
Maladies chroniques et blessures au Canada
Volume 32, no. 1, décembre 2011
Maladies chroniques et blessures au Canada
Naviguez cet article
Vérification de la qualité de la base de données périnatales Niday pour 2008 : rapport sur un projet d’assurance de la qualité
S. Dunn, Ph. D. (1,2); J. Bottomley, M.G.S.S. (3); A. Ali, M. Sc. (4); M. Walker, M.D. (1,5,6,7)
https://doi.org/10.24095/hpcdp.32.1.05f
Cet article a fait l’objet d’une évaluation par les pairs.
Rattachement des auteurs :
- Better Outcomes Registry and Network (BORN Ontario), Ottawa (Ontario), Canada
- Programme régional des soins au nouveau-né et à la mère de Champlain (CMNRP), Ottawa (Ontario), Canada
- Centre hospitalier pour enfants de l’est de l’Ontario, Ottawa (Ontario), Canada
- Santé publique Ottawa, Ottawa (Ontario), Canada
- Groupe de recherche OMNI, Programme d’épidémiologie clinique, Institut de recherche en santé d’Ottawa, Ottawa (Ontario), Canada
- Division de la médecine maternelle et fœtale, Département d’obstétrique et de gynécologie, Faculté de médecine, Hôpital général d’Ottawa, Université d’Ottawa, Ottawa (Ontario), Canada
- Chaire de recherche du Canada de niveau 1, Épidémiologie périnatale, Université d’Ottawa, Ottawa (Ontario), Canada
Correspondance : Sandra Dunn, BORN Ontario, Hôpital d’Ottawa, 501, chemin Smyth, pièce 1818, case 241, Ottawa (Ontario) K1H 8L6; tél. : 613-737-8899, poste 72070; courriel : sadunn@ohri.ca
Résumé
Introduction : Le présent projet d’assurance qualité vise à déterminer la fiabilité, l’intégralité et l’exhaustivité des données saisies dans la base de données périnatales Niday.
Méthodologie : La qualité des données a été mesurée en comparant les données réextraites des dossiers des patients aux données entrées à l’origine dans la base de données périnatales Niday. Un échantillon représentatif des hôpitaux de l’Ontario a été sélectionné et un échantillon aléatoire de 100 dossiers mère-enfant appariés a été vérifié pour chaque site. Un sous-ensemble de 33 variables (représentant 96 champs de données) de la base Niday a été choisi pour la réextraction.
Résultats : Parmi les champs de données pour lesquels le coefficient Kappa de Cohen ou le coefficient de corrélation intraclasse (CCI) a été calculé, 44 % présentaient une concordance excellente ou presque parfaite (au-delà de ce qui pourrait être imputé au hasard). Cependant, environ 17 % d’entre eux ont affiché une concordance inférieure à 95 % et un coefficient Kappa ou un CCI de moins de 60 %, signe d’une concordance presque nulle, médiocre ou modérée (au-delà de ce qui pourrait être imputé au hasard).
Analyse : L’article présente des recommandations pour améliorer la qualité de ces champs de données.
Mots-clés : vérification, qualité des données, assurance qualité, fiabilité
Contexte
Le ministère de la Santé et des Soins de longue durée (MSSLD) de l’Ontario a reconnu que l’efficacité et l’efficience d’un système de santé reposent sur la production et le maintien de données de surveillance de qualité1. La surveillance est définie comme étant la collecte, l’analyse et l’interprétation systématiques et continues des données de santé essentielles à la planification, à la mise en œuvre et à l’évaluation des pratiques de santé publique, combinées à la diffusion en temps opportun de ces données aux principales parties intéressées2. Un système de surveillance peut servir à la fois d’outil de mesure et d’incitatif à l’action3 en fonctionnant comme un mécanisme d’alerte précoce face aux problèmes de santé et en fournissant des données probantes pour l’élaboration des politiques et des programmes, l’évaluation des risques, l’analyse des tendances et l’évaluation des stratégies de prévention et de lutte4. L’utilité d’un système de surveillance reste cependant limitée par la qualité des données qu’il recueille et analyse.
En Ontario, la base de données périnatales Niday (la « base Niday ») regroupe les données servant à évaluer les résultats, les facteurs de risque et les interventions dans le domaine des soins périnataux. Elle a été créée en 1997 sous les auspices du Programme de partenariat périnatal de l’Est et du Sud-Est de l’Ontario (PPPESO) pour fournir des données périnatales aux partenaires du Programme. Ce système, accessible sur Internet, a beaucoup évolué depuis ses débuts, pour devenir une initiative collaborative exceptionnelle, regroupant une centaine d’organisations de soins de santé de la province l’alimentant en données périnatales en temps réel. Il permet aux fournisseurs de soins de santé des différentes régions de la province et des différents secteurs de services de mieux collaborer pour améliorer la santé périnatale. Au moment de notre vérification, 96 % des naissances en Ontario étaient inscrites dans la base Niday, et celle-ci contenait 90 éléments de données sur des patients couvrant l’éventail complet de la santé périnatale (tableau 1). En 2001, la province a choisi d’utiliser les variables incluses dans la base Niday comme ensemble minimal de données.
Tableau 1. Liste des variables de la base de données périnatales Niday de 2008 (n = 90), spécifiant les variables choisies pour la réextraction dans le cadre de la vérification de la qualité de 2008
Données couplées
Variables d’identification
Variables liées aux antécédents de la mère
- Raison du transfert, le cas échéantc
- Fournisseur des soins prénatauxc
- Examen du premier trimestrec
- Cours prénatauxc
- Statut tabagique
- Intention d’allaiterd
- Nombre d’autres enfants nés à terme
- Nombre d’autres enfants nés prématurément
- Procréation assistéec
- Grossesse multiple
- Observations sur les antécédents de la mèred
Variables liées au travail et à la naissance
- Type de travail
- S’il y a eu induction, motif (17)
- S’il y a eu induction, méthode (8)
- Nombre de tentatives d’inductionc
- Augmentationd
- Complications intrapartumc
- Soulagement de la douleur de la mère (11)
- Monitorage fœtal (6)
- Antibiothérapie SGBd
- Corticothérapie anténatale
- Observations sur le travail et la naissanced
- Forceps/ventouses
Variables liées au nouveau-né
- Réanimation postnatale (7)
- Sexe de l’enfant
- Âge gestationnel
- Poids à la naissance
- Indice d’Apgar à 1 min
- Indice d’Apgar à 5 min
- Indice d’Apgar à 10 minc
- Type d’allaitement à l’hôpitalc
- Raison du remplacement dulait maternelc
- Type d’allaitement au moment du congéc
- Dépistage auditifc
- Dépistage BSESc
- Raison de la non-transmission des résultats du dépistage BSES, le cas échéantc
- pH artériel au cordonc
- Excès de bases, sang artérielc
- pH veineux au cordonc
- Excès de bases, sang veineuxc
- Anomalies congénitalesc
- Photothérapiec
- Observations sur le nouveau-néd
- Décès néonatal/mortinaissance
- Date du congé/transfert néonatalc
- Heure du congé/transfert néonatald
- Poids au moment du congéc
- Congé/transfert àc
- Raison du transfert néonatalc
- Hôpital de transfert néonatal
Champs des variables définies par l’usagere
- No d’identité de l’infirmière à la naissance
- No d’identité du médecin présent à la naissance
- Heure du congé
- Date d’admission de la mère
- Heure d’admission de la mère
- Taille de la mère (centimètres)
- Délivrance du placenta
- Poids de la mère (kilogrammes)
- Dépistage de drogues chez le nouveau-né
- Résultats du dépistage de drogues chez le nouveau-né
Abréviations : SGB, streptocoque du groupe B; BSES, Bébés en santé, enfants en santé.
Notes :
Nombre total de variables de la base de données périnatales Niday en 2008 (n = 90) : 24 obligatoires et 66 non obligatoires.
Nombre total de variables incluses dans la réextraction (n = 33/90, soit 36,7 % et 96 champs de données à vérifier) : 20 variables obligatoires (4 fourniesb) et 13 variables non obligatoires
- Variables obligatoires – données couplées (n = 4/90, soit 4,4 %)
- Étiquettes d’identification fournies
- Plus de 10 % de données manquantes (n = 31/90, soit 34,4 %)
- Non identifiée comme étant prioritaire au moment de la vérification (n = 12/90, soit 13,3 %)
- Variables définies par l’usager (n = 10/90, soit 11,1 %) – Option offerte dans certains sites seulement
Il s’agit de la seule base de données de l’Ontario offrant un accès immédiat en temps réel aux données périnatales sur la population de l’ensemble d’une région. Le projet est désormais géré par le comité directeur du réseau BORN (Better Outcomes Registry and Network). Comme la plupart des hôpitaux de la province participent au projet, il devient possible d’effectuer des comparaisons entre hôpitaux et entre unités de soins pour établir des critères de référence et d’améliorer les performances en tirant parti des réussites des partenaires. Le réseau BORN a pour objectif de fournir des données de qualité et des outils de déclaration puissants et efficaces tout au long de son évolution5.
Comme environ 40 % des naissances vivantes au Canada se produisent en Ontario (37,1 % en 2008-2009)6, la base de données Niday fournit de précieux renseignements périnataux sur une large proportion des naissances survenant au Canada. Bien qu’il soit établi que l’efficacité et l’efficience d’un système de santé reposent sur la production de données de qualité1, on ignorait si la base Niday, dans sa configuration actuelle, était une source d’information fiable. Ce projet d’assurance qualité visait donc à évaluer objectivement la fiabilité, l’intégralité et l’exhaustivité des données contenues dans la base de données périnatales Niday.
Méthodologie
Nous nous sommes fondés sur le Cadre de gestion de la qualité des données7, mis au point par l’Équipe des résultats dans le domaine de la santé pour la gestion de l’information du MSSLD, pour orienter le projet. Conformément à l’énoncé de politique des trois Conseils, et compte tenu du fait qu’il s’agissait d’un projet d’assurance qualité, l’approbation du Comité d’éthique de la recherche n’était pas obligatoire8. Les hôpitaux participaient au projet sur une base volontaire, et tout a été mis en œuvre pour assurer la confidentialité de l’information sur les patients et le respect de la confidentialité des hôpitaux participants.
Réextraction des données
Afin de déterminer la fiabilité et l’intégralité des données, on a effectué une réextraction de l’information contenue dans les dossiers des patients et on a évalué la concordance entre certaines variables de la base de données périnatales et les dossiers des mères et des enfants. Un consentement écrit a été demandé et obtenu auprès de chaque site participant à la phase de réextraction du projet. L’information a été traitée en toute confidentialité, et chaque vérificateur a signé une promesse de non-divulgation. Les vérificateurs ont saisi de nouveau les données des dossiers des patients qui avaient déjà été recueillies et entrées dans la base Niday par le personnel de saisie des données de l’hôpital. Des ordinateurs portables ont été prêtés aux vérificateurs pour la saisie des données, et ceux-ci les ont retournés une fois le processus de réextraction terminé. Les données électroniques ont ensuite été transférées en toute sécurité au statisticien aux fins d’analyse, puis supprimées de l’ordinateur portable. Les données ont été regroupées pour l’analyse, et les conclusions ont été rendues anonymes.
Sites et taille de l’échantillon (hôpitaux)
Nous avons procédé par échantillonnage dirigé pour recruter 14 hôpitaux représentatifs des cinq régions suivantes de la province : Est/Sud-Est, région du Grand Toronto (RGT), Centre-Ouest, Sud-Ouest et Nord. L’échantillonnage portait sur les pratiques obstétricales et néonatales et incluait tous les niveaux de soins : niveau 1, ou grossesses à faible risque (4 hôpitaux ontariens sur 51), niveau 2, ou femmes ou fœtus avec problèmes de santé (8 hôpitaux ontariens sur 37), niveau 3, ou soins spécialisés (2 hôpitaux ontariens sur 7). Les hôpitaux recrutés utilisaient une combinaison de systèmes de documentation papier et électroniques et avaient recours à divers processus pour la saisie des données.
Taille de l’échantillon
Un échantillon aléatoire de 100 numéros de dossier de mères (reliés aux dossiers des nouveau-nés) a été généré par ordinateur pour chaque site participant à partir des dossiers existants déjà saisis dans la base Niday en 2008 (soit un total de 200 dossiers par site). La taille de l’échantillon total de ce projet était de 1 395 dyades mère-nouveau-né appariées; il est à noter que trois dossiers de patientes n’ont pu être localisés à l’étape de la réextraction et que deux numéros de dossier ne correspondaient pas à une patiente en périnatalité.
Variables visées par la réextraction
Un sous-ensemble de variables (33/90; 36,7 %) de la base de données périnatales Niday a été choisi pour la procédure de réextraction. La sélection se fondait sur les critères suivants : a) une variable obligatoire; b) une variable non obligatoire avec moins de 10 % de données manquantes d’après les rapports de vérification antérieurs et c) une variable concernant une pratique d’intérêt (p. ex. corticothérapie prénatale, indication de césarienne, épisiotomie, déchirures, monitorage fœtal, forceps/ventouse, indication d’induction, méthode d’induction, soulagement de la douleur de la mère, statut tabagique). Au total, 96 champs de données pouvaient faire l’objet d’une réextraction, certaines des variables comportant plusieurs champs de données (par exemple, l’indication d’induction comprenait 17 champs de données et le soulagement de la douleur de la mère en englobait 11). Le tableau 1 présente les variables sélectionnées pour la réextraction et celles qui ont été exclues (avec le motif d’exclusion).
Vérificateurs
En raison de la grande dispersion géographique des hôpitaux participants ainsi que des déplacements et du temps nécessaires pour effectuer la vérification dans les 14 sites, nous avons embauché et formé six vérificateurs détenant une connaissance des soins de santé pour accélérer le processus. Deux vérificateurs ont chacun saisi les données dans cinq sites, et chacun des quatre autres vérificateurs a extrait les données d’un site. La figure 1 présente un schéma du processus de collecte des données.
Figure 1. Le processus de collecte des données
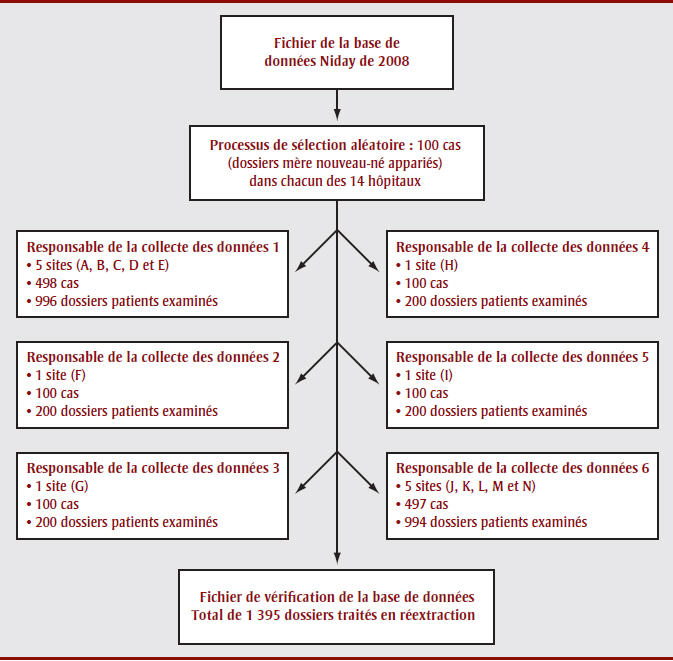
Équivalent texte de la Figure 1 - Le processus de collecte des données
Deux vérificateurs ont chacun saisi les données dans cinq sites, et chacun des quatre autres vérificateurs a extrait les données d’un site. La figure 1 présente un schéma du processus de collecte des données. Les données manquantes (non saisies) ont également été évaluées dans le cadre de la réextraction et se sont révélées être associées aux variables suivantes : corticothérapie prénatale, forceps/ventouse, épisiotomie, déchirures et statut tabagique. Les données manquantes ne se retrouvaient que dans trois sites (F, J et K; voir figure 1).
Chacun des vérificateurs a été informé de la teneur du projet et a reçu une formation sur le processus de réextraction, comprenant entre autres le repérage de l’information dans les dossiers des patients et l’utilisation du tableur SPSS* pour la collecte des données afin d’assurer l’uniformité du processus de réextraction. Chacun d’eux a reçu un document contenant la définition des termes associés à chacune des variables de la base Niday, les coordonnées de la personne chargée de coordonner le projet, une liste du ou des hôpitaux qui leur avaient été attribués et une feuille de calcul SPSS contenant des données d’échantillon présaisies (numéro de dossier de la mère, numéro de dossier de l’enfant, date de naissance de l’enfant) pour chacun des sites qui leur avaient été attribués. Pour s’exercer, les vérificateurs ont chacun entré les données dans le tableur SPSS à partir des mêmes deux dossiers; la fiabilité entre les évaluateurs a été établie à partir de ces cas.
* Progiciel d’analyse statistique en sciences sociales, version 15.
Procédure de collecte des données
Après le processus de sélection aléatoire des dossiers, nous avons dressé une liste des dossiers des patients pour chacun des hôpitaux participants. Le numéro de dossier de la mère et le numéro de dossier de l’enfant ont servi de variables d’identification. Pour plus de précision, la date de naissance de chaque enfant a été imprimée afin que les vérificateurs puissent vérifier que le dossier traité était le bon. Dans chacun des 14 hôpitaux participants, une personne-ressource a été identifiée et informée du projet par le gestionnaire de projet. Cette personne a été invitée à faciliter (ou à désigner quelqu’un pour le faire) l’entrée des vérificateurs sur le site, leur accès aux dossiers des patients dans les archives médicales et la résolution de toute autre question relative au site. Avant la collecte des données, la personne-ressource (ou la personne désignée par celle-ci) a rencontré le vérificateur pour lui expliquer le fonctionnement des systèmes de gestion de la documentation sur les patients et lui dire où trouver l’information recherchée.
La première extraction des données s’est déroulée d’avril à juillet 2008. Il a fallu reprendre la collecte des données dans un site en octobre 2008, car le fichier de la première extraction avait été écrasé et les données qu’il contenait avaient donc été perdues.
Les dossiers (papier ou électroniques) ont été obtenus auprès du service des archives médicales de chacun des hôpitaux participants. Les vérificateurs ont lu les dossiers et extrait les données en utilisant les procédures convenues pour l’entrée des données. La collecte des données a été effectuée au moyen d’un modèle de fichier de données SPSS. Une feuille de calcul a été créée avec les champs de données à l’étude et les menus déroulants correspondant à ceux qui figurent sur l’écran de saisie de la base Niday. Pour faciliter la saisie des données, les variables ont été placées dans le même ordre que celui dans lequel elles apparaissent dans la majorité des dossiers d’hôpital. Les données ont été saisies dans deux ordinateurs portables. La procédure de réextraction a pris de deux à quatre jours par site, en raison des délais habituels d’accès aux dossiers des patients et du temps requis pour passer à travers l’information contenue dans chaque dossier patient. S’ils avaient des questions durant le processus de réextraction, les vérificateurs pouvaient communiquer avec le gestionnaire de projet par téléavertisseur, téléphone ou courriel.
Dossiers des patients
Bien que les systèmes de gestion de la documentation sur les patients diffèrent dans l’ensemble de la province, l’examen des dossiers a été mené le plus uniformément possible. Les vérificateurs avaient été formés pour obtenir l’information auprès des sources utilisées lors de la saisie originale des données. Le code postal, l’âge de la mère et les données sur le transfert de la mère en provenance d’un autre hôpital ont été obtenus à partir du dossier d’admission; les autres variables ont été tirées du dossier de travail, du dossier d’accouchement, du dossier prénatal, du sommaire de congé, des résultats de laboratoire, des notes des infirmières, des prescriptions des médecins, des fiches des médicaments administrés et du registre de dépistage post-partum. Le vocabulaire et la structure des dossiers des patients variaient d’un site à l’autre, mais la disposition générale de l’information était similaire. Dans une région, un système de documentation uniformisé était en usage dans tous les hôpitaux participants, sauf un. Les dossiers étaient rédigés soit en anglais, soit en anglais/français.
Traitement des données
Les données statistiques (fréquences, moyennes et pourcentages) utilisées pour décrire les caractéristiques des groupes de l’échantillon ont été calculées à l’aide de la version 15 du progiciel SPSS. La fiabilité des données a été évaluée en comparant les données réextraites du dossier du patient aux données d’origine entrées dans la base de données périnatales Niday. Des tableaux croisés ont été générés en vue d’explorer les discordances et les données manquantes et de découvrir les raisons qui pourraient expliquer les écarts observés entre les données saisies par les vérificateurs et les données d’origine saisies pour chaque champ.
Bien que la sensibilité et la spécificité permettent de comparer l’exactitude de données recueillies à partir d’une source externe par rapport à celle de données recueillies à partir d’une source primaire d’information, une telle approche exige que l’une des sources de données soit identifiée comme référence9. De nombreux facteurs peuvent affecter le transfert de l’information contenue dans un dossier patient, par exemple un changement d’observateur, une documentation de mauvaise qualité, une mauvaise lisibilité, la perte de données, l’inaccessibilité de l’information et le délai avant l’inscription des notes au dossier10; il a donc été impossible d’établir si c’étaient les données originales entrées dans la base Niday ou les données saisies par les vérificateurs qui devaient constituer la référence. Lorsqu’aucune source de données ne peut être désignée comme référence, l’existence d’une forte concordance entre les deux sources suggère qu’elles présentent une grande fiabilité. En d’autres termes, lorsque deux ensembles de données similaires sont comparés et qu’ils renferment une proportion élevée de données identiques, on peut raisonnablement en conclure qu’ils sont tous les deux corrects. Cela indique que les données en main sont de grande qualité.
Par conséquent, pour notre vérification, nous avons utilisé le pourcentage de concordance, le coefficient Kappa de Cohen (κ) et le coefficient de corrélation intraclasse (CCI) entre les variables11 pour comparer les données nouvellement extraites des dossiers des patients avec les données déjà entrées dans la base Niday par les hôpitaux participants. Le pourcentage de concordance a été calculé pour toutes les variables. Le coefficient Kappa et le CCI des variables qualitatives-nominales (n = 87) et des variables continues (n = 3) ont été étudiés séparément.
Variables qualitatives
L’analyse de toutes les variables qualitatives-nominales (sauf le code postal) s’est faite au moyen de tableaux croisés bidirectionnels de chacune des variables et par comparaison des entrées, selon la méthode expliquée ci-dessus. Comme les codes postaux sont des variables chaîne, il s’est avéré impossible de les traiter en tableaux croisés; nous avons donc utilisé la mention « identique » ou « non identique » dans le progiciel SPSS pour calculer le pourcentage de concordance.
Nous avons utilisé le coefficient Kappa de Cohen pour examiner la proportion de réponses concordantes par rapport à la proportion de réponses concordantes que produirait le hasard, en présence de distributions marginales symétriques12-14. Le coefficient Kappa de Cohen représente la proportion de concordance une fois exclue la concordance due au hasard. Les valeurs de Kappa vont de 0 (concordance nulle) à 1 (concordance parfaite). Selon Landis et Koch, une valeur de Kappa de 0,90 (soit 90 %) indique une concordance presque parfaite, tandis qu’une valeur de 0,55 (soit 55 %) traduit une concordance modérée seulement15.
Variables continues
Pour les variables continues, la concordance a été évaluée en utilisant la mention « identique » ou « non identique » dans le progiciel SPSS et en calculant le CCI. Le CCI constitue une mesure plus appropriée de la fiabilité des données continues que le coefficient de corrélation produit-moment de Pearson ou le coefficient de corrélation de rang de Spearman puisque ceux-ci mesurent l’association plutôt que la concordance12-14. Les valeurs du CCI vont de 0 (concordance nulle) à 1 (concordance parfaite), « les valeurs proches de 1 exprimant une bonne fiabilité »16, p. 357. Selon Portney et Watkins17, un CCI de plus de 0,9 (ou 90 %) indique une excellente concordance, tandis qu’un CCI de 0,35 (soit 35 %) dénote une faible concordance entre les variables. Les notes du tableau 2 présentent une interprétation plus détaillée des valeurs du coefficient Kappa et du CCI.
| No | Nom de la variable |
Intitulé du champ de données |
Codage | Non appariés n /1 395 (%) |
Pourcentage de concordance (%) |
Coefficient Kappa de Cohen [κ] (%) |
CCI (%) |
|---|---|---|---|---|---|---|---|
| Champs de données obligatoires | |||||||
| 1. | SITE |
Nom du site | Présaisies | ||||
| 2. | Numéro de dossier de la mère | No de dossier de la mère |
Présaisies | ||||
| 3. | Numéro de dossier du nouveau‑né | No de dossier de l'enfant | Présaisies | ||||
| 4. | Date de naissance de l'enfant | Date de naissance de l'enfant - JMA | Présaisies | ||||
| 5. | Nombre d'autres enfants nés prématurément | Aucun autre enfant né prématurément |
Nombre (0–15) Inconnu | 64 (4,6) | 95,4 | 54,5 | |
| 6. | Nombre d'autres enfants nés à terme | Aucun autre enfant né à terme | Nombre (0–15) Inconnu | 79 (5,7) | 94,3 | 91,2 | |
| 7. | Antécédent de césarienne | Antécédent de césarienne |
Oui Non Inconnu |
50 (3,6) | 96,4 | 81,8 | |
| 8. | Établissement de provenance de la mère (transfert) | Établissement de provenance de la mère |
Liste de sélection des sites Accouchement à domicile planifié Extérieur de la région Patiente non transférée |
35 (2,5) | 97,5 | 25,0 | |
| 9. | Grossesse multiple | Grossesse multiple | Acc. simple Jumeaux Triplés Quadruplés Quintuplés Sextuplés Septuplés |
1 (0,1) | 99,9 | 98,8 | |
| 10. | Type de travail | Type de travail | Spontané Induit Absence de travail |
135 (9,7) | 90,3 | 81,8 | |
| 11. | Type d'accouchement | Type d'accouchement | Vaginal Par césarienne Inconnu |
4 (0,3) | 99,7 | 97,3 | |
| 12. | Date de naissance de la mère | Date de naissance de la mère - JMA | Date de naissance (J/M/A) | 128 (9,2) | 90,8 | S.O. | S.O. |
| 13. | Poids à la naissance | Poids à la naissanceb,c |
Poids à la naissance (grammes) | 114 (8,2) | 91,8b | 35,1b | |
| 14. | Âge gestationnel à la naissance | Âge gestationnel à la naissanceb | Âge gestationnel (sem.) Inconnu |
119 (8,5) | 91,5b | 32,0b | |
| 15. | Sexe de l'enfant | Genre de l'enfant | Mâle Femelle Ambigu Inconnu |
29 (2,1) | 97,9 | 96,0 | |
| 16. | Indice APGAR – 1 min | APGAR1 |
Chiffre (0–10) Inconnu | 58 (4,2) | 95,8 | 92,5 | |
| 17. | Indice APGAR – 5 min | APGAR5 | Chiffre (0–10) Inconnu | 51 (3,7) | 96,3 | 87,7 | |
| 18. | Réanimation néonatale | Aucuneb |
Non vérifié Vérifié |
352 (25,2) | 74,8b | 46,7b | |
| 19. | Médicaments |
12 (0,9) | 99,1 | 64,3 | |||
| 20. | FF02 |
118 (8,5) | 91,5 | 70,2 | |||
| 21. | Intubation |
10 (0,7) | 99,3 | 63,9 | |||
| 22. | VPP |
54 (3,9) | 96,1 | 63,4 | |||
| 23. | Compressions thoraciques | 5 (0,4) | 99,6 | 28,4 | |||
| 24. | Inconnub,c |
86 (6,2) | 93,8b | 3,0b | |||
| 25. | Transfert néonatal vers | Hôpital de transfert néonatal |
Liste de sélection des sites Pas de transfert (hôpital de naissance) Extérieur de la région |
11 (0,8) | 99,2 | 50,0 | |
| 26. | Décès néonatal/morti-naissance | Décès néonatal/morti-naissance | Sans objet Mortinaissance ³ 20 semaines Décès néonatal < 7 jours Décès néonatal > 7– 28 jours | 2 (0,1) | 99,9 | 50,0 | |
| Champs de données non obligatoires | |||||||
| 27. | Code postal de la mère | Code postal de la mère | Code postal au complet | 97 (7,0) | 93,0 | S.O. | S.O. |
| 28. | Corticothérapie anténatale | Corticothérapie anténataleb,c |
Aucune 1 dose < 24 h 2 doses : dernière dose < 24 h 2 doses : dernière dose ³ 24 h Inconnu |
354 (25,4) | 74,6b | 7,5b | |
| 29. | Monitorage fœtal | MF – Tracés d'admissionb,c | Non vérifié Vérifié |
424 (30,4) | 69,6b | 39,2b | |
| 30. | MF – Auscultationb,c | 263 (18,9) | 81,1b | 60,0b | |||
| 31. | MF – Monitorage électronique fœtal intrapartum (externe)b,c | 265 (19,0) | 81,0b | 53,2b | |||
| 32. | MF – Monitorage électronique fœtal intrapartum (interne)b,c | 125 (9,0) | 91,0b | 45,0b | |||
| 33. | MF – Pas de monitorage | 29 (2,1) | 97,9 | 11,4 | |||
| 34. | MF - Inconnu |
36 (2,6) | 97,4 | 13,5 | |||
| 35. | En cas d'induction, indication | Aucune |
Non vérifié Vérifié |
10 (0,7) | 99,3 | 12,5 | |
| 36. | Diabète |
9 (0,6) | 99,4 | 74,0 | |||
| 37. | Déclenchement programmé |
31 (2,2) | 97,8 | 26,8 | |||
| 38. | RCIU/PAG |
14 (1,0) | 99,0 | 64,5 | |||
| 39. | GAG |
8 (0,6) | 99,4 | 55,3 | |||
| 40. | Problèmes obstétricaux de la mère | 32 (2,3) | 97,7 | 14,6 | |||
| 41. | Grossesse multiple |
4 (0,3) | 99,7 | 66,5 | |||
| 42. | Non réactif à l'ERF | 5 (0,4) | 99,6 | 28,4 | |||
| 43. | Oligoamnios |
7 (0,5) | 99,5 | 79,8 | |||
| 44. | Score biophysique faible |
5 (0,4) | 99,6 | 28,4 | |||
| 45. | Retard d'accouchement | 64 (4,6) | 95,4 | 73,8 | |||
| 46. | État prééclamptique | 25 (1,8) | 98,2 | 43,6 | |||
| 47. | Affection maternelle préexistante | 6 (0,4) | 99,6 | 24,8 | |||
| 48. | RPM | 42 (3,0) | 97,0 | 52,8 | |||
| 49. | Autre motif – mère | 51 (3,7) | 96,3 | 32,1 | |||
| 50. | Autre motif – enfant | 24 (1,7) | 98,3 | 32,5 | |||
| 51. | Autre |
16 (1,1) | 98,9 | 24,5 | |||
| 52. | S'il y a eu indiction, méthode | Aucune |
Non vérifié Vérifié |
2 (0,1) | 99,9 | 85,0 | |
| 53. | Amniotomieb |
125 (9,0) | 91,0b | 51,2b | |||
| 54. | Cervidil |
53 (3,8) | 96,2 | 70,0 | |||
| 55. | Cytotec/misopros-tol |
15 (1,1) | 98,9 | 20,5 | |||
| 56. | Mécanique |
10 (0,7) | 99,3 | 63,9 | |||
| 57. | Ocytocine |
129 (9,2) | 90,8 | 66,1 | |||
| 58. | Autre |
26 (1,9) | 98,1 | 18,0 | |||
| 59. | Autre – prostaglandine | 31 (2,2) | 97,8 | 38,3 | |||
| 60. | S'il y a eu césarienne, indication | Aucune |
Vérifié Non vérifié |
2 (0,1) | 99,9 | 85,0 | |
| 61. | Acc. par le siège |
21 (1,5) | 98,5 | 82,4 | |||
| 62. | Procidence du cordon |
1 (0,1) | 99,9 | 80,0 | |||
| 63. | Diabète |
7 (0,5) | 99,5 | 49,0 | |||
| 64. | Échec des forceps/ventouse | 3 (0,2) | 99,8 | 72,6 | |||
| 65. | Anomalie fœtale |
0 | 100,0 | 100,0 | |||
| 66. | RCIU/PAG |
5 (0,4) | 99,6 | 54,4 | |||
| 67. | GAG |
4 (0,3) | 99,7 | 33,3 | |||
| 68. | Demande de la mère |
26 (1,9) | 98,1 | 17,9 | |||
| 69. | Grossesse multiple |
12 (0,9) | 99,1 | 64,3 | |||
| 70. | Arrêt de progrès – travail ou descente/ dystocie | 34 (2,4) | 97,6 | 76,6 | |||
| 71. | État fœtal préoccupant | 31 (2,2) | 97,8 | 72,3 | |||
| 72. | Placenta praevia |
1 (0,1) | 99.9 | 90,9 | |||
| 73. | Décollement placentaire |
4 (0,3) | 99,7 | 60,0 | |||
| 74. | État prééclamptique |
8 (0,6) | 99,4 | 42,6 | |||
| 75. | Prématurité |
8 (0,6) | 99,4 | 19,8 | |||
| 76. | Antécédent de césarienne |
22 (1,6) | 98,4 | 89,7 | |||
| 77. | RPM | 4 (0,3) | 99,7 | 60,0 | |||
| 78. | Autre problème de santé du fœtus | 14 (1,0) | 99,0 | 50,0 | |||
| 79. | Autre problème de santé de la mère | 17 (1,2) | 98,8 | 31,4 | |||
| 80. | Forceps ventouse |
Forceps/ventouseb |
Aucun Forceps Ventouse Forceps et ventouse Inconnu |
189 (13,5) | 86,5b | 55,5b | |
| 81. | Épisiotomie | Épisiotomieb |
Aucune Médio-latérale Médiane 3e degré, dans le prolongement 4e degré dans le prolongement Inconnue |
241 (17,3) | 82,7b | 46,9b | |
| 82. | Déchirure | Déchirure | Aucune 1er degré 2e degré 3e degré 4e degré Cervicale Autre Inconnue |
347 (24,9) | 75,1 | 63,0 | |
| 83. | Soulagement de la douleur de la mère | Aucun |
Non vérifié Vérifié |
69 (4,9) | 95,1 | 52,4 | |
| 84. | Épidurale |
101 (7,2) | 92,8 | 85,5 | |||
| 85. | Générale |
8 (0,6) | 99,4 | 73,1 | |||
| 86. | Localeb |
111 (8,0) | 92,0b | 45,8b | |||
| 87. | Substance narcotique |
97 (7,0) | 93,0 | 82,4 | |||
| 88. | Oxyde d'azote | 94 (6,7) | 93,3 | 71,9 | |||
| 89. | Non pharmacologiqueb | 319 (22,9) | 77,1b | 49,5b | |||
| 90. | Bloc du nerf honteux interne |
1 (0,1) | 99,1 | 92,3 | |||
| 91. | Rachianalgésie péridurale | 21 (1,5) | 98,5 | 50,4 | |||
| 92. | Rachianalgésie |
51 (3,7) | 96,3 | 85,3 | |||
| 93. | Inconnu |
15 (1,1) | 98,9 | 46,0 | |||
| 94. | Heure de la naissance | Heure de la naissance |
Heure de la naissance (format 24 h) Aucune |
127 (9,1) | 90,9 | S.O.a | S.O.a |
| 95. | Accouchée par | Accoucheur | Obstétricien Médecin de famille Sage-femme à l'hôpital Sage-femme à domicile Infirmière praticienne Groupe de sages-femmes Autre Inconnu | 159 (11,4) | 88,6 | 71,8 | |
| 96. | Tabagisme | Statut tabagiqueb,c |
Non-fumeuse £ 20 semaines > 20 semaines £ 20 et > 20 semaines Inconnu |
294 (21,1) | 78,9b | 50,7b | |
Abréviations : CCI, coefficient de corrélation intraclasse; ERF, examen de réactivité fœtale; FF02, oxygène à débit continu; GAG, grand pour l'âge gestationnel; MF, monitorage fœtal; PAG, petit pour l'âge gestationnel; RCIU, restriction de croissance intra-utérine; RPM, rupture prématurée des membranes; VPP, ventilation en pression positive. Notes : Degré de concordance et valeur de Kappa de Cohen (j) une fois exclu l'effet du hasard15: très mauvais < 0; mauvais = 0–0,20; médiocre = 0,21–0,40; modéré = 0,41–0,60; excellent = 0,61–0,80; presque parfait = 0,81–1,00. Degré de concordance du coefficient de corrélation intraclasse (CCI)17: faible < 0,50; modéré = 0,50–0,75; bon ≥ 0,75–0,90; excellent > 0,90.
|
|||||||
Résultats
Ce projet d’assurance qualité a évalué la fiabilité, l’intégralité et l’exhaustivité de la base de données périnatales Niday et a révélé que celle-ci se conformait aux attentes parfois en totalité, parfois partiellement seulement.
Fiabilité
Sur un total de 90 variables, 33 variables (96 champs de données) de la base Niday ont été extraites à nouveau des dossiers des patients pour qu’il soit possible d’en déterminer le degré de concordance avec les données déjà saisies dans la base. Sur les 89 champs de données pour lesquels le coefficient Kappa ou le CCI a été calculé, près de la moitié (n = 39; 43,8 %) a montré une concordance excellente ou presque parfaite (au-delà de ce qui pourrait être imputé au hasard), ce qui laisse entendre que ces variables peuvent être utilisées avec confiance. Un peu plus du tiers des champs de données (n = 34; 38,2 %) affichait un coefficient Kappa inférieur au niveau modéré (à 60 % au-delà de ce qui pourrait être imputé au hasard), même si le taux de concordance était excellent. La faible valeur du coefficient Kappa associé à ce groupe pourrait s’expliquer par l’effet de prévalence dû aux déséquilibres asymétriques des totaux marginaux18. Les autres champs de données (n = 15; 16,9 %) ont montré un pourcentage de concordance inférieur à 95 % et un coefficient Kappa ou un CCI de moins de 60 %, ce qui exprime une concordance presque nulle, médiocre ou modérée (au-delà de ce qui pourrait être imputé au hasard). Ces champs de données pourraient donc être problématiques et doivent être étudiés de manière plus poussée. Le tableau 2 présente le pourcentage de concordance et les valeurs du coefficient Kappa de Cohen ou du CCI pour chaque champ de données.
Intégralité
Selon les contrôles effectués avant le début de la vérification, la proportion de données manquantes était supérieure à 10 % pour environ 34 % des variables de la base Niday. Seules les variables qui étaient obligatoires ou pour lesquelles le taux de données manquantes était faible (< 10 %) juste avant la vérification ont été sélectionnées aux fins de la réextraction (tableau 1).
Les données manquantes (non saisies) ont également été évaluées dans le cadre de la réextraction et se sont révélées être associées aux variables suivantes : corticothérapie prénatale, forceps/ventouse, épisiotomie, déchirures et statut tabagique. Les données manquantes ne se retrouvaient que dans trois sites (F, J et K; voir figure 1). Ce phénomène était principalement dû au fait que les vérificateurs ou le personnel de saisie des données de l’hôpital avaient choisi de laisser une cellule vide plutôt que de sélectionner l’option « aucun(e) » ou « inconnu ». Dans le site F, le vérificateur a laissé le champ vide alors que le personnel de saisie des données de l’hôpital a entré l’option « aucun(e) » ou « inconnu », et l’inverse s’est produit dans les sites J et K. Les données manquantes ne constituent pas un problème important, et ces points de données n’ont pas été exclus de l’évaluation de la concordance. Cela n’a rien d’étonnant étant donné que ces variables avaient été sélectionnées aux fins de la réextraction en raison du faible taux de données manquantes.
Exhaustivité
Au moment de la vérification, plus de 96 % des naissances dans la province (regroupant 95 hôpitaux pratiquant des accouchements et incluant les accouchements pratiqués à l’hôpital par des sages-femmes et certains accouchements à domicile) étaient saisies dans la base Niday. Il y avait 90 éléments de données sur des patients comportant 23 champs obligatoires (au début de la vérification).
Analyse
Bien qu’aucun des deux ensembles de données utilisés lors de la vérification ne puisse être désigné comme référence, l’observation d’une concordance de modérée à élevée (au-delà de ce qui pourrait être imputé au hasard) entre les deux sources laisse entendre que les variables sont comparables entre les deux méthodes de collecte des données19. Le pire scénario en ce qui concerne l’interprétation de ces résultats serait que toutes les différences soient dues à la présence de données erronées dans la base Niday. Lorsqu’on observe une discordance entre les deux sources pour un même champ de données, celle-ci peut s’expliquer par la présence de données erronées dans la base Niday, par la saisie de données erronées lors de la vérification ou par la présence de données erronées dans les deux ensembles de données.
Bien que les discordances n’aient pas toujours pu être expliquées, divers facteurs potentiels ont été relevés lors de l’exploration détaillée des données. Les résultats de la vérification ont indiqué que les discordances entre les deux sources de données touchaient plusieurs sites et concernaient des problèmes d’entrée de données tant du côté des hôpitaux que de celui des vérificateurs. Ces cas ont été regroupés sous quatre thèmes (options disponibles au moment de la saisie des données, clarté de l’information, documentation inexacte et erreur humaine).
Le premier problème concernant les options disponibles au moment de la saisie des données a trait à la désignation de certaines variables. Au moment de la vérification, les champs de données de la base Niday étaient classés comme étant obligatoires ou non obligatoires. L’examen des discordances a révélé que, dans certains cas, le vérificateur avait trouvé de l’information dans le dossier du patient qui avait échappé aux préposés à la saisie des données de l’hôpital. Si les deux groupes devaient repérer et entrer le plus d’information possible, il se peut en réalité que la liberté laissée au personnel de certains sites quant à l’entrée des données dans certains champs non obligatoires ait contribué aux discordances. Cet exemple illustre l’importance de toujours utiliser des champs de données obligatoires et de ne recueillir que des données essentielles et significatives.
Le deuxième problème relatif à ce thème tient aux choix offerts dans la liste de sélection et à l’information qui figure dans le dossier patient. Si l’information inscrite dans le dossier patient ne correspond pas suffisamment aux choix offerts dans la liste de sélection, cela peut nuire à la qualité des données. Par exemple, dans le cas du statut tabagique pendant la grossesse, la documentation peut indiquer qu’une femme fume sans toutefois donner les précisions nécessaires pour qu’il soit possible de déterminer la durée du comportement tabagique pendant la grossesse (p. ex. après ou avant 20 semaines, comme c’était le cas dans la base Niday au moment de la vérification). Certaines discordances sont survenues parce que quelques personnes ont inscrit la mention « inconnu » dans un champ donné lorsque l’information requise ne figurait pas dans le dossier patient alors que d’autres ont laissé le champ en question vide. Cet exemple illustre l’importance d’harmoniser les outils de documentation avec les processus de saisie de données pour améliorer la qualité des données.
Le deuxième thème concerne la clarté de l’information disponible pour chaque champ de données. Une formulation confuse, l’utilisation de doubles négations et les divergences dans l’interprétation de la définition de certaines variables peuvent avoir contribué aux discordances (p. ex. l’interprétation de ce qui constitue une induction ou une accélération du travail). Cet exemple illustre l’importance de s’assurer que les définitions de chaque variable sont précises et utilisables en pratique.
Le troisième thème est lié à une documentation inadéquate, illisible ou inexacte. La saisie des données dépend de l’exactitude de l’information consignée dans le dossier patient. Même si les données à entrer dans la base d’origine et dans celle constituée pour notre vérification devaient être tirées de documents précis, une partie de l’information saisie s’est révélée difficile à repérer ou incohérente, ce qui a contribué aux discordances. Par exemple, les données relatives aux variables de l’âge gestationnel et du poids à la naissance doivent être saisies en double. La double entrée de ces données permet de vérifier que la première entrée est correcte, ce qui améliore la fiabilité de la variable, mais elle ne garantit pas la validité de l’information, comme le démontrent les écarts observés entre les valeurs originales et les données entrées par les vérificateurs pour ces variables.
Enfin, même si rien n’a été négligé pour assurer l’uniformité du processus de saisie des données, il est toujours possible qu’une erreur humaine ait contribué aux discordances entre les deux ensembles de données. La vérification a permis de déceler les problèmes potentiels liés à la saisie des données de certaines variables dans la base de données. Certaines variables présentent davantage de problèmes. Une exploration plus approfondie de la question s’impose afin d’élaborer des stratégies permettant d’améliorer la qualité des données pour ces variables dans la base Niday.
Il est intéressant de signaler que huit des champs de données jugés moins fiables dans le cadre de notre vérification avaient également été jugés problématiques lors d’une vérification antérieure de la base Niday (tableau 2)20. Il s’agit d’un aspect important dans la mesure où certaines de ces variables sont considérées comme étant des éléments prioritaires de grande pertinence pour les rapports périnatals en cours d’élaboration par BORN Ontario.
Dans une étude de validation précédente ayant porté sur le couplage des enregistrements de naissances et de décès de nourrissons au Canada, on a examiné l’âge gestationnel et le poids à la naissance et on a conclu que la concordance était globalement bonne21,22. Une analyse de la Base de données sur les congés des patients (BDCP) de l’Institut canadien d’information sur la santé (ICIS) et de l’Atlee Perinatal Database de la Nouvelle-Écosse (NSAPD) a également révélé que l’âge gestationnel présentait un degré relativement élevé de concordance23. Cette conclusion diverge de celle de notre étude, selon laquelle le CCI associé à l’âge gestationnel et au poids à la naissance se situe entre 30 % et 40 %, signe d’une concordance médiocre.
Dans la BDCP, le codage de la variable « accouchement par césarienne » était bon et l’information sur les déchirures périnatales du premier au quatrième degré et sur l’induction du travail y était également raisonnablement exacte23. Les résultats de notre vérification se sont révélés concordants pour ce qui concerne le type d’accouchement et les déchirures, la concordance entre les données issues de la réextraction et les renseignements entrés antérieurement dans la base Niday étant excellente ou presque parfaite (au-delà de ce qui pourrait être imputé au hasard). Toutefois, les données sur la méthode d’induction (amniotomie) sont apparues moins fiables, la concordance entre les deux ensembles de données n’étant que de 51,2 % (au-delà de ce qui pourrait être imputé au hasard).
L’assurance de l’intégralité et de la fiabilité des données saisies dans la base Niday est complexe. Les données sont saisies manuellement par l’intermédiaire d’un site Internet sécurisé ou sont versées directement dans la base de données à partir des systèmes de documentation électroniques. Les coordonnateurs régionaux transmettent des rappels au personnel hospitalier afin de faciliter le processus de saisie des données et de résoudre les problèmes. Des rapports de vérification sont générés chaque trimestre par un analyste de données pour relever les incohérences dans le nombre et les types de naissances et pour repérer les données erronées. Un programme de formation a été élaboré afin que tous les utilisateurs comprennent bien le système. La pérennité de cette base de données dépend de l’appui général obtenu à tous les niveaux et de la valeur accordée au système comme outil clé du mouvement sur la sécurité des patients. À la lumière des résultats de notre vérification, et après avoir consulté des experts du domaine, nous avons formulé un certain nombre de recommandations afin d’améliorer la qualité des données (tableau 3).
Tableau 3. Recommandations en vue d’améliorer la qualité des données
- Instaurer un système de surveillance continue de la qualité des données dans chaque organisation.
- Encourager les hôpitaux participants à corriger rapidement toute erreur de saisie des données décelée par la vérification.
- Déterminer et communiquer les mesures correctives à prendre pour réduire la fréquence des erreurs récurrentes.
- Insister sur la nécessité d’assurer l’enregistrement précis des données au point de service et l’accès du personnel de saisie des données à l’information.
- Réévaluer le vocabulaire employé et surveiller l’usage qui en est fait (p. ex. mention « aucun(e) » ou « inconnu(e) »).
- Établir des contrôles de vérification automatiques à l’étape de la saisie des données (poids à la naissance, âge gestationnel, date de naissance de la mère, code postal).
- Intégrer des contrôles logiques (c.-à-d. fondés sur les normes du Programme de réanimation néonatale).
- Fixer une limite au poids à la naissance fondée sur l’âge gestationnel, mais assortie d’une fonction de dérogation.
- Réévaluer les options relatives aux variables (c.-à-d., corticothérapie prénatale, épisiotomie, déchirures, forceps/ventouses, soulagement de la douleur de la mère, réanimation néonatale, statut tabagique).
- Préciser la définition des variables suivantes : accouché par; monitorage fœtal (monitorage fœtal intrapartum interne ou externe, tracé d’admission, auscultation); méthode d’induction (amniotomie); type de travail (induction); et accélération.
- Exiger le traitement obligatoire des variables essentielles (c.-à-d. celles requises pour la déclaration), renforcer l’usage des feuilles de saisie des données normalisées.
- Offrir une formation continue pour s’assurer que tout le personnel de saisie de données a suivi la formation normalisée en matière de saisie des données.
- Utiliser des dictionnaires de données afin que tous comprennent les options offertes pour chaque variable.
Cette vérification s’apparente aux initiatives d’assurance qualité du MSSLDO et constitue une étape dans l’amélioration de la qualité des données et des pratiques entourant les soins périnataux. La base de données périnatales Niday est un vaste système multiforme à la disposition des fournisseurs de soins périnatals, des décideurs, des éducateurs et des chercheurs de l’Ontario. Depuis notre vérification, la portée de la base Niday a été élargie, de sorte qu’on y verse maintenant des données sur la totalité des naissances survenant dans la province. De nombreuses mises à niveau et améliorations ont déjà été effectuées. Une exploration plus approfondie des problèmes de qualité est en cours dans le cadre de l’initiative visant à intégrer cette base à quatre autres bases de données périnatales et sur les naissances (Fetal Alert Network, Maternal Multiple Marker Screening, Newborn Screening, Ontario Midwifery Program [OMP] Database). Le Ministère a récemment dégagé des fonds et mis sur pied un nouvel organisme administratif (BORN Ontario) afin de mettre en œuvre ces recommandations.
Limites
Notre vérification présente deux limites potentielles : l’intégralité et la clarté des dossiers des patients et la méthode d’échantillonnage. Parmi les hôpitaux qui alimentaient la base Niday au moment de la vérification, 14 % ont été recrutés pour participer au processus de réextraction. Cet échantillon était suffisant pour permettre l’étude d’un certain nombre de questions. Bien que la sélection des dossiers des patients ait été aléatoire, les hôpitaux ont été sélectionnés par échantillonnage dirigé; par conséquent, les résultats des analyses ne sont pas nécessairement généralisables à l’ensemble des hôpitaux de la province. Le personnel des hôpitaux chargé de saisir les données dans la base Niday et les vérificateurs choisis pour le processus de réextraction avaient reçu pour consigne de tirer le plus grand nombre possible d’éléments d’information des dossiers des patients et de faire preuve de vigilance lors de la saisie des données. La fiabilité des données saisies dans la base Niday dépend cependant de l’intégralité et de la clarté de l’information consignée dans les dossiers. D’éventuelles lacunes relativement à ces deux aspects peuvent affecter la fiabilité des données saisies et influer sur les résultats d’une vérification.
Conclusion
La base de données périnatales Niday contenait 90 éléments de données sur des patients au début de la vérification. On a procédé à la réextraction d’environ le tiers des variables des dossiers des patients afin de déterminer le degré de concordance avec les données déjà saisies dans la base Niday. Environ 17 % des champs de données vérifiés avaient à la fois un pourcentage de concordance inférieur à 95% et un coefficient Kappa ou un CCI inférieur à 60 %, signe d’une concordance modérée, médiocre ou presque nulle (au-delà de ce qui pourrait être imputé au hasard) entre les données entrées à l’origine dans la base Niday et les données saisies à nouveau lors de la vérification. Ce résultat laisse entendre que ces champs de données ne sont pas fiables et qu’une étude plus poussée s’impose pour en assurer la qualité.
Remerciements
Ce projet est le fruit des efforts de nombreuses personnes et organisations de l’Ontario. La vérification de la qualité de la base Niday a été menée sous les auspices du Système ontarien de surveillance en matière de soins périnatals (SOSSP). Nous remercions Monica Prince (de Prince Computing), qui a effectué l’analyse des données et contribué à la rédaction du rapport final. Nous tenons également à remercier Ann Sprague pour son aide dans la révision du rapport final, Deshayne Fell pour son aide dans la relecture du manuscrit, les vérificateurs pour leurs efforts inlassables dans la collecte des données dans les sites participants de la province, de même que les nombreux praticiens, préposés à l’entrée des données et décideurs qui ont contribué à la réalisation du projet.
Références
- Brown A. Building on a foundation to sustain quality data. Queen’s Printer for Ontario [Mise à jour : 2007].
- Last JM (dir.). Dictionnaire d’épidémiologie : enrichi d’un lexique anglais-français. Trad. et adapt., Lise Talbot-Bélair, Michel C. Thuriaux. [Québec] : EDISEM; Paris : Maloine, 2004.
- Rapport sur la santé périnatale au Canada, 2000. [Ottawa] : Système canadien de surveillance périnatale, 2000.
- Choi BCK. La surveillance épidémiologique au 21e siècle sous diverses optiques. Maladies chroniques au Canada. 1998;19(4):159-166.
- Better Outcomes Registry and Network. BORN Ontario – Mission and Vision. Consultation en ligne à la page : http://www.bornontario.ca/about-born/vision-and-mission [Mise à jour : 2010].
- Statistique Canada. Naissances, estimations, par province et territoire. Consultation en ligne à la page : http://www40.statcan.ca/l02/cst01/demo04a-fra.htm [Mise à jour : 2010]
- Freedman G; Health Results Team for Information Management. Building a data quality management framework for Ontario. 2006. Toronto, Ministry of Health and Long-term Care.
- Conseil de recherches en sciences humaines du Canada; Conseil de recherches en sciences naturelles et en génie du Canada; Instituts de recherche en santé du Canada. Énoncé de politique des trois Conseils : Éthique de la recherche avec des êtres humains. 2e éd. [Ottawa] : [Groupe consultatif interagences en éthique de la recherche], décembre 2010.
- Iron K, Manuel DG. Quality assessment of administrative data (QuAAD): An opportunity for enhancing Ontario’s health data. ICES Investigative Report. 2007. Toronto, Institute for Clinical Evaluative Sciences.
- Hierholzer WJ. Health care data, the epidemiologist’s sand: comments on the quantity and quality of data. American Journal of Medicine. 1991;91(Suppl 3B):21S-26S.
- Juurlink D, Preyra C, Croxford R, Chong A, Austin P, Tu J. Canadian Institute for Health Information Discharge Abstract Database: a validation study. 2006. Toronto, Institute for Clinical Evaluative Sciences.
- Streiner DL, Norman GR. Health measurement scales: A practical guide to their development and use. 4 th ed. Oxford, New York: Oxford University Press, 2008.
- Norman GR, Streiner DL. Biostatistics: The bare essentials. 2nd ed. Hamilton: BC Decker, 2000.
- Bartko JJ. Measurement and reliability: Statistical thinking considerations. Schizophrenia Bulletin. 1991;17(3):483-489.
- Landis RJ, Koch GG. The measurement of observer agreement for categorical data. Biometrics. 1977;33(1):159-174.
- Bedard M, Martin NJ, Krueger P, Brazil K. Assessing reproducibility of data obtained with instruments based on continuous measures. Experimental Aging Research. 2000;26(4):353-365.
- Portney LG, Watkins MP. Foundations of clinical research: Applications to practice. 2nd ed. Upper Saddle River, New Jersey: Prentice-Hall, 2000.
- Sim J, Wright CC. The kappa statistic in reliability studies: Use, interpretation, and sample size requirements. Physical Therapy. 2005;85(3):257-268.
- Bader MD, Ailshire JA, Morenoff JD, House JS. Measurement of the local food environment: A comparison of existing data sources. American Journal of Epidemiology. 2010;171(5):609-617.
- Ali AH. An evaluation of perinatal surveillance system in Eastern and Southeastern Ontario. Master’s Thesis, Ottawa (Ont.): University of Ottawa, 2003.
- Fair M, Cyr M, Allen AC, Wen SW, Guyon G, MacDonald RC et le Groupe d’étude sur la mortalité fœtale et infantile du Système canadien de surveillance périnatale. Étude de validation d’un couplage d’enregistrements de naissance et de décès infantile au Canada. Ottawa, Statistique Canada, 1999. No 84F0013XIF au catalogue.
- Fair M, Cyr M, Allen AC, Wen SW, Guyon G, MacDonald R. pour le Groupe d’étude sur la santé fœtale et infantile du Système canadien de surveillance périnatale. Une évaluation de la validité d’un système informatique pour le couplage probabiliste des enregistrements de naissances et de décès de nourrissons au Canada. Maladies chroniques au Canada. 2000;21(1):8-14.
- Joseph KS, Fahey J. Validation des données périnatales de la Base de données sur les congés des patients de l’Institut canadien d’information sur la santé. Maladies chroniques au Canada. 2009;29(3):108-113.