
Une analyse rétrospective des données pour comprendre le profil linguistique des cas de COVID-19

 Téléchargez cet article en format PDF (157 ko)
Téléchargez cet article en format PDF (157 ko)Publié par : L'Agence de la santé publique du Canada
Numéro : RMTC : Volume 50-10, octobre 2024 : COVID-19 après la pandémie
Date de publication : octobre 2024
ISSN : 1719-3109
Soumettre un article
À propos du RMTC
Naviguer
Volume 50-10, octobre 2024 : COVID-19 après la pandémie
Étude épidémiologique
Possibilités et leçons apprises d'une analyse rétrospective des données administratives de facturation pour comprendre le profil linguistique des contacts étroits à haut risque des cas de COVID-19 en Ontario
Andrea Chambers1, Mark A Cachia2, Jessica P Hopkins1,2
Affiliations
1 Santé publique Ontario, Toronto, ON
2 Département des méthodes, des données probantes et de l'impact de la recherche en santé, Université McMaster, Hamilton, ON
Correspondance
Citation proposée
Chambers A, Cachia MA, Hopkins JP. Possibilités et leçons apprises d'une analyse rétrospective des données administratives de facturation pour comprendre le profil linguistique des contacts étroits à haut risque des cas de COVID-19 en Ontario. Relevé des maladies transmissibles au Canada 2024;50(10):410–5. https://doi.org/10.14745/ccdr.v50i10a06f
Mots-clés : recherche des contacts, COVID-19, SRAS-CoV-2, concordance des langues, pandémie
Résumé
Contexte : Lors d'une urgence de santé publique, il est essentiel d'avoir accès à des sources de données permettant d'identifier les communautés touchées de manière disproportionnée et de s'assurer que les communications en matière de santé publique répondent aux besoins des diverses populations.
Objectif : Étudier comment les données administratives relatives à la facturation des services d'interprétation linguistique pourraient être utilisées comme source d'information supplémentaire pour comprendre le profil linguistique des contacts étroits à haut risque des cas de COVID-19.
Méthodes : Une analyse descriptive rétrospective a été réalisée à partir des données administratives de facturation de l'Initiative de recherche des contacts de Santé publique Ontario, de mai 2020 à février 2022. Les données de l'Initiative de recherche des contacts ont été utilisées pour identifier les facteurs susceptibles d'avoir influencé les tendances des demandes d'interprétation linguistique. Les tendances ont été comparées aux profils linguistiques des communautés à l'aide des données du recensement canadien de 2021.
Résultats : Les interprètes ont répondu à 2 604 demandes en 38 518 minutes d'interprétation et ont fourni des informations dans 50 langues différentes. Les cinq langues les plus demandées sont le français, l'arabe, l'espagnol, le pendjabi et le mandarin. Cinq périodes distinctes ont été identifiées pour la prédominance de différentes langues, notamment l'espagnol au printemps/été 2020, le français à l'été/automne 2020 et l'arabe au printemps 2021. Dans l'ensemble, ces tendances correspondent au profil linguistique des unités de santé qui ont présenté le plus grand nombre de demandes.
Conclusion : Les agences de santé publique pourraient tirer profit de l'utilisation des sources de données secondaires existantes pour comprendre les besoins de leurs communautés en matière d'interprétation linguistique. Cette étude a également montré comment les sources de données existantes pouvaient être utilisées pour aider à évaluer comment les communautés sont affectées de manière disproportionnée par les urgences de santé publique et comment cela peut évoluer dans le temps.
Introduction
La gestion des cas et des contacts est une approche fondamentale de la santé publique pour contrôler la propagation des maladies infectieuses. La gestion des cas et des contacts a été une priorité importante pour de nombreuses administrations au cours des premières phases de la pandémie de COVID-19 Note de bas de page 1. La recherche des contacts consiste à identifier les personnes (« contacts ») susceptibles d'avoir été exposées au SRAS-CoV-2 pendant leur période de contagiosité. Les agences de santé publique communiquent ensuite avec les contacts à haut risque pour les informer de l'exposition et leur fournir des informations sur les tests, les exigences en matière d'isolement et les mesures de soutien. Pour que la gestion des dossiers et des contacts soit efficace et équitable, les informations et le soutien doivent être fournis dans la langue de préférence de la communauté Note de bas de page 2Note de bas de page 3Note de bas de page 4.
Les données socio-économiques recueillies au début de la pandémie de COVID-19 en Ontario ont permis de décrire comment certaines communautés étaient touchées de manière disproportionnée et les premiers résultats ont souligné l'importance d'examiner les capacités linguistiques Note de bas de page 5Note de bas de page 6. En Ontario, environ 16 % de la population parle principalement une langue non officielle à la maison Note de bas de page 7. Une analyse des schémas de dépistage et des résultats des tests au début de la pandémie a révélé que le manque de compétences linguistiques en anglais ou en français était associé à un taux de dépistage plus faible, mais à un pourcentage de résultat positif plus élevé chez les nouveaux arrivants et les réfugiés adultes récents en Ontario Note de bas de page 6.
La collecte de données socio-économiques au niveau individuel auprès des cas de COVID-19 en Ontario n'a pas été étendue à la collecte d'informations auprès des contacts étroits à haut risque des cas de COVID-19. Nous considérons qu'il s'agit d'une lacune, car les effets disproportionnés de la pandémie s'étendent à d'autres résultats et expériences, y compris les effets sur la santé mentale et les conséquences financières des périodes d'isolement multiples et prolongées associées à l'identification d'un contact étroit à haut risque Note de bas de page 8. En outre, les efforts de collecte de données primaires ont pris beaucoup de temps et plusieurs facteurs ont eu un impact sur l'exhaustivité, la précision et la durabilité des données Note de bas de page 9.
Étant donné les lacunes dans la compréhension de la manière dont les services d'interprétation linguistique ont été utilisés parmi les contacts à haut risque pendant la pandémie de COVID-19, cette étude visait à 1) décrire les étapes utilisées pour exploiter les sources de données secondaires afin de comprendre le profil linguistique des contacts étroits à haut risque et 2) décrire comment ce type d'analyse peut aider à enquêter sur les impacts disproportionnés de la pandémie de COVID-19.
Méthodes
Contexte
Cette étude s'est appuyée sur les données de l'Initiative de recherche des contacts dans le cadre de la lutte contre la COVID-19 de Santé publique Ontario (l'Initiative). Entre avril 2020 et février 2022, les 34 Bureaux de santé publique (BSP) locaux de l'Ontario pouvaient utiliser l'Initiative pour aider à gérer le volume de travail associé à la notification des contacts.
Les organismes gouvernementaux provinciaux et fédéraux ont apporté leur soutien pour les appels téléphoniques initiaux et de suivi aux contacts proches à haut risque des cas confirmés ou probables de COVID-19 Note de bas de page 10. Si un contact a besoin de services d'interprétation ou demande si des services sont disponibles, l'interviewer appelle le prestataire de services d'interprétation pour fournir une interprétation simultanée dans la langue préférée du contact. La façon dont ce programme a été élaboré et utilisé par les BSP locaux de l'Ontario est décrite plus en détail dans une publication distincte Note de bas de page 10.
Nous décrivons ci-dessous le processus en quatre étapes utilisé pour effectuer une analyse rétrospective descriptive des sources de données secondaires et une analyse visuelle des tendances afin de décrire le profil linguistique des contacts à haut risque.
Étape 1 : Analyser les données des services d'interprétation linguistique
Nous avons obtenu du fournisseur de services d'interprétation les données relatives à la facturation administrative entre le 4 mai 2020 (première date de facturation) et le 25 février 2022 (dernier jour d'activité et date de facturation possible). Les données de facturation comprenaient une liste de lignes reflétant les demandes d'interprétation, la langue demandée et la durée de l'appel, sans données manquantes pour les variables d'intérêt. Nous avons calculé la fréquence des entretiens avec les services d'interprétation, le temps d'interprétation total cumulé en minutes, le temps d'interprétation médian et l'écart interquartile (EI) pour chaque langue et pour l'ensemble. Une analyse visuelle des tendances temporelles a été utilisée pour identifier les changements dans la prédominance des langues.
Étape 2 : Identifier les facteurs susceptibles d'influencer les tendances des demandes d'interprétation linguistique
Les données de l'Initiative ont été utilisées pour examiner les tendances dans le temps du volume de contacts à haut risque, indépendamment des demandes de traduction, soumis au programme. Nous avons décrit les changements intervenus au fil du temps dans les unités de santé qui soumettaient la majorité des contacts à l'Initiative.
Étape 3 : Comparer les tendances avec les données de recensement spécifiques à la région
À des fins de comparaison, les données du recensement canadien de 2021 ont été extraites pour résumer les informations sur les langues primaires les plus souvent parlées à la maison en Ontario et dans les régions soutenues par les 34 BSP de l'Ontario Note de bas de page 11. Plus précisément, nous nous sommes concentrés sur le nombre de réponses uniques (i.e., le nombre de personnes qui n'ont donné qu'une seule langue) pour la langue parlée le plus souvent à la maison.
Étape 4 : Déterminer les tendances et les divergences
Après avoir réalisé les étapes 1 à 3, des comparaisons ont été effectuées entre les sources de données. Deux questions principales ont permis d'identifier des tendances :
- Les langues les plus demandées pour l'interprétation correspondent-elles aux profils linguistiques (d'après le recensement de 2021) des régions qui soumettent le plus de demandes au programme?
- Les changements dans les principales langues demandées au fil du temps correspondent-ils à des changements dans les BSP locaux qui soumettaient un volume élevé de contacts?
Résultats
Il y a eu 972 625 appels à des contacts à haut risque sur 21 mois (du 14 mai 2020 au 7 février 2022) et moins de 1 % des appels ont nécessité une aide à l'interprétation linguistique. Les interprètes ont répondu à 2 604 demandes, totalisant 38 518 minutes d'interprétation (tableau 1). Au total, 50 langues différentes ont été demandées (tableau 1). Pour l'ensemble de la période d'observation, les cinq premières langues étaient le français, l'arabe, l'espagnol, le pendjabi et le mandarin, représentant 69,2 % de l'ensemble des minutes d'interprétation. Parmi les cinq langues les plus demandées, le temps d'interprétation médian varie de 7 minutes (français) à 13,5 minutes (arabe), avec EI allant de 4 minutes (français) à 25 minutes (arabe).
| Langue | Nombre d'entretiens | Minutes cumulées | Médiane (EI) |
|---|---|---|---|
| Akan | 2 | 15 | 7,5 (6,8–8,3) |
| Albanais | 14 | 222 | 8,0 (4,3–16,8) |
| Amharique | 3 | 43 | 16,0 (9,5–20,0) |
| Arabe | 370 | 6 642 | 13,5 (7,0–25,0) |
| Bengali | 3 | 49 | 20,0 (10,5–24,0) |
| Cantonais | 73 | 1 166 | 13,0 (5,0–23,0) |
| Croate | 4 | 78 | 22,0 (12,3–29,3) |
| Tchèque | 2 | 43 | 21,5 (20,8–22,3) |
| Dari | 11 | 213 | 19,0 (11,0–23,0) |
| Estonien | 1 | 5 | s.o. |
| Farsi | 41 | 528 | 8,0 (5,0–17,0) |
| Français | 803 | 9 203 | 7,0 (4,0–16,0) |
| Allemand | 30 | 175 | 6,0 (4,0–7,8) |
| Grec | 4 | 80 | 20,5 (9,3–31,3) |
| Gujarati | 2 | 8 | s.o. |
| Hindi | 53 | 768 | 10,0 (4,0–20,0) |
| Hongrois | 9 | 132 | 7,0 (5,0–15,0) |
| Indonésien | 2 | 54 | 27,0 (22,5–31,5) |
| Italien | 27 | 322 | 10,0 (6,0–15,5) |
| Japonais | 3 | 21 | 5,0 (5,0–8,0) |
| Karen | 2 | 53 | 26,5 (19,3–33,8) |
| Khmer | 1 | 18 | s.o. |
| Coréen | 24 | 456 | 15,5 (6,3–31,3) |
| Laotien | 2 | 13 | 6,5 (4,8–8,3) |
| Mandarin | 133 | 2 146 | 9,0 (5,0–20,0) |
| Népalais | 5 | 90 | 18,0 (15,0–21,0) |
| Pashto | 1 | 11 | s.o. |
| Polonais | 25 | 497 | 20,0 (10,0–24,0) |
| Portugais | 51 | 968 | 16,0 (7,5–25,5) |
| Pendjabi | 221 | 3 657 | 10,0 (5,0–22,0) |
| Rohingya | 3 | 15 | 2 (1,5–7,0) |
| Roumain | 1 | 69 | s.o. |
| Russe | 10 | 167 | 14 (5,0–19,5) |
| Serbe | 12 | 221 | 15 (11,3–25,0) |
| Shanghaïen | 1 | 10 | s.o. |
| Somali | 27 | 379 | 9,0 (5,0–22,0) |
| Sorani | 3 | 14 | 5 (4,0–5,5) |
| Espagnol | 316 | 5 009 | 13 (5,0–23,0) |
| Arabe soudanais | 2 | 53 | 26,5 (18,3–34,8) |
| Swahili | 5 | 35 | 4,0 (4,0–12,0) |
| Tagalog | 11 | 165 | 6,0 (5,0–24,0) |
| Taïwanais | 1 | 5 | s.o. |
| Tamoul | 62 | 915 | 9,0 (5,0–23,0) |
| Telugu | 2 | 9 | 4,5 (4,3–4,8) |
| Thaïlande | 16 | 409 | 17,0 (13,8–24,5) |
| Tigrigna/Tigrinya | 42 | 810 | 12,5 (7,0–25,8) |
| Turc | 14 | 168 | 12,5 (5,3–14,8) |
| Ukrainien | 10 | 163 | 16,0 (11,8–18,3) |
| Urdu | 38 | 434 | 7,0 (4,0–14,8) |
| Vietnamien | 106 | 1 792 | 12,5 (4,0–23,0) |
| Total | 2 604 | 38 518 | 10,0 (5,0–20,0) |
Abréviations : EI, intervalle interquartile; s.o., sans objet |
|||
Nous avons constaté que l'évolution globale des minutes d'interprétation linguistique correspondait à l'évolution du volume de contacts soumis à l'Initiative, à quelques exceptions près (figure 1). Par exemple, il y a eu des périodes où le nombre de minutes d'interprétation était élevé par rapport aux contacts soumis, y compris la période de janvier à juillet 2021.
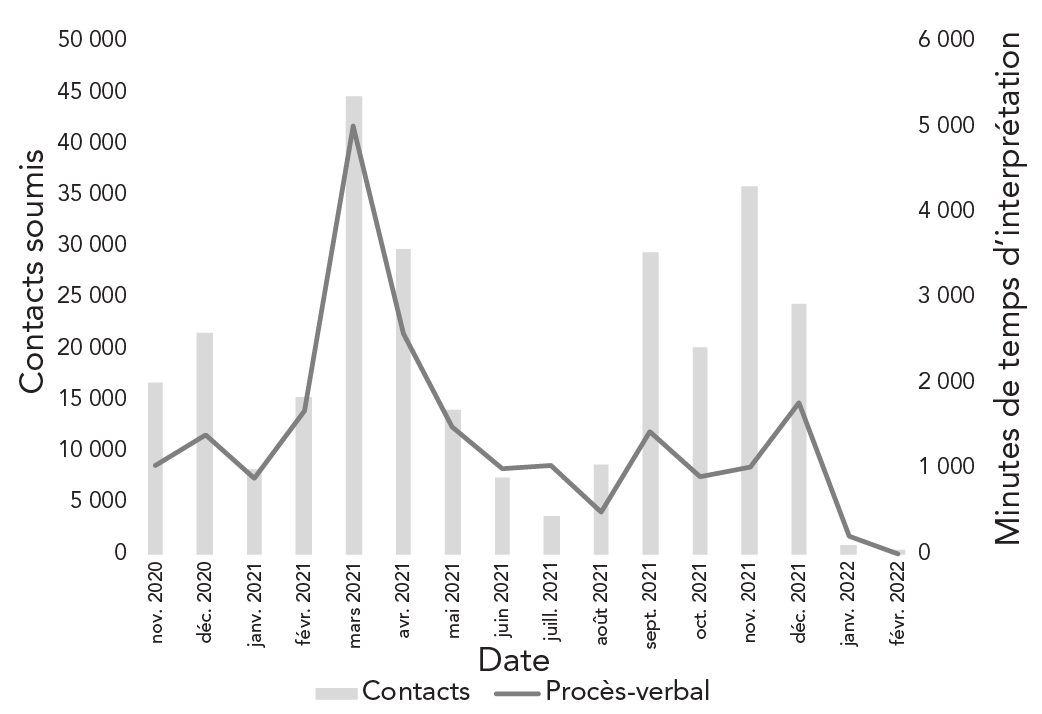
Figure 1 : Description textuelle
Le graphique montre le nombre de contacts étroits à haut risque soumis à l'Initiative de recherche des contacts de Santé publique Ontario, ainsi que le nombre de minutes de services d'interprétation documentés pour le programme de novembre 2020 à février 2022. Le nombre de contacts soumis au programme a commencé à 16 722 en novembre 2020 et a culminé à 44 465 en mars 2021. En novembre 2020, 1 042 minutes de services d'interprétation ont été enregistrées, avec un pic de 5 022 en mars 2021. Dans l'ensemble, les fluctuations du volume des minutes d'interprétation correspondent à l'évolution du nombre de contacts soumis au programme. Entre janvier 2021 et juillet 2021, le volume de demandes d'interprétation linguistique (en minutes) a été élevé par rapport au volume de contacts soumis au programme.
Nous avons examiné les tendances temporelles afin d'évaluer l'évolution des langues les plus demandées pour les services d'interprétation au cours de la période d'observation. Nous avons déterminé quatre périodes d'intérêt pour faire l'objet d'un examen plus approfondi.
Observation 1 : En septembre 2020, les demandes d'interprétation en français ont augmenté (figure 2). Les BSP locaux suivants ont soumis environ 94 % des contacts à l'Initiative au cours de ce mois (nombre de contacts) : Ottawa (n = 1 204), Halton (n = 710), Durham (n = 666), York (n = 509) et Niagara (n = 346) (tableau 1) (données complémentaires disponibles auprès de l'auteur correspondant). Selon le recensement canadien de 2021, le français était la langue autre que l'anglais la plus souvent parlée à la maison à Ottawa, représentant environ 40 % de toutes les langues autres que l'anglais déclarées (données supplémentaires disponibles auprès de l'auteur correspondant).
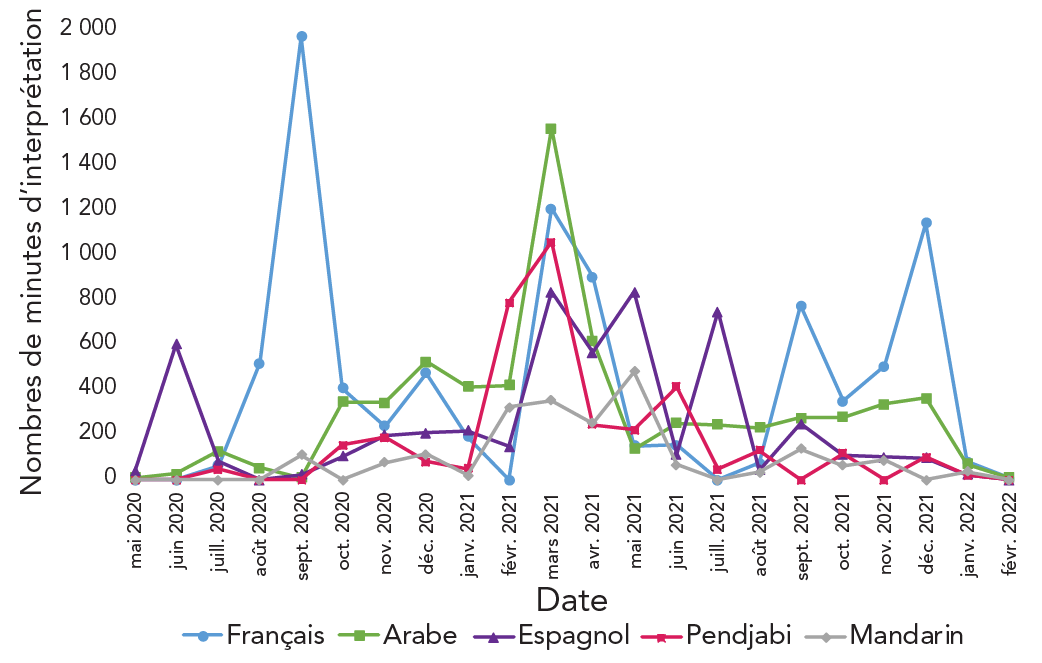
Figure 2 : Description textuelle
Le graphique montre le nombre de minutes d'interprétation pour les cinq langues les plus demandées, à savoir le français, l'arabe, l'espagnol, le pendjabi et le mandarin. Le nombre de minutes d'interprétation pour le français a atteint son maximum en septembre 2020 avec 2 111 minutes. Le nombre de minutes d'interprétation pour le mandarin a atteint son maximum en mai 2021, avec 480 minutes. Le nombre de minutes d'interprétation pour les autres langues a atteint son maximum en mars 2021, avec notamment 1 565 minutes pour l'arabe, 836 pour l'espagnol et 1 059 pour le pendjabi. La figure montre également l'évolution dans le temps de la langue prédominante dans les demandes d'interprétation, le français étant la langue la plus courante entre juillet 2020 et octobre 2020 et entre septembre 2021 et janvier 2022. L'arabe est devenu la langue la plus demandée en mars 2021. L'espagnol était la langue la plus demandée en juin 2020 et entre mai 2021 et juillet 2021.
Observation 2 : L'arabe était la langue la plus demandée pour l'interprétation entre novembre 2020 et mars 2021 (figure 2). Les BSP suivants ont soumis environ 60 % des contacts en mars 2021 (nombre de contacts) : Durham (n = 6 325), Peel (n = 5 804), Sudbury & Districts (n = 4 890), Halton (n = 4 059), Hamilton (n = 2 657) et Niagara (n = 2 452) (données complémentaires disponibles auprès de l'auteur correspondant). Peel avait le pourcentage le plus élevé de personnes déclarant une langue non officielle parlée à la maison (33 %) selon le recensement de 2021 (données supplémentaires disponibles auprès de l'auteur correspondant). Le pendjabi était la langue la plus couramment parlée à la maison dans cette région (32 %), l'arabe arrivant en troisième position (5,3 %) (données complémentaires disponibles auprès de l'auteur correspondant).
Observation 3 : Au début du printemps 2020 (mai 2020) et entre mars et juillet 2021, on a observé une augmentation des demandes d'interprétation linguistique pour l'espagnol (figure 2), cette langue devenant prédominante au cours de la période printemps-été, lorsque les BSP de Waterloo, Peel, Halton et Grey Bruce ont continué à soumettre des volumes élevés de contacts (données complémentaires disponibles auprès de l'auteur correspondant). Les régions de Halton et de Waterloo ont également soumis un grand nombre de contacts en mai 2020 (données supplémentaires disponibles auprès de l'auteur correspondant). Nous avons noté que l'espagnol ne figurait pas parmi les trois langues non officielles les plus parlées à la maison dans ces régions, selon le recensement de 2021.
Observation 4 : Au cours des derniers mois du programme (septembre 2021 à décembre 2021), le français est devenu la principale langue demandée pour l'interprétation (figure 2). Ceci pourrait être attribué à l'augmentation soudaine des soumissions provenant de l'Est de l'Ontario et de Sudbury & Districts (données supplémentaires disponibles auprès de l'auteur correspondant). Ces BSP ont une grande proportion de la population qui parle le plus souvent le français à la maison (données complémentaires disponibles auprès de l'auteur correspondant). Les Bureaux de santé publique qui ont soumis un grand nombre de contacts au cours de ces quatre mois sont les suivantes (nombre de contacts) : Durham (n = 18 146), Waterloo (n = 15 150), Niagara (n = 12 363), Sudbury & Districts (n = 8 236), Peel (n = 6 437) et l'Est de l'Ontario (n = 6 159) (données complémentaires disponibles auprès de l'auteur correspondant).
Discussion
Les interprètes ont fourni plus de 38 500 minutes de services d'interprétation dans 50 langues pour l'Initiative. Certains changements dans la prédominance des langues peuvent s'expliquer par les changements dans les BSP locaux qui soumettaient un grand nombre de contacts à l'initiative et les profils linguistiques associés de ces communautés.
Il y a eu deux périodes au cours desquelles les tendances des demandes d'interprétation linguistique n'ont pas pu être expliquées en examinant les unités de santé à l'origine des demandes et les profils linguistiques de leur communauté. La prédominance des demandes d'interprétation en arabe est un résultat intéressant qui pourrait représenter l'impact disproportionné de la pandémie de COVID-19 sur les communautés arabophones. Cette observation est cohérente avec les résultats d'une analyse des données raciales collectées par les BSP de l'Ontario, où les communautés du Moyen-Orient présentaient des taux bruts d'infection par la COVID-19 par habitant disproportionnellement élevés Note de bas de page 9.
L'augmentation des demandes d'interprétation en espagnol est un autre résultat intéressant, car l'espagnol ne figure pas parmi les trois langues non officielles les plus souvent parlées à la maison dans les régions des unités de santé à l'origine des demandes. Cette observation est conforme aux résultats de l'analyse des données raciales recueillies par les BSP de l'Ontario, où les communautés latino-américaines de l'Ontario ont connu les taux bruts d'infection par la COVID-19 les plus élevés par habitant en Ontario Note de bas de page 9. En l'absence de collecte systématique de données fondées sur la race, le manque de concordance entre les demandes d'interprétation linguistique et le profil linguistique d'une communauté pourrait donner lieu à une enquête plus approfondie afin d'identifier d'éventuels impacts disproportionnés de la maladie auxquels il conviendrait de remédier.
Nos travaux montrent qu'il existe une extrême variabilité entre les durées moyennes des entretiens d'interprétation. L'interprétation est plus qu'une traduction directe. Il est nécessaire d'intégrer les contextes culturels et les caractéristiques uniques de la langue cible dans les scripts rédigés en anglais. Nous pensons qu'il s'agit d'un domaine d'étude important pour l'avenir, avec des possibilités de continuer à développer des travaux visant à améliorer la technologie et la formation pour une communication efficace médiée par un interprète.
Points forts et limites
Les principaux points forts de cette étude sont l'utilisation inédite de données administratives pour comprendre les besoins en communication dans le domaine de la santé publique et l'exhaustivité de l'ensemble des données couvrant toute la durée du programme. Les données disponibles pour cette analyse exploratoire présentent d'importantes limites et mises en garde dont nous avons pris note. Les entretiens individuels ont pu concerner des appels à des ménages comprenant une ou plusieurs personnes ou un intermédiaire (e.g., un parent pour un enfant); nous n'avons donc pas pu identifier le nombre de contacts uniques.
Il s'agit également d'une étude descriptive exploratoire dont les limites sont liées à la possibilité de contrôler les facteurs de confusion potentiels. Les contacts soutenus par l'Initiative sont un sous-ensemble de contacts à haut risque en Ontario qui ont été soumis par les BSP sur la base des critères du programme, qui ont changé au fil du temps en réponse aux besoins des BSP et aux orientations de la politique provinciale. L'image des besoins en interprétation sera moins précise pendant les périodes où le volume de cas de COVID-19 était élevé, lorsque certaines activités de gestion des cas et des contacts ont été modifiées pour donner la priorité à d'autres activités de réponse à la COVID-19.
L'utilisation des données de facturation administrative pour les demandes de services d'interprétation auprès d'un fournisseur externe peut ne pas tenir compte de tous les besoins en matière d'interprétation linguistique. Le besoin de services d'interprétation n'a pas toujours été demandé par le contact ou reconnu par l'interviewer. L'efficacité de la formation sur l'accès aux services d'interprétation et la cohérence avec laquelle ces services ont été recommandés par les interviewers n'ont pas été évaluées. Il est important de mieux comprendre les obstacles à une communication efficace et d'autres facteurs, y compris les préférences culturelles, afin de continuer à améliorer les services linguistiques et la diffusion globale des informations de santé publique.
Conclusion
Les agences de santé publique pourraient tirer profit de l'utilisation des sources de données secondaires existantes pour comprendre les besoins de leurs communautés en matière d'interprétation linguistique. Cette étude a également montré comment les sources de données existantes pouvaient être utilisées pour aider à évaluer comment les communautés sont affectées de manière disproportionnée par les urgences de santé publique.
Déclaration des auteurs
- A. C. — Méthodologie, analyse formelle, interprétation, rédaction de la version originale, rédaction–révision et édition
- M. A. C. — Méthodologie, interprétation, rédaction–révision et édition
- J. P. H. — Conceptualisation, méthodologie, interprétation, rédaction–révision et édition
Le contenu de cet article et les opinions qui y sont exprimées n'engagent que les auteurs et ne reflètent pas nécessairement ceux du gouvernement du Canada.
Intérêts concurrents
Aucun.
Remerciements
Les auteurs souhaitent remercier Justin Thielman et Celina Degano pour leur soutien lors de l'analyse et pour avoir fourni des informations sur l'Initiative de recherche des contacts.
Financement
Ce travail a été soutenu par Santé publique Ontario.
Références
- Notes de bas de page 1
-
Organisation mondiale de la Santé. Recherche des contacts dans le cadre de la COVID-19 : orientations provisoires, 1er février 2021. Genève, CH : OMS; 2021. [Consulté le 6 août 2024]. https://iris.who.int/handle/10665/339599
- Notes de bas de page 2
-
Maleki P, Al Mudaris M, Oo KK, Dawson-Hahn E. Training contact tracers for populations with limited English proficiency during the COVID-19 pandemic. Am J Public Health 2021;111(1):20–4. https://doi.org/10.2105/AJPH.2020.306029
- Notes de bas de page 3
-
Lu L, Anderson B, Ha R, D’Agostino A, Rudman SL, Ouyang D, Ho DE. A language-matching model to improve equity and efficiency of COVID-19 contact tracing. Proc Natl Acad Sci 2021;118(43):e2109443118. https://doi.org/10.1073/pnas.2109443118
- Notes de bas de page 4
-
Eliaz A, Blair AH, Chen YH, Fernandez A, Ernst A, Mirjahangir J, Celentano J, Sachdev D, Enanoria W, Reid MJA. Evaluating the impact of language concordance on coronavirus disease 2019 contact tracing outcomes among Spanish-speaking adults in San Francisco between June and November 2020. Open Forum Infect Dis 2022;9(1):ofab612. https://doi.org/10.1093/ofid/ofab612
- Notes de bas de page 5
-
Ariste R, di Matteo L. Non-Official Language Concordance in Urban Canadian Medical Practice: Implications for Care during the COVID-19 Pandemic. Healthc Policy 2021;16(4):84–96. https://doi.org/10.12927/hcpol.2021.26497
- Notes de bas de page 6
-
Guttmann A, Gandhi S, Wanigaratne S, Lu H, Ferriera-Legere LE, Paul J, Gozdyra P, Campbell T, Chung H, Fung K, Chen B, Kwong JC, Rosella L, Shah BR, Saunders N, Paterson JM, Bronskill SE, Azimaee M, Vermeulen MJ, Schull MJ. COVID-19 in Immigrants, Refugees and Other Newcomers in Ontario: Characteristics of Those Tested and Those Confirmed Positive, as of June 13, 2020. ICES; 2020. [Consulté le 6 août 2024]. https://www.ices.on.ca/Publications/Atlases-and-Reports/2020/COVID-19-in-Immigrants-Refugees-and-Other-Newcomers-in-Ontario
- Notes de bas de page 7
-
Statistique Canada. Alors que le français et l’anglais demeurent les principales langues parlées au Canada, la diversité linguistique continue de s’accroître au pays. Ottawa, ON : StatCan; 2022. [Consulté le 6 août 2024]. https://www150.statcan.gc.ca/n1/daily-quotidien/220817/dq220817a-fra.htm
- Notes de bas de page 8
-
Rajkumar E, Rajan AM, Daniel M, Lakshmi R, John R, George AJ, Abraham J, Varghese J. The psychological impact of quarantine due to COVID-19: A systematic review of risk, protective factors and interventions using socio-ecological model framework. Heliyon 2022;8(6):e09765. https://doi.org/10.1016/j.heliyon.2022.e09765
- Notes de bas de page 9
-
McKenzie K, Dube S, Petersen S. Tracking COVID-19 through race-based data. Toronto, ON: Wellesley Institute & Ontario Health; 2021. [Consulté le 6 août 2024]. https://www.wellesleyinstitute.com/wp-content/uploads/2021/08/Tracking-COVID-19-Through-Race-Based-Data_eng.pdf
- Notes de bas de page 10
-
Chambers A, Quirk J, MacIntyre EA, Bodkin A, Hanson H. Lessons learned from implementing a surge capacity support program for COVID-19 contact management in Ontario. Can J Public Health 2023;114(4):555–62. https://doi.org/10.17269/s41997-023-00773-6
- Notes de bas de page 11
-
Statistique Canada. Profil du recensement, Recensement de la population de 2021. Ottawa, ON : StatCan; 2022. [Consulté le 6 août 2024]. https://www12.statcan.gc.ca/census-recensement/2021/dp-pd/prof/index.cfm?Lang=F

Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International