH. Prevalence of mental disorders in children living in Alberta, Canada, as determined from physician billing data. Arch Pediatr Adolesc Med 2001;155(10):1153-9.
- Young TK, Roos NP, Hammerstrand KM. Estimated burden of diabetes mellitus in Manitoba according to health insurance claims: a pilot study. Can Med Assoc J 1991;144(3):318-24.
- Blanchard J, Wajda,A, Green C. Epidemiologic projection of diabetes and its complications: forecasting the coming storm. URL: <http://www.gov.mb.ca/ health/publichealth/epiunit/docs/storm.pdf>.
- Fienberg SE. Statistical perspectives on confidentiality and data access in public health. Stat Med 2001;20(9-10):1347-56.
- Hux JE, Ivis F, Flintoft V, Bica A. Diabetes in Ontario: determination of prevalence and incidence using a validated administrative data algorithm. Diabetes Care 2002;25(3):512-6.
Coordonnées des auteurs
Robert C James, Centre for Health and Policy Studies, Département des sciences, de santé communautaire, Université de Calgary, Calgary, Alberta, Canada
James F Blanchard, Département des sciences, de santé communautaire, Université du Manitoba, Winnipeg, Manitoba, Canada
Dawn E J Campbell, Consultant, Winnipeg, Manitoba, Canada
Clarence Clottey, Centre de prévention et de contrôle des maladies chroniques, Santé Canada, Ottawa, Ontario, Canada
William Osei, Epidemiology, Research and Evaluation Unit, Saskatchewan Health, Regina, Saskatchewan, Canada
Lawrence W Svenson, Health Surveillance, Alberta Health and Wellness, Département des sciences, de santé communautaire, Université de Calgary,
Calgary, Alberta, Canada
Correspondance : Tom Noseworthy, Centre for Health and Policy Studies, Health Sciences Building, University of Calgary, 3330 Hospital Drive NW, Calgary, Alberta, Canada T2N 4N1; fax : (403) 210-3818; courriel : tnosewor@ucalgary.ca