
8. Évaluation et interprétation des données
8.3 Évaluation et interprétation des données de l’étude de la population de poissons
- 8.3.1 Préparation des analyses
- 8.3.2 Statistiques sommaires
- 8.3.3 Analyse de variance et analyse de covariance
- 8.3.4 Transformations
- 8.3.5 Niveau de réplication
- 8.3.6 Critères d’effet et d’appui
- 8.3.7 Analyse statistique de l’échantillonnage non létal
- 8.3.8 Assurance et contrôle de la qualité des données et analyse (erreurs et valeurs aberrantes)
8.4 Effets sur l’exploitabilité des ressources halieutiques
8.5 Évaluation et interprétation des données sur la communauté d’invertébrés benthiques
- 8.5.1 Plans d’étude et méthodes statistiques
- 8.5.2 Traitement des données
- 8.5.3 Approche des conditions de référence
- 8.5.4 Critères d’appui
- 8.6.1 Établissement de α et β
- 8.6.2 Analyse de puissance : détermination de la taille d’échantillon requise, de la puissance et du seuil critique d’effet approprié
8.8 Considérations statistiques pour les études en mésocosmes
Annexe 1 : Guide étape par étape des procédures statistiques
Annexe 2 : Représentation graphique et tabulaire des données
Annexe 3 : Étude de cas – ANCOVA et analyse de puissance pour l’étude des poissons
Liste des tableaux
- Tableau 8-1 : Détermination exigée de l’étude des poissons, la précision attendue et statistiques sommaires
- Tableau 8-2 : Indicateurs et critères d’effet pour différents plans d'étude et les statistiques s’appliquant a l’étude de la population de poissons.
- Tableau 8-3 : Critères d’appui à utiliser pour les analyses complémentaires.
- Tableau 8-4 : Résumé des critères d’effet analysés au moyen de l’ANCOVA
- Tableau 8-5 : Crtières d’effets et critères d’appui pour l’exploitabilité des poissons et méthode statistique.
- Tableau 8-6 : Méthode statistique utilisée pour déterminer la présence d’un effet pour chacun des sept plans d’étude
- Tableau 8-7 : Tailles d’échantillon nécessaires pour détecter une différence de ± 2 ET
8.1 Aperçu
Selon les exigences des études de suivi des effets sur l’environnement (ESEE), en vertu du Règlement sur les effluents des mines de métaux (REMM), lorsque les études de suivi biologique sont terminées, il est requis de produire un rapport d’interprétation (REMM, annexe 5, article 17). Le propriétaire ou l’exploitant doit présenter à l’agent d’autorisation des rapports écrits sur les résultats des études. Le rôle du rapport d’interprétation dans le Programme d’ESEE est de résumer les résultats des études (y compris les difficultés ou les facteurs de confusion présents), d’effectuer les analyses pertinentes sur les tendances spatiales (et, si les données le permettent, sur les tendances temporelles), de préciser tout « effet » déterminé et de faire des recommandations pour les études subséquentes du Programme d’ESEE. L’interprétation des données ou le rôle du rapport n’inclut pas l’évaluation de la signification écologique, économique ou sociale des résultats. Le contenu du rapport d’interprétation est présenté au chapitre 10 du présent guide et dans le REMM.
L’objet du présent chapitre est de fournir des directives générales sur la façon d’évaluer et d’interpréter les données de l’ESEE, et plus précisément :
- les critères d’effets à retenir et à présenter;
- la méthode statistique (ou autre) à utiliser pour chaque critère d’effet en vue de déterminer la présence ou l’absence d’un effet;
- le rôle de l’analyse de puissance, de a, de b et du seuil critique d’effet (SCE) dans la détermination des effets.
Les ESEE sont basées sur des phases itératives de suivi et de production de rapports. Pour chaque phase, il est requis de présenter sous forme de rapport l’évaluation des données effectuée en vertu de l’article 16 de l’annexe 5. Celui-ci doit préciser tout effet sur les populations de poissons, les tissus de poissons et la communauté d’invertébrés benthiques, les conclusions générales des études de suivi biologique fondées sur les résultats de l’analyse statistique, ainsi qu’un sommaire des résultats des suivis antérieurs. Plus spécifiquement, les données recueillies pour chaque mine devraient être analysées afin de déterminer s’il existe des différences significatives pour certains indicateurs d’effet entre les zones de référence et les zones exposées ou le long d’un gradient d’exposition (détermination de l’effet). Outre l’analyse au cours d’une phase (analyse spatiale), il est recommandé d’effectuer une comparaison des effets entre les phases (comparaisons temporelles) afin de déterminer si des effets déterminés précédemment diminuent ou prennent de l’ampleur.
Aux fins de l’ESEE, seules des données particulières (les indicateurs d’effets) recueillies lors des études sur les poissons, les invertébrés benthiques et sur l’exploitabilité du poisson sont utilisées pour évaluer la présence d’effets. Les autres données de l’ESEE ne servent qu’à faciliter l’interprétation des effets sur le poisson et le benthos (p. ex., caractérisation de l’effluent et suivi de la qualité de l’eau) ou à la caractérisation des changements temporels de la qualité de l’effluent (p. ex., essais de toxicité sublétale). Les tableaux présentés dans les sections suivantes résument les procédures recommandées pour l’analyse des données pour les indicateurs d’effet, pour chaque exigence de suivi (tableaux 8‑2 et 8‑3 et section 8.5). On trouvera aussi d’autres détails dans les différentes sections du présent chapitre. Bon nombre des problèmes d’interprétation des données sont les mêmes pour les études des poissons, de l’exploitabilité des ressources halieutiques et des communautés d’invertébrés benthiques décrites dans les sections suivantes (p. ex., les conditions d’application des techniques statistiques et leur interprétation sont communes à plusieurs de ces sections). Plusieurs de ces problèmes communs sont traités dans la section sur l’étude des poissons ci-dessous et ne sont pas repris dans les sections suivantes portant sur l’exploitabilité des ressources halieutiques et les communautés d’invertébrés benthiques.
8.2 Précisions sur la définition du terme « effet » et la signification de l’interprétation des données dans le cadre d’une étude de suivi des effets sur l’environnement
Il est essentiel de connaître 1) les types d’analyses de données pertinentes, et 2) la signification du terme « interprétation », pour le Programme d’ESEE, particulièrement lors de la rédaction d’un rapport d’interprétation. Pour cela, il faut d’abord définir ce qu’est un effet.
Dans le cadre d’une ESEE, un effet est généralement défini comme une différence statistiquement significative des indicateurs d’effet pour le poisson, le potentiel d’utilisation du poisson ou les communautés d’invertébrés benthiques mesurés entre une zone exposée à un effluent et une zone de référence, ou une différence statistiquement significative de ces indicateurs d’effet dans une zone exposée où existe un gradient décroissant de concentrations d’effluent. Pour l’analyse des tissus de poissons (effectuée pour déterminer l’exploitabilité des ressources halieutiques), un effet signifie des mesures de la concentration du mercure total dans les tissus de poissons, prises dans la zone exposée, supérieures à 0,5 µg/g (poids humide), présentant une différence statistique et ayant une concentration plus élevée par rapport à celles mesurées dans les tissus de poissons prises dans la zone de référence. Dans les cas où il n’est pas possible d’examiner les poissons capturés sur le terrain ou la distribution sur le terrain des invertébrés benthiques dans les zones exposées à l’effluent et dans les zones de référence, on peut avoir recours à une autre méthode de suivi pour le poisson ou l’habitat du poisson, en vue de déterminer si l’effluent cause un effet (chapitre 9).
Tout en tenant compte de la définition d’effet présentée ci-dessus, il est important de reconnaître que ce ne sont pas tous les effets déterminés par l’ESEE qui constituent des dommages pour le poisson, son habitat ou l’exploitabilité des ressources halieutiques. Toutefois, les effets, comme ils sont définis ci‑dessus, représentent des différences ou des gradients montrés scientifiquement qui peuvent refléter des changements dans l’écosystème attribuables à l’effluent. Par conséquent, l’information détaillée sur les effets, dont leur ampleur, leur étendue géographique et leurs causes possibles, pourrait contribuer à une meilleure connaissance de l’écosystème et servir à la gestion des ressources aquatiques.
8.3 Évaluation et interprétation des données de l’étude de la population de poissons
Les données recueillies au cours de l’étude des poissons sur les indicateurs de la croissance, la reproduction, la condition et la survie (lorsqu’il est possible d’obtenir des données servant à déterminer ces indicateurs) comprennent la longueur, le poids corporel total et l’âge du poisson, le poids de son foie ou de l’hépatopancréas et, si les poissons ont atteint la maturité sexuelle, le poids des oeufs, la fécondité et le poids des gonades (REMM, annexe 5, article 16).
L’ensemble de la procédure qui doit être suivie et présentée dans le rapport peut être réaprti en cinq étapes : 1) des analyses, 2) statistiques sommaires, 3) analyses de variance (ANOVA), 4) analyses de covariance (ANCOVA) et 5) analyses de la puissance statistique. L’annexe 1 présente des instructions étape par étape sur les procédures statistiques à suivre pour l’étude des populations de poissons.
Les déterminations exigées pour l’étude des poissons, la précision attendue et les statistiques sommaires sont décrites dans le tableau 8‑1. Le tableau 8‑2 présente les indicateurs d’effet pour différents plans d'étude et les statistiques s’appliquant à l’étude de la population de poissons. Le tableau 8‑3 définit les critères d’appui.
| Détermination exigée (annexe 5, article 16 du REMM) | Précision attendue*** | Statistiques sommaires à fournir (annexe 5, article 16 du REMM) et autres informations générales. |
| Longueur (à la fourche, totale ou standard)* | ± 1 mm | Moyenne, médiane, écart-type, erreur type, valeurs minimales et maximales dans les zones d’échantillonnage |
| Poids corporel total (frais) | ± 1,0 % | Moyenne, médiane, écart-type, erreur type, valeurs minimales et maximales pour les zones d’échantillonnage |
| Âge | ± 1 an (10 % des mesures doivent être confirmées de façon indépendante) | ± 1 an (10 % des mesures doivent être confirmées de façon indépendante) |
| Poids des gonades (si les poissons ont atteint la maturité sexuelle) |
± 0,1 g pour les espèces de poissons de grande taille et 0,001 g pour les espèces de poissons de petite taille | Moyenne, médiane, écart-type, erreur type, valeurs minimales et maximales pour les zones d’échantillonnage |
| Poids des œufs (si les poissons ont atteint la maturité sexuelle) |
± 0,001 g | Poids (un minimum de 100 oeufs par sous-échantillon est recommandé), moyenne, erreur type, valeurs minimales et maximales pour les zones d’échantillonnage |
| Fécondité ** (si les poissons ont atteint la maturité sexuelle) |
± 1,0 % | Nombre total d’œufs par femelle, moyenne, erreur type, valeurs minimales et maximales pour les zones d’échantillonnage |
| Poids du foie ou de l’hépatopancréas | ± 0,1 g pour les espèces de poissons de grande taille et 0,001 g pour les espèces de poissons de petite taille | Moyenne, médiane, écart-type, erreur type, valeurs minimales et maximales pour les zones d’échantillonnage |
| Anomalies | s.o. | Présence de tout parasite, lésion, tumeur ou de toute autre anomalie |
| Sexe | s.o. |
* Si la nageoire caudale est fourchue, mesurer la longueur à la fourche (de l’extrémité de la partie antérieure jusqu’à la fourche de la nageoire caudale). Autrement, mesurer la longueur totale et indiquer le mode de mesure de la longueur utilisé pour chaque espèce. Si une usure prononcée de la nageoire est observée, il faut mesurer la longueur standard.
** La fécondité peut être déterminée en divisant le poids total des ovaires par le poids individuel des œufs, qui peut être estimé en comptant le nombre d’œufs dans un sous échantillon d’au moins 100 œufs.
*** Pour les poissons de petite taille, l’utilisation d’une balance à au moins trois décimales est recommandée.
| Indicateur d’effet | Critères d’effets et méthodes statistiques | ||
|---|---|---|---|
| Échantillonnage létal |
Échantillonnage non létal |
Mollusques sauvages |
|
| Croissance (Utilisation de l’énergie) | Taille selon l’âge (poids corporel en fonction de l’âge) (ANCOVA) | Taille (longueur et poids) des jeunes de l’année (âge 0+) à la fin de la période de croissance. (ANOVA) | Poids humide des animaux entiers (ANOVA) |
| Reproduction (Utilisation de l’énergie) | Poids relatif des gonades (poids des gonades en fonction du poids corporel) (ANCOVA) | Abondance relative des jeunes de l'année (% de jeunes de l'année) (voir chapitre 3, section 3.4.2.2) | Poids relatif des gonades (poids des gonades en fonction du poids corporel) (ANCOVA) |
| Condition (Stockage de l’énergie) | Poids corporel en fonction de la longueur; Poids relatif du foie (poids du foie en fonction du poids corporel) (ANCOVA) |
Poids corporel en fonction de la longueur (ANCOVA) | Poids sec des animaux entiers, poids sec de la coquille ou des tissus mous en fonction de la longueur de la coquille (ANCOVA) |
| Survie | Âge (ANOVA) | Distribution de fréquence des longueurs (test de Kolmogorov-Smirnov pour deux échantillons) |
Distribution de fréquences des longueurs (test de Kolmogorov-Smirnov pour deux échantillons) |
| Indicateur d’effet | Critères d’appui | Méthode statistique (selon le critère) |
|---|---|---|
| Utilisation de l’énergie | Poids corporel (entier) | ANOVA |
| Longueur | ANOVA | |
| Taille selon l’âge (longueur en fonction de l’âge) | ANCOVA | |
| Poids relatif des gonades (poids des gonades en fonction de la longueur) | ANCOVA | |
| Fécondité relative (nombre d’œufs/femelle en fonction du poids corporel) | ANCOVA | |
| Fécondité relative (nombre d’œufs/femelle en fonction de la longueur) | ANCOVA | |
| Fécondité relative (nombre d’œufs/femelle en fonction de l’âge) | ANCOVA | |
| Survie des jeunes de l'année | Voir chapitre 3, section 3.4.2.2 | |
| Stockage de l’énergie | Taille relative du foie (poids du foie en fonction de la longueur) | ANCOVA |
| Taille relative des œufs (poids moyen des œufs en fonction du poids corporel) | ANCOVA | |
| Taille relative des œufs (poids moyen des œufs en fonction de l’âge) | ANCOVA |
Remarque : Ces analyses sont effectuées à des fins informatives, et les différences significatives entre les zones de référence et les zones exposées et ne sont pas nécessairement utilisées pour indiquer un effet.
1 Pour l’ANCOVA, le premier terme entre parenthèses est le critère (variable dépendante, Y) qu’on analyse pour déterminer la présence d’un effet de l’effluent. Le deuxième terme entre parenthèses est la covariable, X (âge, poids ou longueur).
8.3.1 Préparation des analyses
Lorsque les mesures sur le terrain et en laboratoire sont terminées, les données doivent rapidement être saisies dans une feuille de calcul électronique et soumises à l’assurance et au contrôle de la qualité (AQ/CQ). Les valeurs saisies dans la feuille de calcul devraient être contre-vérifiées avec les données manuscrites originales afin d’éviter les erreurs typographiques. On utilise comme outil de travail de base une matrice de données dont les colonnes indiquent la localisation des sites (zones) et les variables, et les lignes, les observations. Une colonne sera prévue pour noter les commentaires sur l’état physique et toute anomalie constatée pendant l’échantillonnage. Ces commentaires pourraient être utiles pour repérer toute observation anormale et aider à déterminer si des données devraient être exclues d’une analyse. On choisira comme identificateur de lieu ou de zone un terme qui pourra facilement être identifié comme référence ou site d’exposition. Ceci facilitera l’interprétation si elle est effectuée par des personnes qui ne sont pas familières avec les codes de localisation des sites. Si le nombre de poissons capturés à un site d’exposition est insuffisant, mais qu’un nombre suffisant est recueilli au site de référence, on prendra soin d’en prendre note.
L’omission de repérer les erreurs de transcription peut invalider les analyses subséquentes. Une fois que les données nécessaires à l’interprétation ont été entrées correctement, elles doivent être résumées et examinées afin de repérer les valeurs erronées ou aberrantes Il faut ensuite évaluer la normalité des données et les transformer, au besoin. Tout facteur de confusion important devrait aussi être résumé.
Les différences entre les sexes sont courantes sur le plan du taux de croissance, du poids corporel, du coefficient de condition, de la taille des gonades et du poids du foie, car les besoins énergétiques globaux des mâles et des femelles sont différents. Par conséquent, pour tous les critères, les sexes devraient être séparés pour les analyses. De plus, les poissons immatures ne devraient pas être inclus avec les poissons sexuellement matures pour les analyses.
8.3.1.1 Poissons immatures
Il faudrait confirmer que tous les poissons considérés comme adultes connaissent un développement gonadique en vue de la prochaine saison de fraie. L’inclusion de poissons immatures dans les analyses statistiques peut fausser les résultats. Les poissons immatures consacrent proportionnellement plus d’énergie à la croissance et la relation entre leur taille et la croissance de leurs gonades est donc différente de celle des adultes. Aux fins de l’analyse des données, les poissons identifiés commes immatures dans le fichier doivent être exclus. L’indice gonadosomatique (IGS = (poids des gonades/poids corporel) × 100) peut être utile pour identifier les poissons immatures. Chez de nombreuses espèces de poissons, les individus immatures ont habituellement un IGS inférieur à 1 %. Il y a toutefois des exceptions notables, comme les espèces qui assurent la garde des œufs comme la Barbotte brune. Un diagramme du poids des gonades en fonction du poids corporel, auquel on ajoute cette règle de l’IGS, peut être très utile pour identifier les poissons immatures. Les notes de terrain peuvent aussi aider à relever les observations inhabituelles susceptibles d’indiquer la présence de spécimens immatures (p.ex., des commentaires comme « une seule gonade pesée »). La période d’échantillonnage doit être adaptée à la biologie de l’espèce (cycle vital) afin d’éviter de capturer des poissons avant le développement de leurs gonades pour la prochaine saison de reproduction. Toutefois, lorsqu’un échantillonnage non létal est prévu et que la distribution de fréquence des âges est utilisée pour évaluer le succès de la reproduction, la période d’échantillonnage est moins importante. L’analyse des données devrait être réalisée séparément sur les poissons matures et immatures, sauf, bien entendu, lorsque l’objectif est de comparer la proportion de poissons non reproducteurs entre les sites.
8.3.2 Statistiques sommaires
Les statistiques descriptives, soit la moyenne, la médiane, l’écart-type, l’erreur type et les valeurs minimales et maximales, sont calculées, s’il est possible d’obtenir les données, afin de déterminer les indicateurs de croissance, de reproduction, de condition et de survie, ce qui inclut la longueur, le poids corporel total, l’âge, le poids du foie ou de l’hépatopancréas et, si le poisson est mature sexuellement, la taille des œufs, le taux de fécondité et le poids des gonades du poisson (REMM, annexe 5, article 16). Les variables mesurées pendant l’étude sur les poissons afin de déterminer les effets sur la croissance, la reproduction, la condition et la survie des poissons, la précision attendue et les statistiques sommaires sont décrites dans le chapitre 3.
Les statistiques sommaires doivent être calculées par espèce et par sexe, pour chaque zone dont les données sont présentées (p. ex., zone de référence et zone exposée). Avant de calculer les statistiques sommaires, des diagrammes en rectangle et moustaches des données devraient être tracés pour repérer les valeurs aberrantes. Les statistiques sommaires devraient être présentées sous forme de graphiques et de tableaux pour toutes les variables. Il faut aussi évaluer la normalité des données et l’égalité des variances (conditions d’application des tests statistiques). Il est à noter que, pour l’ANCOVA, les pentes, les moyennes ajustées et les termes d’erreur associés devraient aussi être indiqués, tel qu’il est précisé ci-dessous.
Diverses techniques de représentation graphique comme les diagrammes en rectangles et moustaches, les courbes de distribution normale et les diagrammes arborescents peuvent être utilisés pour repérer les valeurs aberrantes (valeurs aberrantes véritables ou erreurs de saisie). La plupart des logiciels de calcul statistique comportent des modules de synthèse des données capables de générer des statistiques sommaires et des graphiques. Ces descripteurs statistiques sommaires sont généralement nécessaires pour la présentation, et la présence de valeurs aberrantes anormalement élevées ou faibles peut indiquer des erreurs. Il ne faut pas éliminer les valeurs extrêmes ou aberrantes de l’ensemble de données (à moins qu’elles résultent clairement d’erreurs commises lors de l’échantillonnage, des mesures ou de la saisie des données) (Grubbs, 1969; Green, 1979), car l’élimination injustifiée de données valides aurait pour effet de réduire la puissance statistique de l’étude des poissons. Il est préférable de souligner l’existence des valeurs aberrantes dans le rapport et d’évaluer l’influence qu’elles peuvent avoir sur les résultats en reprenant les analyses des données sans ces valeurs.
8.3.3 Analyse de variance et analyse de covariance
En plus du calcul des statistiques descriptives, une analyse des résultats doit être effectuée pour déterminer s’il y a une différence statistique entre les zones d’échantillonnage (REMM, annexe 5, alinéa 16c)). Cela s’effectue habituellement au moyen de l’analyse de variance (ANOVA) ou de l’analyse de covariance (ANCOVA); toutefois, dans certains cas, d’autres procédures statistiques (c.-à-d. des méthodes non paramétriques) peuvent être utilisées. Les analyses (ANOVA et ANCOVA) utilisées pour déterminer si des effets statistiquement significatifs se sont produits devraient suivre trois étapes, soit l’examen, l’analyse et l’interprétation des données (l’annexe 1 contient des directives détaillées sur les méthodes statistiques s’appliquant à l’étude des poissons) :
- Les données devraient être examinées pour déterminer si elles satisfont aux conditions d’application de l’ANOVA ou de l’ANCOVA. Ces méthodes sont assez robustes pour permettre un non-respect modéré de certaines conditions et, dans certains cas, la transformation des données aidera à compenser les écarts par rapport aux conditions. Dans les cas où la transformation des données ne suffit pas, il peut être nécessaire d’avoir recours à des méthodes non paramétriques, auquel cas les méthodes d’analyse de puissance décrites dans la section 8.6 ne s’appliquent pas. Ces questions sont examinées ci‑dessous, et les manuels de statistique de référence (p. ex., Sokal et Rohlf, 1995) devraient être consultés pour en savoir plus sur le sujet.
- Après l’examen des données et les transformations nécessaires, on peut procéder aux comparaisons statistiques elles‑mêmes.
- Une fois réalisées les comparaisons statistiques, les principaux résultats pour les indicateurs d’effet (tableau 8‑1) sont présentés clairement de façon à indiquer si des effets a été observé et, le cas échéant, la nature des effets (dont sa direction et son amplitude). Un effet statistique existe quand la valeur de p est inférieure à la valeur de a déterminée a priori, selon les directives de la section 8.6.
8.3.3.1 Analyse de variance
L’ANOVA est utilisée afin de détecter les différences entre les sites sur le plan de la longueur, du poids et de l’âge. Les conditions d’application de l’ANOVA sont les suivantes :
- les données des populations exposées et de référence ont une distribution normale;
- les variances sont égales entre les populations exposées et de référence;
- les termes d’erreur ont une distribution indépendante.
Une ANOVA à un facteur est utilisée afin de tester les différences de la variable dépendante moyenne (longueur, poids ou âge) en utilisant le facteur « site » (p. ex., site de référence ou exposé). Un tracé des résidus peut être utile pour identifier les valeurs aberrantes. Les observations dont les résidus studentisés sont supérieurs à 4 justifient habituellement un examen plus approfondi. Les variantes non paramétriques de l’ANOVA incluent le test de Kruskal-Wallis ou, si on compare les données de deux sites, le test de Mann-Whitney (une alternative non paramétrique au test t pour deux échantillons).
8.3.3.1.1 Normalité des données et uniformité des variances
Il faut vérifier les conditions de normalité et d’homogénéité de la variance avant d’appliquer la plupart des procédures paramétriques. Toutefois, la plupart des méthodes statistiques unidimensionnelles basées sur une distribution normale sont très robustes et tolèrent un non-respect modéré des conditions d’application. La transformation des données originales aidera à normaliser les données ou à homogénéiser les variances. Les transformations logarithmiques sont souvent choisies parce que la plupart des mesures biologiques sont considérées comme suivant une échelle logarithmique ou exponentielle (Peters, 1983) et qu’une telle transformation est significative sur le plan biologique. Il est à noter qu’aux fins de l’étude des poissons de l’ESEE, on ne doit pas ajouter 1 aux valeurs avant d’effectuer une transformation logarithmique, car cela a des effets non souhaitables sur les variances calculées lorsqu’on change les unités de mesure. Si les transformations ne produisent pas de données satisfaisant aux conditions, un tracé des résidus pourrait révéler des données problématiques qui pourraient justifier un examen plus approfondi. La plupart des méthodes statistiques unidimensionnelles sont robustes lors d’une violation modérée des conditions, à l’exception de certaines cas, notamment lorsque les effectifs sont faibles et inégaux. En cas de violation grave des conditions, on pourra envisager le recours à des méthodes statistiques non paramétriques.
8.3.3.1.2 Indépendance (pseudoréplication)
Lors de la conception d’une expérience, il est souhaitable de s’assurer que les réplicats sont alloués de façon aléatoire aux différents niveaux de traitement, de façon que les réponses de chaque réplicat soient indépendantes de celles des autres. Cette dimension aléatoire permet dans une certaine mesure de s’assurer que les différences de réponses observées entre les divers traitements sont attribuables aux effets du traitement et non à d’autres facteurs.
Un manque d’indépendance peut survenir lorsque, par exemple, une personne recueille les données dans la zone exposée tandis qu’une autre personne recueille les données dans la zone de référence. Les données peuvent être biaisées si les deux personnes utilisent constamment des protocoles d’échantillonnage ou de tri légèrement différents. En général, on ne peut régler ce genre de problème qu’en modifiant la méthode d’échantillonnage pour éliminer les sources de biais.
L’attribution aléatoire des réplicats aux différents niveaux de traitement est une procédure relativement facile lorsqu’on effectue des expériences de manipulation (p. ex., essais contrôlés en laboratoire), mais elle est plus difficile à réaliser dans le cadre d’études d’observation sur le terrain comme les études d’impact environnemental (p. ex., ESEE portant sur un seul agent de stress) ou les évaluations environnementales (c.‑à‑d. agents de stress multiples). Ces études testent des hypothèses relatives à la présence et l’ampleur des effets. Toutefois, la force des conclusions qu’on peut tirer de ce type d’expérience est limitée pour deux raisons (Paine et al., 1998) :
- l’agent de stress (p. ex., point de rejet de la mine, barrage hydroélectrique) ne peut pas être reproduit;
- les agents de stress ne peuvent pas être appliqués de façon aléatoire aux réplicats.
Par conséquent, l’agent de stress ou le traitement est toujours en partie ou entièrement confondu avec des facteurs spatiaux ou temporels, et les effets observés peuvent être ou non causés par l’agent de stress à l’étude. Par exemple, s’il s’agit de déterminer si l’effluent d’une industrie a un effet sur les populations de poissons en aval, il est impossible de répéter le traitement, soit l’exposition à l’effluent (puisqu’il n’y a qu’une seule usine et un seul point de rejet), ni d’attribuer au hasard les populations de poissons aux différents niveaux de traitement (zone de référence vs zone exposée). Ainsi, si des différences significatives sont observées entre la population de poissons de la zone de référence et celle de la zone exposée, on peut seulement affirmer que ces deux populations diffèrent, mais on ne peut conclure que les différences observées sont causées par l’exposition à l’effluent. L’interprétation de différences significatives comme effets du traitement alors que les traitements ne sont pas répétés ou que les réplicats ne sont pas indépendants est nommée pseudoréplication (Hurlbert, 1984).
Avant d’attribuer la cause d’un impact à un agent de stress en particulier, il est indispensable de confirmer les observations par une répétition dans le temps et de s’efforcer de démontrer que les agents de stress à l’étude sont impliqués dans les réponses.
8.3.3.2 Analyse de covariance
L’ANCOVA est utilisée afin de tester les différences entre sites sur le plan de la condition, du poids relatif des gonades, du poids relatif du foie, du poids selon l’âge, de la taille selon l’âge et de la fécondité relative. Le tableau ci-dessous contient un résumé de cette analyse.
| Critères d’effet | Variable dépendante | Covariable |
|---|---|---|
| Condition | Poids corporel | Longueur |
| Poids relatif du foie | Poids du foie | Poids corporel |
| Poids relatif des gonades | Poids des gonades | Poids corporel |
| Poids selon l’âge | Poids corporel | Âge |
| Taille selon l’âge | Longueur | Âge |
| Fécondité relative | Oeufs/femelle | Poids corporel |
Les conditions d’application de l’ANCOVA sont les suivantes :
- la relation entre la variable dépendante et la covariable est linéaire;
- les pentes des droites de régression entre sites sont parallèles;
- la covariable est fixe et mesurée sans erreur;
- les résidus ont une distribution normale et indépendante avec moyenne nulle et variance commune.
Il faut noter que l’ANCOVA est fondamentalement une méthode à deux étapes consistant à :
- déterminer si les pentes sont à peu près parallèles;
- si les pentes sont parallèles, déterminer si les élévations des droites de régression sont significativement différentes. Cette procédure est expliquée en détail ci‑après.
L’ANCOVA est utilisée afin de détecter les différences de variables dépendantes entre les sites en tenant compte de la variabilité des sujets des tests en incluant une covariable dans l’analyse. L’inclusion d’une covariable dans l’analyse fait diminuer le terme d’erreur (en tenant compte de la variabilité expliquée par la régression de la variable dépendante en fonction de la covariable) et augmente ainsi la puissance du test (Huitema, 1980).
Il a été suggéré que la plage de valeurs de la variable indépendante (covariable) devrait être approximativement la même pour tous les sites. Il sera difficile de mettre ce principe en oeuvre, mais le non-respect de ce principe devra être pris en compte lors de l’interprétation des résultats, le cas échéant. S’il y a des raisons de croire que le chevauchement des plages de valeurs de la covariable pose problème, on effectuera une ANOVA à un critère des valeurs de la covariable entre les sites. Si les moyennes de la covariable ne diffèrent pas de manière significative entre les sites, les résultats de l’ANCOVA seront probablement fiables (Quinn et Keough, 2002). Une différence significative des valeurs moyennes de la covariable entre les sites constitue un effet significatif. Lors de l’interprétation des différences entre moyennes ou plages de covariables observées, il faut tenir compte de l’uniformité de l’utilisation du dispositif d’échantillonnage entre les sites et de la sélection des échantillons. Il pourrait être approprié de fournir une analyse d’un sous-ensemble des données qui omettrait les valeurs inhabituellement basses ou élevées de la covariable afin de fournir une analyse fiable.
Il est nécessaire d’examiner la plage de valeurs des covariables pour le critère d’effet « poids selon l’âge » avant d’effectuer une ANCOVA. Pour plusieurs espèces de poissons de petite taille, la plage de valeurs de la covariable « âge » pourrait ne s’étendre que de 2 à 3 ou de 2 à 4. Une ANCOVA avec seulement deux ou trois valeurs de la covariable peut produire des résultats trompeurs. Dans ces cas, il pourrait être approprié d’effectuer une ANOVA à un facteur du poids corporel, où le site d’échantillonnage devient le facteur pour chaque groupe d’âges.
8.3.3.2.1 Analyse des résidus
La méthode privilégiée d’examen des résidus consiste à utiliser des méthodes graphiques plutôt que des tests formels pour évaluer la normalité et l’égalité de la variance. En fait, Day et Quinn (1989) conseillent de ne pas utiliser les tests formels. Une bonne analyse du sujet peut être retrouvée dans Miller (1986). Draper et Smith (1981) examinent les diverses méthodes d’analyse des résidus, particulièrement des résidus des régressions. La plupart des logiciels de statistiques comprennent des modules pour l’examen des résidus. Ces méthodes sont généralement graphiques, mais il existe aussi des statistiques de diagnostic. Le principal avantage de ces méthodes, comparativement aux tests formels, est qu’elles permettent de caractériser la cause de la violation de la condition de normalité ou d’égalité des variances.
8.3.3.2.2 Variable indépendante
L’hypothèse selon laquelle la variable indépendante serait fixe est fréquemment enfreinte, et Draper et Smith (1981) analysent les conséquences de ce non‑respect. Une variable indépendante non fixe pourrait vraisemblablement se révéler problématique, principalement dans les situations où la plage de la variable indépendante est très petite, c’est‑à‑dire lorsque la plage de taille (ou d’âge) des poissons incluse dans la régression est très petite. Dans ce cas (plage très étroite de taille ou d’âge), il y a peu d’avantages à utiliser l’ANCOVA en prenant la taille ou l’âge comme covariable et les données serait mieux analysées en effectuant une simple comparaison entre la zone exposée et la zone de référence par ANOVA (c.-à-d. qu’il n’est pas nécessaire de prendre en compte l’influence de la covariable).
8.3.3.2.3 Régression linéaire
L’hypothèse d’une relation linéaire peut être testée pour les échantillons présentant des observations multiples à différentes valeurs de la variable indépendante. Cela pourrait être faisable pour des variables discrètes comme l’âge, mais pas pour des variables indépendantes continues comme le poids corporel. Il faudrait au moins vérifier la linéarité par inspection visuelle. On peut souvent améliorer la linéarité par transformation (p. ex., la transformation log-log est fréquemment utilisée pour les ANCOVA portant sur les poissons dans le cadre de l’ESEE). Il faut aussi examiner les graphiques des régressions pour s’assurer que les pentes ne sont pas indûment influencées par des données aberrantes. Les diagrammes de dispersion aident à détecter les valeurs aberrantes ou inhabituelles. Par exemple, pour l’analyse des données de reproduction, le graphique aide à repérer la présence potentielle de poissons « immatures » qui affecteraient les résultats. Les diagrammes de dispersion devraient être inclus dans le rapport d’interprétation.
8.3.3.2.4 Pentes des droites de régression
Une des hypothèses clés de l’ANCOVA est que les pentes des droites de régression pour la zone de référence et la zone exposée sont approximativement égales. La première partie d’une ANCOVA consiste, par conséquent, à tester les différences de pentes entre les zones. La présence d’un terme d’interaction significatif dans l’ANCOVA entre la covariable X et la zone (p. ex., âge*zone ou taille*zone) indique des pentes significativement différentes. Dans les cas où les pentes ne sont pas significativement différentes (c.‑à‑d. que le terme d’interaction n’est pas significatif), cela indique que les droites de régression sont à peu près parallèles. Si l’on prend comme exemple une ANCOVA du poids selon l’âge, des pentes parallèles indiqueraient que le gain de poids en fonction de l’âge est semblable pour les deux zones. Dans cet exemple, l’étape suivante consiste à appliquer le modèle ANCOVA et à tester les différences de moyennes ajustées (élévation) pour vérifier, si à un âge donné, les poissons sont proportionnellement plus lourds dans une zone que dans l’autre.
Il est possible que les pentes des régressions diffèrent. Par exemple, les poissons de la zone de référence peuvent prendre du poids plus rapidement en fonction de l’âge (pente plus forte) que les poissons de la zone exposée. Si les pentes de régression sont significativement différentes, on ne peut pas mener à bien l’ANCOVA. Dans ce cas, si on prend l’exemple du poids selon l’âge, l’effet ne serait pas une différence proportionnelle de poids à un âge donné, mais plutôt un taux d’augmentation du poids en fonction de l’âge qui est significativement différent d’une zone à l’autre. Ceci est considéré comme un effet significatif dans le cadre de l’étude des poissons pour l’ESEE. L’effet serait ici déterminé comme une différence significative des pentes entre les zones plutôt qu’une différence significative de l’ordonnée à l’origine. Dans une telle situation, il serait aussi intéressant de tracer séparément les droites de régression pour obtenir une meilleure compréhension qualitative de la relation du poids en fonction de l’âge pour chaque zone, sur toute l’étendue de variation de la covariable X (p. ex., où les lignes se coupent-elles?). Il faut noter que, même quand les pentes de régression diffèrent significativement d’une zone à l’autre, il reste possible de faire des comparaisons supplémentaires sur une plage particulière de valeurs de la covariable X (c.‑à‑d. une plage particulière d’âges ou de tailles) (Sokal et Rohlf, 1995). Ce genre de comparaison serait approprié si l’on juge que cette plage d’âge ou de taille est particulièrement préoccupante.
Il est aussi préférable que la plage de valeurs de la variable indépendante soit à peu près la même pour chaque « traitement » (c.-à-d. zone). Cela peut être difficile à réaliser en pratique, mais il faut tenir compte de tout non‑respect de cette prémisse lors de l’interprétation des résultats de tels cas. Par exemple, si l’étendue des valeurs de la taille utilisée comme covariable X pour la zone de référence ne chevauche pas beaucoup celle de la zone exposée, l’utilisation des résultats de l’ANCOVA nécessite la condition que les pentes de régression seraient toujours parallèles dans la portion de chevauchement des intervalles, et n’est peut-être pas appropriée dans cette situation.
8.3.3.2.5 Autres possibilités lorsque les droites de régression ne sont pas parallèles
Lorsque la condition des droites de régression parallèles n’est pas satisfaite, on ne peut pas effectuer une ANCOVA, car il est impossible d’interpréter correctement les moyennes ajustées des traitements. Dans ce cas, il y a une interaction de la covariable avec le traitement, et les différences de la variable dépendante entre les traitements varient pour diverses valeurs de la covariable. Il existe quelques solutions de remplacement permettant de traiter les cas de droites de régression non parallèles dans l’ANCOVA. Ces solutions sont présentées ci-dessous dans l’ordre dans lequel elles devraient être appliquées aux jeux de données avec pentes non parallèles. Les deux premières fournissent des techniques permettant de traiter les droites comme si elles étaient parallèles, ce qui permet de réaliser une ANCOVA complète et une comparaison des moyennes ajustées. La troisième solution est une méthode de remplacement pour calculer les effets mesurés lorsque les droites ne peuvent pas être traitées comme étant parallèles, même après avoir appliqué les deux premières solutions.
1. Points influents (de Barrett et al., 2010)
Les points influents sont des observations qui ont une grande influence sur le calcul (valeurs aberrantes dans l’espace de la covariable) et qui ont le potentiel de dominer les conclusions en raison de leur forte incidence sur les coefficients de régression (Fox, 1997). Si un ou plusieurs points ont une grande influence sur la pente d’une droite de régression et causent le non-parallélisme des droites, la suppression de ce ou ces points pourrait éliminer ce qui empêche d’ajuster les données au modèle parallèle. Le degré d’influence peut être évalué au moyen de la statistique de distance de Cook (Cook, 1977, 1979), qui est intégrée à de nombreux logiciels de calcul statistique. Elle est calculée en utilisant des résidus studentisés (valeurs aberrantes de la variable dépendante) et une mesure de l’importance de l’incidence nommée « valeur hat » (valeurs aberrantes de la variable prédictive) comme mesure de l’incidence de chaque observation (Fox, 1997). Un tracé de la distance de Cook en fonction de la covariable s’avère très utile pour identifier les observations qui ont une grande influence. Un seuil de démarcation numérique à 4/(n–k–1), où n est le nombre total d’observations et k est le nombre de variables prédictives dans le modèle de régression, peut aussi être utilisé afin d’évaluer les observations à grande infuence (Fox, 1997).
2. Coefficients de détermination (de Barrett et al., 2010)
Le coefficient de détermination (R2) exprime la proportion de la variabilité totale de la variable dépendante expliquée par sa relation linéaire avec la variable indépendante et constitue une mesure de l’association entre les deux variables (Quinn et Keough, 2002). Lorsque les pentes de régression ne sont pas parallèles, le coefficient de détermination du modèle de régression complet (qui inclut le terme d’interaction) peut être comparé avec le R2 du modèle de régression réduit (modèle dont le terme d’interaction est supprimé). Lorsque le R2 du modèle parallèle (réduit) est élevé (supérieur à 0,8), mais à peine inférieur à celui du modèle complet (différence de moins de 0,02), le modèle parallèle fournit une représentation suffisante des données, et peut être utilisé pour effectuer l’analyse.
3. Estimation des effets pour diverses tailles de poissons (de Lowell et Kilgour, 2008)
Lorsque les deux méthodes ci-dessus ne peuvent être appliquées au jeu de données (c.‑à‑d. lorsque les pentes demeurent non parallèles même après avoir appliqué les deux méthodes ci-dessus), on peut utiliser la méthode suivante pour estimer les effets mesurés pour les poissons plus petits (ou plus jeunes) ou plus grands (ou plus vieux). On détermine d’abord les valeurs minimales et maximales de la covariable dans la plage de chevauchement de la covariable des deux régressions (zones de référence et zone exposée). On détermine ensuite les valeurs prévues de la variable dépendante pour la droite de régression de chaque zone, pour ces deux valeurs de covariables (minimum et maximum). Une estimation de l’effet pour la valeur minimale de la covariable (c.-à-d. l’effet subi par les poissons plus petits ou plus jeunes) sera la différence entre les valeurs prévues, soit la valeur prévue de la zone exposée moins la valeur prévue de la zone la référence, exprimée en pourcentage de la valeur prévue de référence. Si les données ont subi une transformation logarithmique, on doit calculer l’antilogarithme (c.‑à‑d. x exprimé en 10x) des valeurs prévues avant de calculer le pourcentage de différence. Le calcul est le même pour les poissons de grande taille (ou plus vieux), mais on utilisera la valeur maximale de la covariable dans la plage de chevauchement des valeurs des deux zones. On peut alors comparer chacun de ces deux effets mesurés (pourcentage de différence pour les poissons petits ou jeunes et pour les poissons de grande taille ou plus vieux) avec les seuils critiques d’effet (SCE) de la même manière que pour les effets mesurés calculés à partir de moyennes (d’ANOVA) ou de moyennes ajustées (d’ANCOVA).
8.3.3.2.6 Méthodes non paramétriques de l’analyse de covariance
L’ANCOVA est robuste face au non-respect des conditions d’application du test lorsque les tailles des échantillons sont approximativement égales (Huitema, 1980; Hamilton, 1977). Lorsqu’il y a une violation importante des conditions et que les tailles des échantillons sont inégales, le recours à des méthodes non paramétriques au lieu de l’ANCOVA peut être envisagé. Plusieurs techniques non paramétriques qui utilisent les rangs ont été proposées. Iman et Conover (1982) ont proposé une solution non paramétrique dans laquelle la variable dépendante et la covariable sont remplacées par leur rang respectif. L’analyse est alors effectuée de la même manière que l’ANCOVA paramétrique en utilisant les rangs comme données; il s’agit de la solution non paramétrique la plus simple. Des groupes de rangs liés sont remplacés par le rang moyen de chaque groupe. Shirley (1981) et Quade (1967) présentent d’autres méthodes non paramétriques.
8.3.4 Transformations
La transformation des données peut souvent aider à améliorer la normalité et à uniformiser les variances (atténue le non-respect des conditions d’application des tests). Un examen de la relation entre les moyennes et les variances peut aider à trouver le type de transformation le plus approprié (Green, 1979). La loi de la puissance de Taylor (Taylor, 1961), qui examine la relation entre les moyennes des traitements et les variances, peut être utilisée pour déterminer les transformations spécifiques pour normaliser les données ou homogénéiser les variances (Green, 1979). Les transformations logarithmiques sont souvent adoptées parce que les mesures biologiques sont fréquemment considérées comme suivant une échelle logarithmique ou exponentielle (Peters, 1983). On notera qu’il ne faut pas ajouter 1 aux valeurs avant de d’effectuer une transformation logarithmique des données aux fins de l’ESEE, car cela aurait des effets indésirables sur les variances calculées lorsqu’on change les unités de mesure. Si les transformations ne parviennent pas à produire des données qui satisfont approximativement aux conditions, il peut être nécessaire d’avoir recours à des statistiques non paramétriques.
8.3.5 Niveau de réplication
Pour chacune des analyses par ANOVA et ANCOVA, le nombre de répétitions (taille de l’échantillon, n) correspond au nombre de poissons récoltés. La taille minimale de l’échantillon recommandée est de 20 poissons sexuellement matures par sexe (et un supplément de 20 poissons sexuellement immatures si on échantillonne des espèces de petite taille) pour chacune des deux espèces sentinelles et pour chaque zone exposée et de référence. Si l’on dispose de données appropriées, une analyse de puissance devrait être effectuée pour déterminer la taille de l’échantillon.
8.3.6 Critères d’effet et d’appui
8.3.6.1 Taille selon l’âge
Les taux de croissance sont souvent exprimés par la relation entre la taille (poids ou longueur) et l’âge. Pendant toute la durée de vie d’un poisson, cette relation est généralement curviligne, le taux d’accroissement déclinant à mesure que le poisson approche de la limite de sa durée de vie (Ricker, 1975). Puisque l’échantillonnage vise souvent uniquement les poissons adultes, il est impossible de calculer le taux de croissance selon l’approche classique. Toutefois, aux fins du Programme d’ESEE, la croissance peut être déduite à partir des estimations de la taille selon l’âge établies pour chaque zone à l’aide de l’ANCOVA. Aux fins de ce calcul, on suppose que la relation entre la taille et l’âge d’un poisson adulte est approximativement log-linéaire (log de la taille en fonction du log de l’âge) (Bartlett et al., 1984).
La taille selon l’âge peut être estimée en calculant la régression entre la taille du corps (poids ou longueur) et l’âge pour chaque zone d’échantillonnage (zone de référence et zone exposée). Il est recommandé d’utiliser la longueur et le poids pour calculer la taille selon l’âge, car il est alors possible de déterminer laquelle de ces deux mesures fournit la meilleure régression (dont la valeur du R2 est la plus élevée).
8.3.6.2 Poids des gonades, poids du foie, condition et fécondité
Le poids relatif des gonades et du foie (ainsi que la fécondité) sont calculés par régression et analysés au moyen de l’ANCOVA en utilisant le poids corporel comme covariable. De même, la condition est obtenue en calculant la régression de la relation entre le poids et la longueur du poisson, et elle reflète essentiellement le degré d’adiposité des poissons dans chaque zone.
Divers indices ont été utilisés en biologie halieutique pour décrire la condition des poissons (Bolger et Connolly, 1989). Le calcul du rapport d’une variable à une autre a été utilisé pour en dériver un grand nombre. Voici des exemples d’indices couramment utilisés:
- coefficient de condition (k) = 100 × (poids corporel/longueur3);
- indice gonadosomatique (IGS) = 100 × (poids des gonades/poids corporel);
- indice hépatosomatique (IHS) = 100 × (poids du foie/poids corporel).
Toutefois, les chercheurs sont devenus, de façon générale, plus prudents lorsqu’ils utilisent des variables dérivées et des rapports de variables, parce que ceux-ci peuvent présenter des propriétés statistiques indésirables (Green, 1979; Jackson et al., 1990). Bien que ces indices puissent être utilisés à des fins d’information, il est préférable, sur le plan statistique, d’estimer (et d’analyser) les paramètres à partir des droites de régressions calculées pour les variables originales (c.‑à‑d. ANCOVA) plutôt que les rapports (Gibbons et al., 1993).
8.3.6.3 Âge moyen
Le calcul de l’âge moyen fournit une approximation de la distribution de l’âge des poissons adultes prélevés dans chacune des zones. Il est possible d’estimer la variabilité de l’âge moyen des poissons grâce à l’ANOVA. L’erreur quadratique moyenne (EQM) du modèle est la meilleure estimation de la variabilité. Il est aussi possible d’analyser de cette façon les différences de longueur et de poids entre les sites. Il est indispensable d’uniformiser l’emploi des dispositifs d’échantillonnage d’une zone à l’autre, car la plupart des méthodes d’échantillonnage sont sélectives pour certaines classes d’âge.
8.3.6.4 Âge à la maturité
L’âge à la maturité est un paramètre souvent utilisé en biologie halieutique. Cependant, rares sont les méthodes de calcul qui comportent une mesure du niveau de confiance ou de variabilité statistique. Par conséquent, il est conseillé de procéder à l’estimation de l’âge à la maturité en utilisant une analyse traditionnelle des probits, analogue à celle de la détermination des concentrations létales médianes (CL50), dans les essais de toxicité. En déterminant la proportion (pourcentage) d’individus sexuellement matures dans chaque classe d’âge adulte, et après conversion de ces données en probits (ou tracé de ces données sur le papier probit), on obtient une relation linéaire (probit sur log de l’âge), qui permet d’estimer l’âge auquel 50 % des poissons échantillonnés sont sexuellement matures. On peut obtenir une estimation de la variabilité de l’âge à la maturité entre les poissons à partir de la pente de la droite. La pente estime le rapport 1/écart-type. Par conséquent, l’écart-type est estimé par le rapport 1/pente. En utilisant les données recueillies au cours de plusieurs phases, on peut calculer les limites de confiance sous forme d’estimations de la précision et de comparaisons statistiques des valeurs pour chaque zone. La plupart des logiciels de statistiques peuvent convertir les pourcentages en probits, et il existe plusieurs petits logiciels conçus pour effectuer l’analyse CL50//probits et générer des limites de confiance. Pour plus de renseignements sur l’analyse par la méthode des probits, voir Hubert (1980). Pour connaître les facteurs à considérer dans l’utilisation de la méthode des probits et d’autres méthodes en vue d’estimer l’âge à la maturité, consulter Trippel et Harvey (1991).
8.3.7 Analyse statistique de l’échantillonnage non létal
En ce qui concerne l’échantillonnage non létal, les distributions de fréquence des longueurs devraient être comparées au moyen du test de Kolmogorov-Smirnov (K-S) pour deux échantillons. Gray et al. (2002) ont analysé les jeunes de l’année séparément, afin d’évaluer la variabilité des taux de croissance selon l’âge.
Le test de K-S est une analyse robuste qui permet de déterminer si deux séries de données diffèrent de manière significative; il peut être utilisé pour étudier les distributions relatives des données. Il s’agit d’un test non paramétrique permettant d’estimer la similarité de deux fonctions de distribution cumulative de deux bases de données (Sokal et Rohlf, 1995) :
H0: F(X) = F(Y); H1: F(X) ≠ F(Y)
Les différences sont considérées comme significatives lorsque p < 0,05.
L’ANOVA peut être effectuée sur la longueur et le poids. Il peut être nécessaire de transformer les données. Au besoin, une analyse post hoc des différences entre les sites peut être effectuée au moyen du test HSD (Honestly Significant Difference) de Tukey.
L’ANCOVA devrait être effectuée pour la taille en fonction de l’âge (si possible) et pour le coefficient de condition (longueur par rapport au poids, par site). Les analyses devraient déterminer l’existence de régressions significatives et d’une interaction significative entre les zones. Si les pentes sont égales, les données devraient être examinées pour déterminer la différence entre les zones, déterminer quelle zone présente les plus grandes valeurs, le pourcentage de différence entre les zones, et la valeur de p pour la pente ou les différences moyennes ajustées. S’il y a une interaction, présenter les données sous forme de graphique pour voir s'il est possible de les interpréter.
8.3.8 Assurance et contrôle de la qualité des données et analyse (erreurs et valeurs aberrantes)
Des directives sur l’AQ/CQ pour l’analyse des données se trouvent plus bas. L’importance d’assurer la qualité des données ne peut être trop soulignée. Chaque chapitre où ces aspects sont pertinents donne des instructions complémentaires sur l’AQ/CQ dans la conception de l’étude, l’uniformité des méthodes et des mesures et la définition des protocoles et des procédures.
Parmi les divers types d’erreurs fréquemment commises lors de la saisie des données, mentionnons les erreurs de transcription, telles que l’inscription de la mauvaise espèce, du mauvais sexe ou stade de développement et de valeurs décimales erronées ou tronquées. Il est indispensable d’examiner les données afin de repérer les données erronées ou aberrantes avant d’entreprendre l’analyse des données. Les erreurs d’entrée ou de transcription et les données non valides sont impossibles à détecter dans les rapports finaux.
Il est parfois facile de repérer les erreurs de saisie en utilisant des graphiques de dispersion de la longueur en fonction du poids, du poids en fonction du poids des gonades et du poids en fonction du poids du foie pour la recherche des valeurs aberrantes. Les erreurs de saisie sont relativement faciles à corriger et peuvent être entrées à nouveau. S’il est impossible de régler le problème à cause d’erreurs ou d’omissions évidentes dans le fichier original de données, il faudrait exclure les individus en cause (point de données) de la série de données.
Les erreurs et les valeurs aberrantes contribuent à accroître la variance et réduisent la puissance pour détecter des différences significatives dans l’ensemble de données. Pour évaluer les données aberrantes, il faut examiner les données brutes, les conditions de terrain et le processus de collecte des données. Des points de données différents, mais qui ne sont pas dus à des erreurs de saisie, peuvent apparaître pour diverses raisons. Par exemple, un certain nombre de poissons peuvent sembler malades ou endommagés ou présenter des caractéristiques aberrantes sans raison apparente, ou encore les données aberrantes peuvent refléter un phénomène important qui fait partie de la réponse aux agents de stress à l’étude.
Dans le premier cas, il se peut qu’un petit nombre de poissons soient effectivement malades ou aient subi des dommages (d’une façon qui n’a aucun rapport avec les agents de stress à l’étude), et ils devraient être exclus de l’ensemble de données pour l’interprétation. Ces données apparaissent généralement comme des points isolés par rapport à l’ensemble de données principal. Il peut s’agir, par exemple, de poissons dont la queue a été amputée par un prédateur ou qui présentent une malformation ou une blessure à la mâchoire nuisant à leur alimentation, ou encore de poissons qui sont devenus aveugles à cause d’une blessure et qui sont plus maigres que les autres. Dans ces situations, les spécimens devraient être retirés de la comparaison.
Si la présence de données aberrantes rares ne peut être expliquée, il faudrait effectuer les analyses avec et sans les observations suspectes en vue de déterminer leur impact sur les conclusions. Si ces observations influent sur le fait qu’une relation soit significative ou non, il faut se reporter aux manuels de statistique pour déterminer s’il convient de les inclure ou non dans les analyses.
Enfin, dans le troisième cas, plusieurs poissons sont nettement différents, mais pourraient quand même faire partie de la relation étudiée. Chez d’autres poissons, la maturation sexuelle peut être retardée par des agents de stress environnementaux. Dans un tel cas, plusieurs poissons apparaîtraient comme des données aberrantes. Tel qu’il a été mentionné plus haut, il est recommandé d’effectuer les analyses en incluant dans un premier temps les données aberrantes (pour vérifier s’il y a des différences entre les sites), puis en les excluant (pour déterminer si ces poissons présentent un niveau de développement des gonades normal).
Parfois, il arrive également que certains poissons d’une population soient différents, par exemple s’ils sautent une année de fraie. Si l’un des objectifs de l’étude est d’évaluer les impacts sur la fraie, l’analyse devrait permettre d’examiner séparément les impacts potentiels sur les reproducteurs et sur les non‑reproducteurs. Les spécimens qui sautent une saison de reproduction se reconnaissent habituellement comme des données aberrantes négatives dans un tracé du poids des gonades en fonction du poids corporel, ce qui signifie que la distribution des résidus de l’ANCOVA présentera une asymétrie vers la gauche et ne suivra pas une distribution normale. Ces individus devraient être exclus des analyses des variables associées à la reproduction et, possiblement, des analyses de toutes les variables. Les réductions de variance ainsi réalisées vont généralement compenser toute perte de puissance causée par la réduction de la taille de l’échantillon. Si les femelles qui sautent une année de reproduction sont exclues des analyses, leur exclusion devrait être effectuée de façon objective (Environnement Canada, 1997). De plus, la fréquence des individus sautant une saison de reproduction dans la zone de référence et dans la zone exposée devrait être fournie, au cas où cette caractéristique serait liée à l’exposition. Il est beaucoup plus difficile d’identifier les mâles qui sautent une année de reproduction (s’il se trouve que ce phénomène se produit).
8.4 Effets sur l’exploitabilité des ressources halieutiques
L’examen du potentiel d’utilisation des ressources halieutiques a pour but de déterminer si l’effluent a eu des répercussions sur les poissons au point de limiter leur utilisation par les humains. L’exploitabilité des poissons peut être affectée par une modification de l’apparence, une altération du goût ou de l’odeur, ou des concentrations de contaminants dans les tissus qui dépassent les lignes directrices pour la consommation humaine et les concentrations mesurées dans la zone de référence. Le tableau 8-5 présente les critères d’effet et d’appui et les statistiques appropriées (ou lignes directrices) qui s’appliquent à l’exploitabilité des ressources halieutiques.
| Variable | Méthode statistique | |
|---|---|---|
| Critère d’effets1 | Contaminants dans les tissus des poissons (mercure) | ANOVA, et évaluation comparative avec les lignes directrices sur les concentrations dans les tissus |
| Critère d’appui2 | Anomalies physiques | Khi-carré (un test pour chaque classe d’anomalies; le nombre de tests dépendra du nombre de classes d’anomalies présentes chez les poissons capturés) |
| Altération | ANOVA |
1 Les critères d’effets utilisés afin de déterminer « l’effet », soit le dépassement des lignes directrices sur les concentrations dans les tissus. Des différences significatives sur le plan statistique entre les zones de référence et les zones d’exposition peuvent aussi être pertinentes (REMM, annexe 5, alinéa 9c).
2 Ces analyses sont effectuées à des fins informatives, et les différences significatives entre les zones de référence et les zones exposées ne sont pas nécessairement utilisées pour indiquer un effet.
8.4.1 Mercure dans les tissus de poissons
L’une des méthodes servant à évaluer le potentiel d’utilisation des poissons consiste à mesurer les concentrations de contaminants préoccupants dans les tissus des poissons prélevés dans la zone exposée et la zone de référence. Les contaminants peuvent être jugés préoccupants s’ils sont présents dans l’effluent et si des seuils pour la consommation humaine sont fixés dans des directives au sujet de ces contaminants. Les habitudes locales de consommation et les pêches commerciales devraient indiquer quelles sont les espèces de poissons et les tissus comestibles (p. ex. foie, reins, os, chair ou même poisson entier) à analyser. Le chapitre 3 donne des détails sur les méthodes permettant de déterminer si certains contaminants devraient être recherchés dans les analyses. Cette décision dépend en partie des données recueillies antérieurement sur les concentrations de contaminants dans les tissus des poissons et dans l’effluent.
Les mines sont tenues de mesurer les concentrations de mercure dans les tissus des poissons si elles détectent du mercure dans l’effluent (durant la caractérisation de l’effluent – chapitre 5) à une concentration dépassant 0,10 mg/L. Aux termes du REMM, un effet sur les tissus des poissons signifie des mesures de la concentration du mercure total dans les tissus de poissons, prises dans la zone exposée, supérieures à 0,5 µg/g (poids humide), présentant une différence statistique et ayant une concentration plus élevée par rapport à celles mesurées dans les tissus de poissons prises dans la zone de référence. Parmi les autres contaminants préoccupants liés aux mines de métaux pour un site particulier, on retrouve le cuivre, le zinc, le manganèse, le cyanure, le radium et l’uranium.
Le chapitre 3 recommande d’effectuer des analyses des tissus sur cinq échantillons composites (chacun composé d’au moins huit poissons) d’une seule espèce (de préférence du même sexe) pour chacune des zones. La taille d’échantillon (n) pour l’ANOVA est donc de cinq. La répétition serait alors suffisante pour permettre de détecter une ampleur de l’effet de ± 2 ET à une puissance = 0,9, si a et b sont fixés à 0,1 (voir la section 3.0). Il faut donc accorder beaucoup d’attention à l’ampleur de l’effet à retenir pour un contaminant préoccupant particulier, et déterminer si des répétitions supplémentaires se justifient. Si on établit que des tailles moindres de l’effet (c.-à-d. moins de 2 ET) ou des niveaux de puissance plus élevés seraient mieux adaptés au contaminant, il sera nécessaire d’accroître la taille de l’échantillon en analysant un plus grand nombre d’échantillons composites.
Le pourcentage de lipides et le pourcentage d’eau doivent être rapportés pour chaque échantillon de tissus. Ces données n’ont toutefois qu’une valeur d’information, pour aider à l’interprétation des données, et des différences statistiques dans les pourcentages de lipides ou d’eau ne constituent pas un effet.
8.4.2 Anomalies physiques
L’exploitabilité des ressources halieutiques peut être affectée par une modification de leur apparence. Les données recueillies pendant les études de suivi biologique doivent être utlisées pour identifier le sexe des poissons capturés et indiquer la présence de toute lésion, tumeur et de tout parasite ou de toute autre anomalie (REMM, annexe 5, alinéa 16b)). Les anomalies évidentes comprennent :
- des tumeurs ou des lésions à la surface du corps (ce qui inclut les yeux, les lèvres, le museau, les branchies);
- des malformations de la colonne vertébrale;
- des nageoires usées, effrangées ou hémorragiques;
- d’autres malformations physiques;
- des parasites visibles.
Pour chaque classe d’anomalies signalée, il faudrait effectuer une comparaison entre les poissons de la zone de référence et de la zone exposée à l’aide d’un test du khi-carré de la qualité de l’ajustement pour les fréquences relatives. Cette information sert à mieux interpréter les effets, bien que, aux fins de l’ESEE, une différence significative ne signale pas nécessairement un effet. Le nombre de tests statistiques nécessaires dépendra du nombre de classes d’anomalies notées chez les poissons capturés. La taille de l’échantillon aura été déterminée par le nombre de poissons prélevés pour l’étude des poissons. Cohen (1988) donne des indications sur la puissance d’un test du khi-carré qui serait obtenue à ce niveau de répétition.
8.5 Évaluation et interprétation des données sur la communauté d’invertébrés benthiques
Les données recueillies pendant l’étude de la communauté d’invertébrés benthiques doivent être utilisées pour déterminer les indicateurs d’effet suivants (REMM, annexe 5, sous-alinéa 16a)(iii)) :
- densité totale des invertébrés benthiques;
- indice de régularité;
- richesse des taxons;
- indice de similarité (indice de Bray-Curtis).
Les indicateurs d’effet ci-dessus doivent être utilisés pour déterminer les différences significatives sur le plan statistique entre les zones de référence et les zones exposées ou le long d’un gradient d’exposition. Voir le chapitre 4 pour plus de renseignements sur ces indicateurs d’effet. La moyenne, la médiane, l’écart-type, l’erreur type et les valeurs minimales et maximales sont déterminés pour chacun critère d’effet pour les zones d’échantillonnage. De plus, une analyse des résultats sera utilisée afin de déterminer s’il y a une différence statistique entre les zones d’échantillonnage pour chacun des indicateurs d’effet (REMM, annexe 5, sous-alinéa 16c)).
8.5.1 Plans d’étude et méthodes statistiques
Le tableau 8-6 définit les méthodes statistiques appropriées s’appliquant à l’analyse de chacun des plans d’étude recommandés. Voir le chapitre 4 pour obtenir plus de renseignements sur ces plans d’étude. À la différence de l’étude des poissons, la méthode statistique employée pour déterminer la présence d’un effet dépend du plan d’étude choisi parmi les sept plans possibles. Pour une étude donnée, les quatre indicateurs d’effet sont analysés à l’aide de la même méthode statistique, déterminée par le plan d’étude. La seule exception est l’approche des conditions de référence, qui utilise d’autres méthodes statistiques qui ne nécessitent pas de comparaisons de ces quatre indicateurs entre les zones, à moins qu’elle ne soit accompagnée d’ANOVA; les méthodes pour ce plan d’étude sont décrites ci-après et dans le chapitre 4.
| Plan d’étude | Méthode statistique |
|---|---|
| Contrôle-impact (C-I) | ANOVA |
| Contrôle-impact multiple (C-IM) | ANOVA |
| Avant-après–contrôle-impact (BACI) | ANOVA |
| Gradient linéaire (GL) | Régression/ANOVA |
| Gradient radial (GR) | Régression/ANOVA |
| Gradients multiples (GM) | ANCOVA |
| Approche des conditions de référence (ACR) | Multivariable/ANOVA |
Note : Des analyses multivariables des données recueillies à l’aide d’un des plans énumérés ci-dessus peuvent être effectuées pour distinguer des tendances qui peuvent être utiles pour déterminer des zones potentiellement préoccupantes. Dans certaines circonstances, l’ANCOVA peut aussi être appropriée pour ces plans d’étude (p. ex., pour éliminer l’effet d’une variable environnementale de confusion).
Bien qu’il soit possible d’utiliser l’ANOVA pour analyser les données recueillies dans la plupart des plans d’étude mentionnés au tableau 8-6, l’ANOVA s’applique surtout aux plans contrôle-impact (C-I) et contrôle-impact multiple (C-IM). Le plus simple de ces plans est le plan C-I (ou référence-exposition). Dans les rivières, par exemple, cela consiste à définir une zone de référence (généralement en amont), et une ou plusieurs zones exposées en aval. Le chapitre 4 propose différentes façons de concevoir les plans C-I. Dans ce type de plan d’étude, l’ANOVA est utilisée pour comparer la zone de référence et la zone exposée, une différence significative signalant un effet.
Le plan C-IM est semblable au plan C-I, à la différence qu’il emploie des zones de référence additionnelles qui sont situées dans des bassins versants ou des baies adjacents où l’habitat échantillonné est comparable à celui de la zone exposée. Ce type de plan aide à atténuer les problèmes posés par les facteurs de confusion (p. ex., quand une zone de référence unique diffère d’une zone exposée sur le plan de plusieurs variables environnementales, en plus de l’influence de l’effluent). Comme dans le cas du plan C-I, une différence significative entre une zone exposée et la moyenne des zones de référence, déterminée par l’ANOVA, signalerait un effet.
L’ANCOVA peut aussi être utilisée pour les plans C-I et C-IM pour tenir compte des covariables qui pourraient créer un « bruit de fond » rendant difficile la comparaison des zones de référence et d’exposition avec l’ANOVA. Par exemple, sans l’application de l’ANCOVA, les différences de profondeur entre les stations pourraient masquer les différences liées à l’effluent pouvant exister entre les zones d’exposition et de référence. Cette situation peut survenir lorsque les indicateurs mesurés dans l’étude de la communauté d’invertébrés benthiques changent le long d’un gradient croissant de profondeur et qu’il est impossible de prélever les échantillons à des profondeurs identiques. Dans cet exemple, l’ANCOVA peut être utilisée pour éliminer l’effet de la covariable « profondeur » afin de mettre en évidence l’effet de l’exposition à l’effluent. Cette même approche peut être employée avec d’autres covariables influant sur les indicateurs des invertébrés benthiques le long d’un continuum.
Les plans C-I et C-IM peuvent être améliorés lorsque des données sont recueillies avant et après le début du rejet de l’effluent dans le milieu récepteur. Ce type de plan de suivi a été nommé « avant-après–contrôle-impact » (BACI, de before/after-control/impact) (Schmitt et Osenberg, 1996). Son utilisation aide à distinguer les effets de l’effluent par rapport aux différences naturelles entre les zones de référence et les zones exposées qui existaient déjà avant le rejet de l’effluent.
Dans sa forme la plus simple, un plan BACI nécessite la collecte de données de suivi au moins une fois avant et une fois après le début du rejet de l’effluent dans une zone de référence et dans une zone exposée, puis les données sont analysées par ANOVA factorielle superfie-temps (Green, 1979). Dans cette situation, l’existence d’un effet de l’effluent est inférée quand le terme d’interaction superficie-temps dans l’ANOVA est significatif. Quand les zones de référence et exposée ont été échantillonnées de manière répétée pendant la période avant et la période après le rejet, il est possible de recourir à une analyse BACI pour séries appariées; dans ce cas, les effets potentiels sont étudiés en analysant le changement de la valeur de delta (différence entre les zones de référence et les zones exposées), de la période avant à la période après le rejet (Schmitt et Osenberg, 1996). Il est possible d’améliorer ce plan en intégrant plusieurs zones de référence (Schmitt et Osenberg, 1996; Underwood, 1997).
À la différence des plans C-I et C-IM, le plan par gradient linéaire (GL) et le plan par gradient radial (GR) se prêtent mieux à l’analyse de régression. Les conditions d’application de l’analyse de régression s’appliquent aussi à l’analyse des données des communautés d’invertébrés benthiques; elles ont déjà été décrites dans la section 8.3.3.2, dans la discussion portant sur l’ANCOVA (la régression est une composante de l’ANCOVA).
Pour plus de renseignements sur les plans d’étude, voir les chapitres 2 et 4.
8.5.2 Traitement des données
Comme pour l’étude des poissons, les données doivent être présentées sous forme de graphiques et de tableaux pour chaque zone présentée (zones de référence et exposées). Les données fournies doivent inclure les statistiques descriptives (moyenne, médiane, écart-type, erreur type et les valeurs minimales et maximales), ainsi que la taille des échantillons. Les données provenant de plans par gradient doivent être présentées sous forme de diagrammes de dispersion des variables en fonction de la distance par rapport au point de rejet de l’effluent. Pour les plans par gradient sans « zones » bien définies, une présentation sous forme de tableau avant l’analyse principale serait applicable aux statistiques sommaires par station, l’unité d’échantillonnage étant alors le sous-échantillon de terrain plutôt que la station. Les statistiques sommaires par station devraient aussi être présentées pour les plans de type contrôle-impact dans les cas où les sous-échantillons de terrain ne sont pas regroupés avant l’identification des taxons, bien que les principales statistiques sommaires utilisées pour déceler un effet soient celles calculées pour les zones entières (afin de faciliter l’interprétation des différences significatives [« effets »] entre les zones).
Les mêmes trois principales étapes d’analyse décrites à la section 8.3.3 devraient être suivies pour déterminer si des « effets » statistiquement significatifs se sont produits :
- Les données devraient être examinées pour déterminer si elles satisfont aux conditions d’application du test ou de la méthode statistique employée (ANOVA, ANCOVA, régression ou analyses multivariables).
- La méthode statistique appropriée est appliquée après l’examen des données et leur transformation, le cas échéant (ou application d’une méthode non paramétrique).
- Les principaux résultats pour les indicateurs d’effet devraient alors être présentés de façon à indiquer clairement si un effet statistique a été observé, en indiquant les détails sur la nature de l’effet (dont sa direction et son ampleur). Là encore, un effet statistique est signalé si la valeur de p est inférieure à la valeur dea déterminée a priori, selon les directives de la section 8.6.
Les mêmes considérations statistiques et contraintes présentées dans la section 8.3.3 pour l’ANOVA et l’ANCOVA s’appliquent aussi aux analyses des communautés d’invertébrés benthiques effectuées avec ces deux méthodes statistiques. Ainsi, l’examen, l’analyse et l’interprétation des données lorsqu’on utilise l’ANOVA ou l’ANCOVA pour l’étude de la communauté d’invertébrés benthiques devraient suivre les recommandations générales présentées à la section 8.3.3.
Les plans par gradient sont particulièrement utiles 1) dans les situations où la dilution rapide de l’effluent empêche la sélection d’une zone exposée présentant des concentrations d’effluent relativement homogènes, et 2) pour déterminer sur quelle distance le long de la trajectoire de l’effluent les effets sont observés (c.-à-d. déterminer l’étendue géographique des « effets »). L’étendue géographique des « effets » peut être déterminée graphiquement en traçant un diagramme de la ou des variables dépendantes en fonction de la distance du point de rejet de l’effluent, et en examinant les données pour repérer un point d’inflexion où la variable converge de façon asymptotique vers la condition de référence. Les données des stations d’échantillonnage ainsi organisées pourraient aussi être utilisées, avec les données physicochimiques mesurées, dans une analyse multivariable (p. ex., ordination ou groupement) utilisée pour identifier les stations éloignées qui tendent à se regrouper avec les stations de référence, et celles qui se regroupent avec des stations nettement perturbées.
Ces deux approches (représentation graphique et analyse multivariable) recherchent des tendances dans les données pour déterminer qualitativement l’étendue géographique approximative d’un effet. Il ne s’agit pas de tests d’hypothèses; par conséquent, dans le contexte du Programme d’ESEE, ces approches ne servent pas à signaler un effet avec une certitude suffisante pour justifier des mesures d’intervention, mais elles sont plutôt utiles à des fins d’information.
Néanmoins, il est possible d’effectuer des tests statistiques pour certains gradients. Dans le cas le plus simple, un effet statistiquement significatif serait attesté si la pente de la régression d’une variable en fonction de la distance du point de rejet de l’effluent est significativement différente de zéro, ou si le coefficient de corrélation est statistiquement significatif (il peut être nécessaire de transformer les données pour satisfaire aux conditions de linéarité). Dans ce cas, l’effet est un gradient relativement uniforme de valeurs de la variable à partir du point de rejet de l’effluent, plutôt qu’un effet dans une zone distincte donnée.
Un effet peut aussi être signalé par l’existence d’une différence significative entre la zone exposée et la zone de référence déterminée par ANOVA en comparant un groupe de stations le long du gradient proche de la mine à des stations de « référence » situées le long du gradient éloigné de la mine. Cette démarche est analogue à l’approche C-I, et suppose un certain degré d’uniformité de l’exposition au sein du groupe de stations exposées et au sein du groupe de stations de « référence ». En outre, les deux groupes de stations doivent être assez éloignés pour présenter des différences nettes d’exposition, et il faut que le nombre de stations dans chaque groupe soit suffisant pour atteindre le degré souhaité de puissance. En se fondant sur l’analyse de puissance dont il est question dans la section suivante, la recommandation initiale est de sélectionner au moins cinq stations plutôt uniformes situées près de l’effluent (zone fortement exposée à l’effluent) et cinq autres stations suffisamment uniformes et éloignées de l’effluent pour être considérées comme étant représentatives d’une zone de référence (impact minimal de l’effluent). Si des stations sont ajoutées entre ces deux groupes, un total d’au moins 15 stations sera nécessaire pour couvrir tout le gradient.
Quelle que soit la méthode d’analyse utilisée, la puissance statistique est habituellement améliorée lorsqu’on augmente le nombre de stations (répétition) aux deux extrémités du gradient. Il est également important de prolonger le gradient suffisamment loin de la mine (dans la mesure du possible) afin de permettre l’échantillonnage de stations les moins perturbées possible (équivalent à des stations de « référence »).
Si l’on dispose d’un nombre suffisant de sous-échantillons par station, il est aussi possible d’utiliser l’ANOVA pour déterminer la présence ou l’absence d’un effet à une station donnée. Cela suppose que les sous-échantillons de terrain sont utilisés comme répétitions (on traite alors les stations comme des zones), et que les comparaisons par ANOVA sont effectuées station par station le long du gradient, en partant des stations fortement exposées à l’effluent, jusqu’aux stations de référence les plus éloignées. Cette méthode d’analyse peut servir à déterminer l’endroit sur un gradient où un effet disparaît à un niveau de signification a donné. Cette approche peut toutefois nécessiter un effort d’échantillonnage considérable, selon le nombre de stations le long du gradient et le nombre de sous-échantillons requis par station d’après l’analyse de puissance.
Dans les cas où ces types de tests statistiques ne sont pas adéquats pour un plan par gradient donné, il sera nécessaire de revoir la conception du programme de suivi de façon à assurer que les analyses statistiques appropriées puissent être appliquées pendant la prochaine étude de suivi. Le plan révisé peut comporter un plus grand nombre de réplicats ciblant les zones (ou stations) exposées et de référence clés qui doivent être comparées (p. ex., augmentation des réplicats dans la zone la plus fortement exposée à l’effluent et dans la zone la moins exposée à l’effluent représentant le mieux les conditions de référence).
Dans certains cas, il peut être nécessaire de comparer les gradients de la zone exposée aux gradients de la zone de référence. C’est le cas lorsqu’un gradient environnemental coexistant (covariable) (non lié à la mine) vient confondre les effets de l’effluent dans la zone exposée. À l’aide d’un plan par gradients multiples, il est alors possible d’effectuer des comparaisons statistiques entre le gradient de la zone exposée et un gradient environnemental similaire (non lié à la mine) dans une zone de référence non exposée. La profondeur et l’habitat du gradient de référence devraient être aussi similaires que possible à ceux du gradient de la zone exposée. Il faudrait tester les « effets » potentiels de l’effluent en utilisant l’ANCOVA pour comparer les élévations des droites de régression (moyennes ajustées) de la zone de référence et de la zone exposée tout en tenant compte de l’influence de la covariable environnementale .
Par exemple, si le gradient d’exposition à l’effluent à partir de la mine était caractérisé par une augmentation simultanée de la profondeur, on pourrait effectuer une comparaison par ANCOVA avec une zone de référence où le gradient de profondeur est le même. Si les pentes des régressions de la zone de référence et de la zone exposée en fonction de la covariable (X = profondeur) sont à peu près égales, alors une différence significative des moyennes ajustées indiquerait un « effet » de l’effluent sur l’indicateur d’effet Y (p. ex., la richesse taxonomique). Encore une fois, la section 8.3 fournit des détails sur la réalisation des ANCOVA et sur les différentes façons d’utiliser ces analyses pour déterminer la présence d’un effet.
8.5.3 Approche des conditions de référence
L’approche des conditions de référence (ACR) est un plan d’étude qui combine l’examen de tendances multivariables dans les données à des évaluations visant à déterminer si les stations exposées se retrouvent à l’extérieur d’une ellipse de probabilité pour les stations de référence. Le concept fondamental de l’ACR est l’établissement d’une base de données de stations qui représentent des conditions non perturbées (stations de référence), où des variables biologiques et environnementales sont mesurées. Cette base de données sert à élaborer des modèles prédictifs qui associent un ensemble de variables environnementales à des conditions biologiques. Une fois les modèles mis au point, une série de mesures environnementales peuvent être effectuées à une nouvelle station, puis ces mesures sont utilisées dans le modèle afin de prévoir les conditions biologiques à cette nouvelle station. La comparaison de la condition biologique réelle de la nouvelle station (zone exposée) avec les conditions existant aux stations de référence auxquelles la nouvelle station appartient selon les prévisions du modèle permet d’évaluer s’il existe un effet à la station exposée.
La base de données sur les conditions de référence est établie au moyen d’un programme d’échantillonnage normalisé mis en œuvre à des échelles spatiales très diverses. Le même protocole d’échantillonnage des macroinvertébrés benthiques est utilisé dans le plus grand nombre possible d’écorégions et d’ordres de cours d’eau ou de lacs dans un bassin versant. Un certain nombre de variables environnementales sont mesurées pendant l’échantillonnage des invertébrés. Les données recueillies sont ensuite soumises à une analyse multivariable à trois étapes dans le cadre de laquelle :
- un certain nombre de groupes d’invertébrés sont définis d’après la similarité de la structure des communautés;
- les données biologiques sont corrélées avec des variables environnementales, et un ensemble optimal de variables environnementales permettant de prédire la répartition dans les divers groupes est établi;
- la condition biologique des stations exposées est évaluée en utilisant l’ensemble optimal de variables environnementales est utilisé pour prévoir la répartition dans les divers groupes.
La qualité de l’ajustement de la station exposée au groupe auquel elle a été assignée par le modèle détermine si elle diffère du groupe de référence et, le cas échéant, l’ampleur de la différence. Si une station ou un groupe de stations se retrouvent à l’extérieur de l’ellipse de probabilité déterminée statistiquement pour les stations de référence, cela indique la présence d’un effet. Les limites de l’ellipse de référence devraient être fixées a priori à partir de certaines des considérations présentées à la section 8.6. On trouvera un examen plus complet des hypothèses, des méthodes et de l’interprétation de l’ARC dans Reynoldson et al. (1995, 2000) et Bailey et al. (2003).
Il faut en outre noter que selon le calendrier et la localisation d’un programme d’échantillonnage ARC, il est aussi possible de se servir de la base de données obtenue pour faire des comparaisons par ANOVA entre la zone de référence et la zone exposée en vue de déterminer s’il y a eu un effet. Ce type d’analyse serait analogue à un plan C-IM.
En résumé, une procédure globalement semblable à celle qui est décrite à la fin de la section 8.3 devrait aussi être suivie (avec les modifications nécessaires) pour l’étude de la communauté d’invertébrés benthiques. Cependant, l’analyse de puissance ne s’applique pas aux méthodes graphiques ni à l’ACR. Par conséquent, les études qui utilisent l’ACR devraient être conçues de manière à effectuer une détermination exacte et précise des conditions de référence afin de maximiser les probabilités de détection des écarts par rapport aux conditions de référence aux stations d’exposition, lorsqu’il y en a. Une étude ACR peut comprendre les éléments suivants :
- préparation des analyses : AQ/CQ (y compris la vérification des erreurs de saisie des données), sommaire des facteurs de confusion, description du plan d’échantillonnage et du niveau taxonomique retenu, identification précise des unités d’échantillonnage utilisées pour les comparaisons statistiques (p. ex., stations plutôt que sous-échantillons), vérification de l’équivalence des substrats et des techniques d’échantillonnage entre les différentes zones de référence et exposées qui sont comparées;
- statistiques sommaires (présentation sous forme de graphiques et de tableaux des moyennes, etc., tel qu’il est décrit plus haut);
- analyses statistiques (tests d’hypothèses) pour déterminer les « effets » (ANOVA, ANCOVA, régression);
- méthodes graphiques (p. ex., inspection de la forme des droites de régression; utilisées pour examiner les tendances dans les données plutôt que pour déterminer des « effets »);
- analyses statistiques multivariables servant à déterminer a) les tendances dans les données et b) la position dans un espace multidimensionnel des stations exposées par rapport aux ellipses de probabilité des stations de référence; dans ce cas, seul b) peut servir à déterminer les « effets »;
- analyses de puissance (ne s’appliquent pas aux méthodes graphiques ni à l’ARC).
8.5.4 Critères d’appui
Les critères d’appui suivants devraient aussi être présentés pour les communautés d’invertébrés benthiques, accompagnés de la moyenne, de la médiane, de l’écart-type, de l’erreur type, des valeurs minimales et maximales et de la taille d’échantillon :
- indice de diversité de Simpson;
- densité des taxons (p. ex., famille);
- abondance relative des taxons (p. ex., famille);
- présence/absence des taxons (p. ex., famille).
À la différence des critères d’effets (densité totale des invertébrés benthiques, indice de régularité, richesse des taxons et indice de similarité), les critères d’appui sont inclus à titre de variables complémentaires et ne font pas l’objet d’analyses statistiques pour déterminer des « effets ». Ces variables peuvent toutefois servir à interpréter les effets à des étapes ultérieures (p. ex., déterminer l’ampleur et les causes des « effets »). Elles devraient être présentées sous forme de graphiques et de tableaux pour chaque zone étudiée (zones de référence et zones exposées). Il faut noter qu’il peut exister d’autres descripteurs qui pourraient aussi être utiles pour l’interprétation des données de suivi, en fonction de chaque site (voir l’analyse de Resh et al., 1995).
8.6 Rôle de l’analyse de puissance, de α, de β et du seuil critique d’effet pour déterminer les effets
8.6.1 Établissement de α et β
Lorsque des tests statistiques sont réalisés pour déterminer si les zones exposées diffèrent de façon significative des zones de référence, une faible probabilité d’erreur de type I (α) est généralement fixée, de telle sorte qu’une population ou une communauté normale ne soit pas prise à tort pour une population ou une communauté perturbée. Toutefois, le programme de suivi doit aussi être conçu de façon à offrir une probabilité raisonnablement élevée de détecter statistiquement un seuil critique d’effet (SCE) prédéterminé, le cas échéant. En d’autres termes, la puissance du test doit être élevée. La puissance correspond à 1 – β, β étant l’erreur de type II (voir ci-dessous).
En établissant une grande marge de variation autour de ce qui est considéré normale (non perturbé), le risque de commettre une erreur de type I est en partie réduit. Il faut aussi consacrer un effort d’échantillonnage suffisant pour réduire l’erreur de type II, en tenant compte de la faible probabilité allouée pour l’erreur de type I. Ainsi, pour déterminer l’effort d’échantillonnage nécessaire, il faut prendre en compte et fixer a priori le SCE, l’erreur de type I et l’erreur de type II. Il faut donc prendre des décisions sur la grandeur acceptable des erreurs de type I et de type II pour déterminer la puissance, et donc pour fixer l’effort d’échantillonnage nécessaire pour détecter le SCE recommandé.
L’erreur de type I (probabilité α) est l’erreur qui se produit quand l’hypothèse nulle, selon laquelle il n’y a aucun effet, est rejetée alors qu’en fait elle est vraie (p. ex., une zone exposée est déclarée différente de la zone de référence alors que ce n’est pas le cas).
On commet une erreur de type II (probabilité β) quand l’hypothèse nulle est acceptée alors qu’elle est fausse (p. ex., si la zone exposée est déclarée comme n’étant pas significativement différente de la zone de référence alors qu’elle est réellement touchée). Par conséquent, α constitue le risque pour l’industrie, et β le risque pour l’environnement.
La puissance d’un test statistique est donc 1 – β, la probabilité associée au fait de rejeter à juste titre l’hypothèse nulle quand elle est fausse (p. ex., la probabilité associée à l’identification correcte d’une zone touchée). Dans un programme de suivi bien conçu avec un nombre de répétitions appropriées, le but est de maintenir α et β bas, et la puissance élevée.
Comme le montre l’équation présentée plus loin dans cette section, une façon d’accroître la puissance, étant donné un effort d’échantillonnage fixe (c.-à-d. la taille de l’échantillon), consiste à accroître α. En d’autres termes, il faut faire des compromis lorsqu’on fixe α et β. Traditionnellement, α a été fixé à 0,05 pour les études expérimentales où, dans de nombreux cas, le coût d’une erreur de type II n’est pas particulièrement élevé. Cela signifie qu’une valeur α de 0,05 est habituellement utilisée dans les situations où la principale préoccupation est d’avoir le maximum de confiance qu’un effet statistiquement significatif est réel. Par ailleurs, il y a beaucoup moins de consensus et de publications sur ce qui constitue un niveau approprié pour β. Certaines études ont proposé d’utiliser une puissance minimale de 0,8 (c.-à-d. β = 0,2) (Alldredge, 1987; Cohen, 1988; Burd et al., 1990; Osenberg et al., 1994; Keough et Mapstone, 1995).
Dans de nombreux cas, cette « règle empirique » remonte aux travaux fondamentaux de Cohen sur l’analyse de puissance (voir Cohen, 1988), qui étaient principalement axés sur des applications en sciences du comportement. Pour ce type d’applications, Cohen soutenait que les erreurs de type I devaient vraisemblablement être plus graves que les erreurs de type II dans les cas où la préoccupation principale était de ne pas propager des conclusions erronées fondées sur des déclarations incorrectes de différences significatives. Plus précisément, le chercheur a posé que, si l’on devait considérer les erreurs de type I comme quatre fois plus graves, il serait raisonnable de fixer α à la valeur traditionnelle (pour les études expérimentales) de 0,05 et de fixer β à 4 × 0,05 = 0,2. Il a toutefois signalé que cette règle empirique ne devrait pas être utilisée dans d’autres types d’études où ces hypothèses ne sont pas valides.
Cette mise en garde s’applique aux études de suivi environnemental où, à cause du coût potentiellement élevé (tant écologique que financier) de la non-détection d’impacts négatifs, de nombreux chercheurs du domaine de la biosurveillance soutiennent que a devrait être fixé au moins au même niveau que β (p. ex., Alldredge, 1987; Underwood, 1993; Mapstone, 1995). En d’autres termes, on a souvent soutenu que, sauf circonstances atténuantes, le risque pour l’environnement ne devrait pas être fixé à un niveau plus élevé que le risque pour l’industrie. Le point de départ le plus raisonnable consisterait donc à fixer α = β, et c’est la position adoptée par le Programme d’ESEE. Toutefois, selon les conditions propres à chaque site, il faut parfois décider 1) de fixer α > β si l’on peut montrer que le risque pour l’environnement est plus préoccupant que le risque pour l’industrie, ou 2) de fixer α < β si l’on peut montrer que le risque pour l’industrie est plus préoccupant.
Après avoir décidé d’établir α = β, il est nécessaire de prendre une décision quant à la valeur appropriée de α et β. Dans de nombreux cas, la décision doit être prise en tenant compte de la puissance souhaitée pour le test, du SCE que le programme est conçu pour détecter, et des incidences sur l’effort d’échantillonnage. Ce processus décisionnel peut être illustré par un exemple portant sur l’étude de la communauté d’invertébrés benthiques (tableau 8-7). Dans cet exemple, on examine les effets de différentes valeurs de α et β sur la taille de l’échantillon afin de détecter un SCE égal à ± 2 ET en utilisant l’équation de l’analyse de puissance ci-dessous. Celle-ci fournit la taille approximative de l’échantillon (n) en une étape pour le plan C-I le plus simple pour l’ANOVA (voir aussi des détails supplémentaires dans la section qui suit) (Guenther, 1981; Alldredge, 1987) :
n = (2(Zα + Zβ)2(ET/SCE)2) + 0.25(Zα)2
où :
- n = taille de l’échantillon
- Zα = variable normale centrée réduite pour un niveau de signification α (erreur de type I)
- Zβ = variable normale centrée réduite pour un niveau de signification β (erreur de type II)
- ET = écart-type
- SCE = seuil critique d’effet
| α | 1-β | |||
|---|---|---|---|---|
| 0,99 | 0,95 | 0,90 | 0,80 | |
| 0,01 | 14 | 11 | 10 | 8 |
| 0,05 | 11 | 8 | 7 | 5 |
| 0,10 | 9 | 7 | 5 | 4 |
S’appuyant sur le tableau 8-7 (et sur la recommandation spécifiant que l’étude de la communauté d’invertébrés benthiques devrait au minimum avoir une puissance suffisante pour détecter un SCE de ± 2 ET), le groupe de travail sur les invertébrés benthiques a recommandé de fixer au départ α et β à 0,1. Cela signifiait que, dans la plupart des cas, l’effort d’échantillonnage nécessiterait une taille d’échantillon de 5, valeur qui se trouve dans la plage employée dans de nombreuses études sur le benthos (Resh et McElravy, 1993). Les calculs de l’analyse de puissance pour l’ANOVA de base indiquent aussi que α et β peuvent être fixés à 0,1 pour les critères d’effet de l’étude des poissons, avec très peu d’effet (comparativement à α = 0,05, β = 0,2) sur la taille de l’échantillon nécessaire pour obtenir le niveau de puissance recherché (1 – β). L’utilisation d’un niveau de α ou de β autre que 0,1 nécessiterait une justification appropriée de la part du promoteur ou de l’agent d’autorisation (p. ex., fixer une valeur plus basse et plus rigoureuse pour l’erreur de type II [β] quand le risque pour l’environnement est jugé plus préoccupant). Il peut aussi être nécessaire de consulter l’agent d’autorisation dans les cas où l’analyse de puissance recommande d’avoir recours à des tailles d’échantillon anormalement élevées.
Il faut aussi noter au tableau 8-7 que, si l’on augmente la taille de l’échantillon, il est possible d’obtenir des erreurs de type I et II plus basses (α et β plus bas), tout en maintenant α égal à β. Par exemple, on peut fixer α et β à 0,05, ce qui donne une puissance de 95 % pour détecter un SCE de ± 2 ET, en augmentant la taille de l’échantillon à 8 (tableau 8-7). Le même argument s’applique à d’autres composantes de l’ESEE (p. ex., l’étude des poissons et l’exploitabilité du poisson) pour divers SCE souhaités, mais les tailles d’échantillon nécessaires seront alors différentes. Le fait d’établir α = β constitue donc une incitation économique à mettre en œuvre un programme de suivi bien conçu et comportant les répétitions nécessaires, ce qui permettra de réduire la probabilité de commettre des erreurs de type I (c.-à-d. que a est maintenu bas), réduisant ainsi la probabilité de mener des études complémentaires qui ne sont pas nécessaires. En outre, étant donné que a est lié à b, la capacité du programme de suivi à détecter des effets réels sera aussi accrue. Cette amélioration du plan de suivi permettra de mieux comprendre, le cas échéant, quels types d’effets se produisent.
8.6.2 Analyse de puissance : détermination de la taille d’échantillon requise, de la puissance et du seuil critique d’effet approprié
L’analyse de puissance sert deux grands objectifs pendant l’ESEE :
- au début d’une étude de suivi (a priori), pour calculer l’effort d’échantillonnage (taille de l’échantillon) qui sera nécessaire pour détecter un SCE donné à un niveau de puissance donné;
- à la fin d’une étude de suivi (post hoc), pour déterminer le niveau de puissance qui a réellement été atteint.
Ces deux fonctions de l’analyse de puissance sont brièvement abordées dans les paragraphes suivants en vue de clarifier la relation qui existe entre elles.
8.6.2.1 Calcul de la puissance a priori
Pendant la phase initiale de la planification d’une ESEE, l’analyse de puissance peut être utilisée pour déterminer la taille de l’échantillon requise pour effectuer un test permettant de détecter un effet correspondant à un SCE déterminé avant l’échantillonnage. À l’aide du SCE, de la probabilité d’erreur de type I (α), de la probabilité d’erreur de type II (β) et d’une estimation de la variabilité dans la zone de référence (p. ex., écart type pour la zone de référence), et en posant certaines hypothèses sur la distribution des données analysées, il est possible de concevoir une stratégie d’échantillonnage scientifiquement valable. L’analyse ci-dessous décrit la procédure la plus simple (c.-à-d. pour un plan C-I pour ANOVA ou ANCOVA) pour déterminer la taille d’échantillon nécessaire. La taille de l’échantillon correspond au nombre de poissons pour l’étude des poissons et au nombre de stations pour l’étude de la communauté d’invertébrés benthiques. Dans les cas où la taille d’échantillon nécessaire calculée pour un critère d’effet (p. ex., densité des invertébrés; condition) est supérieure à celle calculée pour un autre critère (p. ex., richesse des taxons d’invertébrés; poids relatif des gonades), il faut retenir la taille d’échantillon la plus grande (à moins que, comme on l’a vu plus haut, la consultation de l’agent d’autorisation n’ait confirmé que cette décision entraînerait des tailles d’échantillon excessivement élevées).
Après que le SCE a été déterminé, que les niveaux de α et β ont été choisis et que l’ET pour le site de la mine à l’étude a été estimé, ces données sont entrées dans l’équation de l’analyse de puissance pour calculer la taille de l’échantillon nécessaire pour détecter un impact de l’ampleur du SCE entre ou dans les zones, à un niveau de puissance donné. Lorsque le SCE est établi à ± 2 ET, en raison de l’annulation de termes, il n’est pas nécessaire de déterminer l’ET pour l’analyse de puissance, et le tableau 8-7 ci-dessus présente les tailles d’échantillon précalculées pour diverses valeurs de α et β.
Il faut noter que la détermination de la taille d’échantillon requise suppose que la variabilité entre les répétitions dans la zone exposée est semblable à celle entre les répétitions dans la zone de référence. Bien que l’ANOVA soit relativement robuste en cas de non-respect des conditions de normalité des données, si la variance dans une zone exposée est beaucoup plus élevée (ou plus faible) que celle de la zone de référence, les comparaisons par ANOVA ne seront pas nécessairement appropriées, à moins qu’on ne puisse homogénéiser les variances par transformation des données. Dans les cas où les variances de la zone exposée et de la zone de référence restent significativement différentes même après la transformation, l’analyse de puissance décrite ici peut surestimer ou sous-estimer le nombre de stations d’échantillonnage nécessaire. Des tests non paramétriques pourraient être appropriés dans ce cas; une analyse de puissance non paramétrique serait alors nécessaire pour estimer l’effort d’échantillonnage (Thomas et Krebs, 1997).
Pour un plan C-I de base pour l’ANOVA ou l’ANCOVA, la taille d’échantillon jugée nécessaire pour détecter un SCE donné à un niveau de puissance donné peut se calculer en adaptant l’équation standard de l’analyse de puissance comme suit (Green, 1989) :
n = 2(tα + tβ)2 (ET/SCE)2
Où :
n = taille de l’échantillon
tα = valeur du t de Student (test bilatéral) à (n-1) degrés de liberté (d.l.), au niveau de signification α
tβ = valeur du t de Student (test unilatéral) à (n-1) d.l., au niveau de signification β
ET = écart-type
SCE = seuil critique d’effet, exprimé dans les mêmes unités de mesure que la variable dépendante
L’équation est résolue de façon itérative en choisissant une valeur approximative de n (habituellement 20 pour l’étude des poissons) pour trouver tα et tβ, puis en utilisant la solution pour trouver une valeur plus précise de n; la procédure est répétée jusqu’à ce qu’on arrive à une estimation finale pour n (voir la section A1-8 de l’annexe 1). Par ailleurs, l’équation présentée à la section 8.6.1 peut servir à déterminer approximativement n en une seule étape. Il existe des tableaux de valeurs précalculées de n (plus détaillés que le tableau 8-7) pour diverses valeurs de α, β et SCE (Alldredge, 1987; Cohen, 1988).
Le lecteur trouvera dans la documentation pertinente (p. ex., Cohen, 1988) des conseils sur l’analyse de puissance et des tableaux permettant de déterminer la taille de l’échantillon pour les plans d’étude utilisant la régression (gradient linéaire, gradient radial) et le test du khi-carré (analyse des anomalies physiques des poissons). Il existe également plusieurs logiciels pour faire l’analyse de puissance pour différents plans d’analyse statistique (Thomas et Krebs, 1997). Comme dans le cas d’un plan C-I de base, l’analyse de puissance pour ces autres plans nécessitera aussi une décision a priori sur la valeur appropriée du SCE. Pour les analyses de régression, Cohen (1988) fournit une table de conversion des SCE pour passer des unités d’ET à un coefficient de corrélation (r) et, dans certains cas, il peut être acceptable d’utiliser cette valeur de r pour calculer la taille approximative de l’échantillon nécessaire pour un plan par gradient de type régression. Par exemple, selon certaines hypothèses, l’auteur montre que l’utilisation d’un SCE de 2 ET équivaut à utiliser un r = 0,707 (ou r2 = 0,5). Bien que l’équivalence exacte dépende des hypothèses en cause, il peut être acceptable d’utiliser cette conversion (peut-être avec un facteur de correction) pour obtenir un SCE approximatif convenant à des analyses de type régression. Cohen (1988) fournit des tableaux permettant de trouver les tailles d’échantillon nécessaires pour diverses valeurs de r, α et β.
Les seuils critiques d’effet pour l’étude des poissons sont exprimés en pourcentage de la moyenne de référence, et ne sont pas représentés dans les unités de la variable dépendante, car l'ampleur de l’effet varierait d’une étude à l’autre. Par conséquent, le coefficient de variation (CV), exprimé en pourcentage de la moyenne de référence, (CV = écart-type/moyenne de référence × 100) est utilisé comme mesure de la variabilité dans le calcul de la taille de l’échantillon. Pour un plan C-I de base analysé par ANOVA pour l’étude des poissons avec des données non transformées (p. ex., pour le critère d’effet de l’âge), la taille d’échantillon estimée pour détecter une ampleur d’effet donnée à un niveau de puissance donné peut être calculée en utilisant une autre version de l’équation précédente. Cette équation est la suivante (Green, 1989) :
n = 2(tα + tβ)2 (CV/SCE)2
Où :
CV = coefficient de variation (exprimé en pourcentage en utilisant les données du site de référence)
SCE = seuil critique d’effet (exprimé en pourcentage de la moyenne de référence)
Pour un plan C-I de base analysé par ANCOVA avec des données soumises à une transformation logarithmique (p. ex., pour le critère d’effet du poids relatif des gonades), la taille d’échantillon estimée pour détecter un SCE donné à un niveau de puissance donné peut aussi être calculée en utilisant une autre version de l’équation ci-dessus. Cette équation est la suivante (Green, 1989) :
n = 2(tα + tβ)2 (ETz/SCEz)2
Où :
ETZ = écart-type des résidus obtenu en utilisant des données soumises à une transformation logarithmique
SCEZ = log(f + 1), où f = SCE est une fraction de la moyenne de référence (p. ex., pour un SCE de 25 % ⇒ f = 0,25)
Dans le cas des deux équations ci-dessus, la taille de l’échantillon doit être calculée au moyen d’un processus itératif en choisissant comme point de départ une valeur approximative de n comme il a été expliqué précédemment.
8.6.2.2 Analyses de puissance post hoc
Lorsqu’un programme d’échantillonnage est terminé, si un résultat non significatif a été obtenu, une analyse de puissance post hoc peut être utilisée pour calculer la puissance réelle disponible pour détecter un effet et le SCE minimal pouvant être détecté pour une puissance donnée (Quinn et Keough, 2002). Cet aspect est particulièrement important si certains des paramètres pertinents qui pourraient affecter la puissance (c.-à-d. n, α, SCE, ET) ont changé depuis le début de l’étude. De plus, ces calculs devraient être utilisés pour faire des recommandations sur la taille de l’échantillon pour la phase de suivi subséquent. Les calculs de puissance post hoc peuvent être effectués en réarrangeant les équations précédentes pour calculer tβ ou le SCE. Par exemple, pour calculer la puissance pour les deux équations précédentes, on obtient :
![]()
et
![]()
On peut ensuite obtenir la puissance à partir de la valeur calculée de tβ.
8.7 Seuils critiques d’effet
Afin que les efforts additionnels en matière de suivi soient axés sur les domaines appropriés, Environnement Canada a élaboré des seuils critiques d’effet pour les critères d’effet relatifs aux poissons et aux invertébrés benthiques. Consulter le tableau du chapitre 1 qui porte sur les seuils critiques d’effet pour obtenir d’autres renseignements.
8.8 Considérations statistiques pour les études en mésocosmes
Certaines considérations s’appliquent seulement à une étude de type mésocosme. Par exemple, le fait que les conditions expérimentales soient contrôlées se traduit vraisemblablement par une moindre variabilité dans les milieux de référence et d’exposition par rapport aux données de terrain. Il peut ainsi être possible d’atteindre des niveaux équivalents de puissance statistique en utilisant des tailles d’échantillon plus petites que celles utilisées sur le terrain. De même, il pourrait être possible d’atteindre des niveaux supérieurs de puissance ou de déceler des ampleurs d’effet plus petites tout en utilisant les mêmes tailles d’échantillon que celles qui sont employées sur le terrain. En fait, il peut même être souhaitable de disposer d’une puissance suffisante pour détecter de plus faibles ampleurs d’effet dans les études en mésocosme que dans les études de terrain, étant donné que les durées d’exposition sont généralement plus courtes dans les études en mésocosme. Cela signifie (si l’on utilise des chiffres hypothétiques) qu’un changement de 10 % induit par l’effluent sur une période d’exposition de 30 jours dans une étude en mésocosme peut être équivalent à un changement de 25 % sur une période beaucoup plus longue d’exposition sur le terrain.
De plus, étant donné que la mise en cage peut faire apparaître des phénomèmes parasites, il peut être nécessaire d’utiliser non pas des poissons pris individuellement comme unité d’échantillonnage pour la répétition (comme c’est le cas sur le terrain), mais de prendre les enclos expérimentaux (mésocosmes) comme unités d’échantillonnage. Ainsi, l’utilisation de seulement deux mésocosmes (un pour la référence et un pour l’exposition), contenant 20 poissons chacun, peut ne pas être valide parce qu’il n’est peut-être pas possible de séparer les effets de l’effluent des effets dus à des différences subtiles entre les enclos expérimentaux eux-mêmes. Il s’agit là d’un exemple d’effets de confusion potentiels dus à la pseudorépétition (Hurlbert, 1984).
En comparaison de l’étude des poissons, il peut être encore plus direct de substituer des études en mésocosme au suivi de la communauté d’invertébrés benthiques sur le terrain, tout au moins en ce qui concerne les plans et analyses statistiques. Comme dans le cas de l’étude des poissons, il faudrait alors suivre les mêmes étapes de préparation, de présentation et d’analyse des données. En outre, étant donné le cycle relativement court des changements de structure des communautés d’invertébrés à l’intérieur des mésocosmes, on peut envisager d’utiliser les mêmes critères d’effet que dans l’étude des invertébrés sur le terrain (section 8.5). Le plan d’étude le plus pertinent serait analogue au plan contrôle-impact (tableau 8-6), avec des comparaisons par ANOVA entre les mésocosmes répétés correspondant aux zones de référence et d’exposition. L’unité d’échantillonnage serait alors le mésocosme (ce qui est équivalent aux « stations » dans l’étude de terrain). Comme dans le cas des mésocosmes utilisés pour les poissons, le contrôle de la variabilité en conditions expérimentales peut permettre d’obtenir une plus grande puissance statistique ou de détecter de plus faibles ampleurs d’effet (en pourcentage de changement) en utilisant les mêmes tailles d’échantillon généralement utilisées sur le terrain. Cette augmentation de la précision est l’un des avantages les plus fréquemment cités de l’usage des mésocosmes par rapport à l’échantillonnage sur le terrain, et doit être évaluée par rapport au désavantage que représente une baisse potentielle de l’exactitude en raison de l’utilisation d’une simulation (aussi réaliste que possible) des conditions réelles de terrain.
Le chapitre 9 traite plus en détails de l’évaluation et de l’interprétation des données pour des méthodes de rechange.
8.9 Références
Alldredge, J.R. 1987. « Sample size for monitoring of toxic chemical sites », Environmental Monitoring and Assessment, 9 : 143-154.
Bailey, R.C., R.H. Norris et T.B. Reynoldson. 2003. Bioassessment of Freshwater Ecosystems Using the Reference Condition Approach. Boston (MA), Kluwer Academic Publishers.
Barrett, T.J., M.A. Tingley, K.R. Munkittrick et R.B. Lowell. 2010. « Dealing with heterogeneous regression slopes in analysis of covariance: New methodology applied to environmental effects monitoring fish survey data », Environmental Monitoring and Assessment, 166 (1-4) : 279-291.
Bartlett, J.R., P.F. Randerson, R. Williams et D.M. Ellis. 1984. « The use of analysis of covariance in the back-calculation of growth in fish », Journal of Fish Biology, 24 : 201-213.
Bligh, E.G., et W. Dyer. 1959. « A rapid method of total lipid extraction and purification », Canadian Journal of Biochemistry and Physiology, 37 : 911-917.
Bolger, T., et P.L. Connolly. 1989. « The selection of suitable indices for the measurement and analysis of fish condition », Journal of Fish Biology, 34 : 171-182.
Burd, B.J., A. Nemec et R.O. Brinkhurst. 1990. « The development and application of analytical methods in benthic marine infaunal studies », Advances in Marine Biology, 26 : 169-247.
Cohen, J. 1988. Statistical Power Analysis for the Behavioral Sciences, 2nd edition. Hillsdale (NJ), Lawrence Erlbaum Associates.
Cook, R.D. 1977. « Detection of influential observation in linear regression », Technometrics, 19 : 15-18.
Cook, R.D. 1979. « Influential observations in linear regression », Journal of the American Statistical Association, 74 : 169-174.
Day, R.W., et G.P. Quinn. 1989. « Comparisons of treatments after an analysis of variance in ecology », Ecological Monographs, 59 : 433-463.
Draper, N.R., et H. Smith. 1981. Applied Regression Analysis, 2nd edition. New York (NY), John Wiley & Sons, Inc.
Environnement Canada. 1997. Fish Survey Expert Working Group Report. Ottawa (ON), Environnement Canada. EEM/1997/6.
Folch, J., M. Lees et G.H. Sloane Stanley. 1957. « A simple method for the isolation and purification of total lipides from animal tissues », Journal of Biological Chemistry, 226 : 497-509.
Fox, J. 1997. Applied Regression Analysis, Linear Model, and Related Models. Thousand Oaks (CA), Sage Publications Inc.
Gibbons, D.W., J.B. Reid et R.A. Chapman. 1993. The New Atlas of Breeding Birds in Britain and Ireland: 1988–1991. London (UK), Poyser.
Gray, M.A., A.R. Curry et K.R. Munkittrick. 2002. « Non-lethal sampling methods for assessing environmental impacts using a small-bodied sentinel fish species », Water Quality Research Journal of Canada, 37 : 195-211.
Green, R.H. 1979. Sampling Design and Statistical Methods for Environmental Biologists. New York (NY), Wiley-Interscience.
Green, R.H. 1989. « Power analysis and practical strategies for environmental monitoring », Environmental Research, 50 : 195-205.
Grubbs, F. 1969. « Procedures for detecting outlying observations in samples », Technometrics, 11 : 1-21.
Guenther, W.C. 1981. « Sample size formulas for normal theory T tests », American Statistician, 35 : 243-244.
Hamilton, B.L. 1977. « An empirical investigation of the effects of heterogeneous regression slopes in analysis of covariance », Educational and Psychological Measurement, 37 : 701-712.
Hubert, J.J. 1980. Bioassay. Dubuque (IA), Kendall/Hunt Publishing.
Huitema, B.E. 1980. The Analysis of Covariance and Alternatives. New York (NY), John Wiley & Sons, Inc.
Hurlbert, S.H. 1984. « Pseudoreplication and the design of ecological field experiments », Ecological Monographs, 54 : 187-211.
Iman, R.L., et W.J. Conover. 1982. « A distribution-free approach to inducing rank correlation among input variables », Commun. Statist.-Simula. Computa., 11 : 311-334.
Jackson, D.A., H.H. Harvey et K.M. Somers. 1990. « Ratios in aquatic sciences: Statistical shortcomings with mean depth and the morphoedaphic index », Canadian Journal of Fisheries and Aquatic Sciences, 47 : 1788-1795.
Keough, M.J., et B.D. Mapstone. 1995. Protocols for Designing Marine Ecological Monitoring Associated with BEK Mills. Technical Report Series No. 11, National Pulp Mills Research Program. Canberra (AU), Commonwealth Scientific and Industrial Research Organisation.
Lowell, R.B., et B.W. Kilgour. 2008. « Interpreting effluent effects on fish when the magnitude of effect changes with size or age of fish », dans K.A. Kidd, R. Allen Jarvis, K. Haya, K. Doe et L.E. Burridge (éd.), Compes rendus du 34ième atelier annuel sur la toxicité aquatique: du 30 septembre au 3 octobre 2007, Halifax, Nouvelle-Écosse. Rapport technique canadien des sciences halieutiques et aquatiques, no 2793. Pp. 83-84.
Mapstone, B.D. 1995. « Scalable decision rules for environmental impact studies: Effect size, Type I and Type II errors », Ecological Applications, 5 : 401-410.
Miller, R.G. 1986. Beyond ANOVA: Basics of Applied Statistics. New York (NY), John Wiley & Sons, Inc.
Osenberg, C.W., R.J. Schmitt, S.J. Holbrook, K.E. Abu-Saba et A.R. Flegal. 1994. « Detection of environmental impacts: Natural variability, effect size and power analysis », Ecological Applications, 4 : 16-30.
Paine, R.T., M.J. Tegner et E.A. Johnson. 1998. « Compounded perturbations yield ecological surprises », Ecosystems, 1 : 535-545.
Peters, R.H. 1983. The Ecological Implication of Body Size. New York (NY), Cambridge University Press. 329 pages.
Quade, D. 1967. « Rank analysis of covariance », Journal of the American Statistical Association, 62 : 1187-1200.
Quinn, G.P., et M.J. Keough. 2002. Experimental Design and Data Analysis for Biologists. Cambridge (UK), Cambridge University Press.
Randall, R., H. Lee II, R. Ozretich, J. Lake et J. Pruell. 1991. « Evaluation of selected lipid methods for normalizing pollutant bioaccumulation », Environmental Toxicology and Chemistry, 10 :1431-1436.
Resh, V.H., et E.P. McElravy. 1993. « Contemporary quantitative approaches to biomonitoring using benthic macroinvertebrates », dans D.M. Rosenberg et V.H. Resh (éd.), Freshwater Biomonitoring and Benthic Macroinvertebrates. New York (NY), Chapman and Hall. Pp. 159-194.
Resh, V.H., R.H. Norris et M.T. Barbour. 1995. « Design and implementation of rapid assessment approaches for water resource monitoring using benthic macroinvertebrates », Australian Journal of Ecology, 20 : 108-121.
Reynoldson, T.B., K.E. Day et T. Pascoe. 2000. « The development of the BEAST: A predictive approach for assessing sediment quality in the North American Great Lakes », dans J.F. Wright, D.W. Sutcliffe et M.T. Furse (éd.), Assessing the Biological Quality of Fresh Waters: RIVPACS and Other Techniques. Ambleside (UK), Freshwater Biological Association. Pp. 165-180.
Reynoldson, T.B., R.C. Bailey, K.E. Day et R.H. Norris. 1995. « Biological guidelines for freshwater sediment based on BEnthic Assessment of SedimenT (the BEAST) using a multivariate approach for predicting biological state », Australian Journal of Ecology, 20 : 198-219.
Ricker, W.E. 1980. Calcul et interpretation des statistiques biologiques des populations de poissons. Bulletin canadien des sciences halieutiques et aquatiques. 191F. 409 p.
Schmitt, R.J., et C.W. Osenberg. 1996. Detecting Ecological Impacts: Concepts and Applications in Coastal Marine Habitats. San Diego (CA), Academic Press. 401 pages.
Shirley, E.A.C. 1981. « A distribution-free method for analysis of covariance based on ranked data », Applied Statistics, 30 : 158-162.
Sokal, R.R., et F.J. Rohlf. 1995. Biometry, 3rd edition. New York (NY), W.H. Freeman.
Thomas, L., et C.J. Krebs. 1997. « A review of statistical power analysis software », Bulletin of the Ecological Society of America, 78 : 126-139.
Trippel, E.A., et H.H. Harvey. 1991. « Comparison of methods used to estimate age and length of fishes at sexual maturity using populations of white sucker (Catostomus commersoni) », Canadian Journal of Fisheries and Aquatic Sciences, 48 : 1446-1495.
Underwood, A.J. 1993. « The mechanics of spatially replicated sampling programmes to detect environmental impacts in a variable world », Australian Journal of Ecology, 18 : 99-116.
Underwood, A.J. 1997. Experiments in Ecology: Their Logical Design and Interpretation using Analysis of Variance. Cambridge (UK), Cambridge University Press. 504 pages.
Annexe 1 : Guide étape par étape des procédures statistiques
- A1.1 Identification des poissons immatures
- A1.2 Statistiques sommaires
- A1.3 Analyse de variance
- A1.4 Analyse de covariance
- A1.5 Pentes non parallèles dans l’analyse de covariance
- A1.6 Analyse de covariance non paramétrique
- A1.7 Problèmes liés à la plage de valeurs de la covariable
- A1.8 Analyses de la puissance a priori
- A1.9 Analyses de la puissance post hoc
Annexe 1 : Guide étape par étape des procédures statistiques
La présente annexe donne des renseignements généraux et des instructions étape par étape au sujet des procédures statistiques requises pour l’étude des poissons de l’ESEE. Ces renseignements sont de nature générale, et ils peuvent être adaptés aux procédures du logiciel statistique utilisés. Les exemples sont tirés de divers jeux de données provenant des cycles précédents du programme d’ESEE des pâtes et papiers afin d’illustrer les principes lorsque c’est possible.
L’analyse de covariance (ANCOVA) peut être effectuée sous forme de régressions linéaires multiples où des variables indicatrices représentent les sites. En effectuant une analyse sur un site de référence (réf.) et un site exposé (exp.), les données peuvent être adaptées au modèle de régression suivant :
y = β0 + β1x1 + β2x2 + β3(x1 · x2)
(1)
où y est la variable dépendante, x1 est la covariable, x2 est une variable indicatrice pour le traitement (p. ex., 0 pour référence et 1 pour exposition), et x1 · x2 est le terme d’interaction covariable*traitement qui est égal au produit de la covariable et de la variable indicatrice pour chaque observation. Ce modèle ajuste les données à deux droites de régression ayant des ordonnées à l’origine et des pentes distinctes, soit y = β0 + β1x1 pour le site de référence et y = (β0 + β2) + (β1 + β3)x pour le site exposé. Un test vérifiant le parallélisme des pentes de régression équivaut à tester la signification statistique du coefficient du terme d’interaction x1 · x2 (c.-à-d. un test vérifiant si β3 = 0). Si ce coefficient n’est pas significatif (au niveau de signification α = 0,05), les données peuvent être décrites par deux lignes parallèles ayant des ordonnées à l’origine distinctes. Ce modèle est le suivant :
y = β0 + β1x1 + β2x2
(2)
Le test pour vérifier l’existence d’une différence de variable dépendante entre les traitements peut se faire avec le modèle (2). Ce test équivaut à vérifier si les deux droites de régression ont des ordonnées à l’origine égales (c.-à-d. qu’il vérifie si β2 = 0). Si la variable dépendante n’est pas significativement différente entre les traitements, les données peuvent être représentées par une seule droite de régression sans le terme β2.
L’analyse des données au moyen de l’ANCOVA équivaut à ajuster les données à (1) afin d’évaluer le parallélisme des pentes, et le test des différences entre les sites équivaut à tester la signification de β2 dans (2). Des comparaisons avec les seuils critiques d’effet sont effectuées en comparant le pourcentage de différence entre les moyennes ajustées (variable dépendante moyenne ajustée de manière à éliminer l’effet des différences de valeurs de la covariable) et des seuils critiques d’effet prédéterminés. Ce pourcentage de différence peut être calculé facilement à partir du modèle (2). Le coefficient β2 dans (2) est la distance verticale entre les deux droites de régression (c.-à-d. la différence entre les ordonnées à l’origine), et il peut être converti en pourcentage de différence entre les variables dépendantes comme suit :
% différence = (10β2 − 1) · 100%
(3)
lorsque la variable dépendante est soumise à une tranformation logarithmique. Les moyennes ajustées peuvent être calculées avec l’équation (2) en utilisant la moyenne générale de la covariable (valeurs moyenne de la covariable pour tous les sites) pour x1 et la valeur indicatrice appropriée pour x2 pour obtenir chacune des moyennes ajustées si on le souhaite.
A1.1 Identification des poissons immatures
- Calculer l’indice gonadosomatique (IGS) :
(IGS) = poids des gonades/poids corporel × 100.
Habituellement, les poissons immatures présentent un IGS < 1 %. - Tracer le diagramme du poids des gonades en fonction du poids corporel. Les poissons immatures peuvent habituellement être identifiés rapidement.
La figure A1-1 montre un jeu de données comportant plusieurs poissons immatures. Une droite représentant IGS = 1 % est ajoutée afin d’aider à l’identification des poissons immatures.
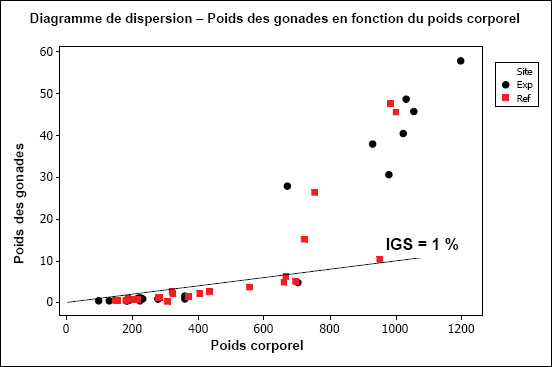
Figure A1-1 : Diagramme du poids des gonades en fonction du poids corporel de femelles de Catostomus macrocheilus. La ligne représente un IGS = 1 %. (description longue)
Certains poissons ne fraient pas chaque année et ne dépensent donc pas d’énergie chaque année pour la reproduction. On peut facilement identifier ces espèces au moyen d’un diagramme du poids des gonades en fonction du poids corporel dans lequel les données forment deux groupes différents correspondent aux poissons qui fraient et aux poissons qui ne fraient pas. Lorsque la droite correspondant à un IGS = 1 % est ajoutée au tracé, on peut facilement distinguer les poissons qui fraient de ceux qui ne fraient pas. Voir la figure A1-2.
Figure A1-2 : Diagramme du poids des gonades en fonction du poids corporel de femelles de Lota lota. La droite représente un IGS = 1 %. (description longue)
A1.2 Statistiques sommaires
- Les données sont séparées par espèces, sexes et sites (p. ex., de référence ou exposé).
- Chaque jeu de données est représenté graphiquement en utilisant un diagramme en rectangle et moustaches qui est examiné pour repérer les erreurs de saisie évidentes ou toute observation inhabituelle.
Les diagrammes en rectangle et moustaches de la longueur de femelles de Catostomus commersoni se trouvent à la figure A1-3. Le diagramme en A révèle la présence d’un poisson de longueur inhabituelle au site exposé. Un examen des notes de terrain et des commentaires dans la feuille de calcul indique que ce poisson était d’une longueur exceptionnelle comparativement à tous les autres poissons. Cette observation se trouve donc très loin hors de la plage des valeurs de la variable « longueur » et elle peut être considérée comme une valeur aberrante.
Figure A1-3 : Diagrammes en rectangle et moustaches de femelles de Catostomus commersoni par sites. A. Une valeur aberrante est détectée au site exposée. B. La valeur aberrante est supprimée. (description longue)
- Calculer et présenter les statistiques sommaires dans un tableau.
| Espèce | Sexe | Site | n | Moyenne | ET | Erreur type | Min. | Max. |
|---|---|---|---|---|---|---|---|---|
| Catostomus commersoni | F | Exp. | 39 | 437,49 | 24,57 | 3,93 | 395 | 496 |
| Catostomus commersoni | F | Réf. | 40 | 432,18 | 31,46 | 4,97 | 357 | 510 |
| Catostomus commersoni | M | Exp. | 39 | 405,36 | 19,72 | 3,16 | 367 | 448 |
| Catostomus commersoni | M | Réf. | 39 | 405,00 | 18,00 | 2,88 | 369 | 448 |
| Etheostoma exile | F | Exp. | 33 | 3,7492 | 0,349 | 0,0440 | 3,0 | 4,5 |
| Etheostoma exile | F | Réf. | 31 | 3,7129 | 0,556 | 0,0999 | 2,8 | 5,2 |
| Etheostoma exile | M | Exp. | 37 | 3,5973 | 0,295 | 0,0485 | 3,0 | 4,1 |
| Etheostoma exile | M | Réf. | 26 | 3,5346 | 0,277 | 0,0543 | 3,1 | 4,1 |
A1.3 Analyse de variance
- Tester la normalité de toutes les variables.
- Tester l’homogénéité de la variance de toutes les variables.
- Présenter tous les tests statistiques utilisés et la valeur de p de ces tests.
- En cas de divergence importante par rapport aux conditions d’application des tests ou s’il y a divergence et que les tailles des échantillons sont inégales, le recours à des méthodes statistiques non paramétriques pour remplacer l’ANOVA (p. ex., test de Kruskal-Wallis) pourra être envisagé.
- Fournir les moyennes (et les médianes pour les analyses non paramétriques), les écarts-types combinés et la valeur de p des tests.
- Tracer un graphique des résidus et vérifier la présence de valeurs aberrantes. Les observations dont les résidus studentisés sont supérieurs à 4 justifient habituellement un examen plus approfondi et peut-être leur suppression. Si des valeurs aberrantes sont supprimées, fournir une analyse portant sur toutes les données et une autre dont toute valeur aberrante est supprimée.
« Poids » - femelles de Catostomus commersoni
Normalité (testée en utilisant le test d’Anderson-Darling)
Homogénéité des variances (testée en utilisant le test de Levene)
Les conditions d’application des analyses statistiques sont satisfaites; poursuivre avec l’analyse de variance.
Variable dépendante : Poids
Résultats :
Écart-type combiné = 248,6
« Âge » - femelles de Catostomus commersoni
Normalité (testée en utilisant le test d’Anderson-Darling)
Homogénéité des variances (testée en utilisant le test de Levene)
La condition de normalité des données n’est pas respectée dans la zone de référence. Les tailles des échantillons sont respectivement de 40 (réf.) et de 39 (exp.). Les tailles des échantillons sont donc approximativement égales et il n’y a pas de violation grave des conditions d’application. L’ANOVA paramétrique ou une variante non paramétrique à l’ANOVA peuvent être utilisées. Dans le cas présent, un test non paramétrique de Kruskal-Wallis est employé.
Résultats :
« Longueur » – femelles de Catostomus commersoni
Diagramme des résidus – Résidus studentisés en fonction de l’ordre (les données d’ordre sont saisies dans la feuille de calcul).
Les valeurs aberrantes sont habituellement considérées comme des observations dont les résidus sont supérieurs à 4 et elles peuvent facilement être identifiées dans ce diagramme.
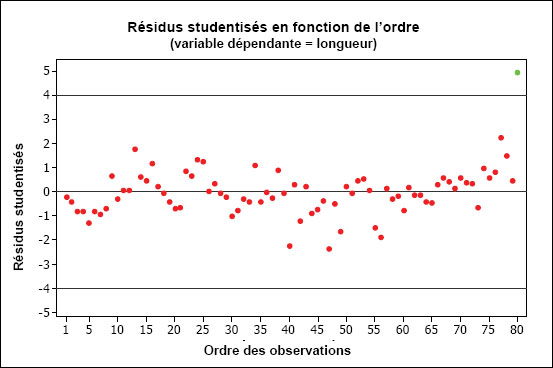
Figure A1-4 : Diagramme des résidus studentisés en fonction de l’ordre des observations (dans la feuille de calcul) pour l’ANOVA de la longueur de femelles de Catostomus commersoni (description longue)
A1.4 Analyse de covariance
- Tracer le diagramme de la variable dépendante en fonction de la covariable pour tous les sites.
- Examiner le tracé pour vérifier s’il y a une tendance linéaire et un chevauchement approprié des valeurs de la covariable.
- Examiner le tracé pour repérer les valeurs aberrantes – calculer les résidus studentisés du modèle ANCOVA.
- Évaluer l’exclusion des valeurs aberrantes dont la valeur est > 4 (résidus studentisés).
- Tester la normalité des résidus (chacune des droites de régression).
- Tester l’homogénéité de la variance des résidus (entre les droites de régression).
- Tester l’homogénéité des pentes de régression – ajuster les données au modèle de régression avec le terme d’interaction et tester la signification de ce terme. Fournir le coefficient de détermination R2 du modèle de régression.
- Tester les différences de la variable dépendante – ajuster les données au modèle de régression sans terme d’interaction et tester la signification du terme « site » (traitement). Fournir le coefficient de détermination R2 du modèle de régression et l’écart-type combiné (des résidus).
- Fournir les moyennes ajustées pour chaque site. Calculer aussi l’antilogarithme de la moyenne si les données transformées en logarithmes ont été utilisées.
- Calculer le pourcentage de différence, calculé en pourcentage du site de référence (en utilisant les antilogarithmes des moyennes ajustées).
« Condition » – mâles de Rhinichthys cataractae
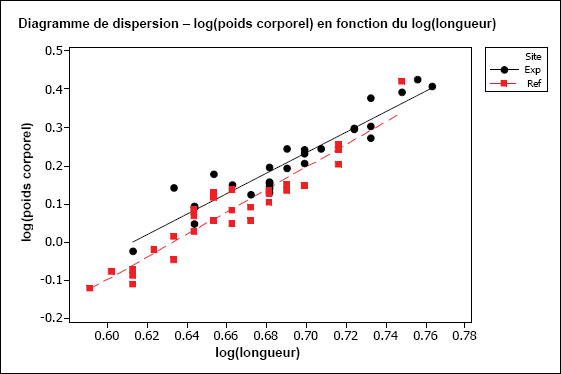
Figure A1-5 : Diagramme du log(poids corporel) en fonction du log(longueur) de mâles de Rhinichthys cataractae. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
Le chevauchement des valeurs de la covariable semble approprié et il y a une tendance linéaire.
Normalité (testée en utilisant le test d’Anderson-Darling)
Homogénéité des variances (testée en utilisant le test de Levene)
Homogénéité des pentes de régression
β3 n’est pas significatif (p = 0,337), par conséquent, il n’y a pas d’indication que les pentes sont non parallèles.
Tester les différences de la variable dépendante
β2 est significatif (p = 0,0001), il y a donc une différence de poids significative entre les sites.
Moyenne ajustée du poids – site de référence : 1,3113 g
Moyenne ajustée du poids – site d’exposition : 1,4496 g
(l’antilogarithme des moyennes est calculé pour obtenir les unités initiales au moment de la transformation en logarithme; l’antilogarithme de x est 10x si la transformation était en log10).
Écart-type combiné = 0,0420164
Pourcentage de différence = 10,54 % (calculé en pourcentage du site de référence en utilisant les moyennes ajustées)
A1.5 Pentes non parallèles dans l’analyse de covariance
- Méthode 1
- « Poids relatif des gonades » – mâles de Catostomus commersoni
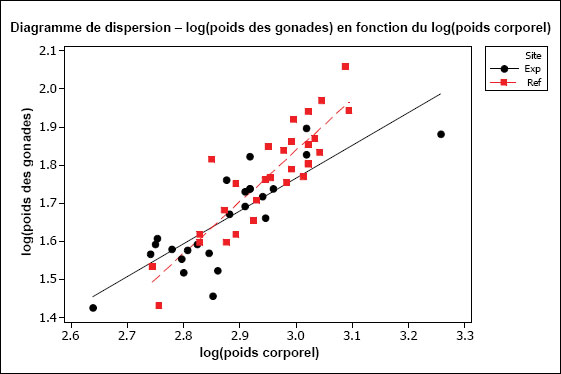
Figure A1-6 : Diagramme du log(poids des gonades) en fonction du log(poids corporel) de mâles de Catostomus commersoni. Les données sont ajustées à deux droites de régression distinctes, une pour chaque site. (description longue)
Le chevauchement des valeurs de la covariable semble approprié et il y a une tendance linéaire. Une observation justifie l’examen des données provenant de la zone exposée.
Le tracé des résidus studentisés ne révèle aucune observation ayant une valeur extrême. Voir la figure A1-7.
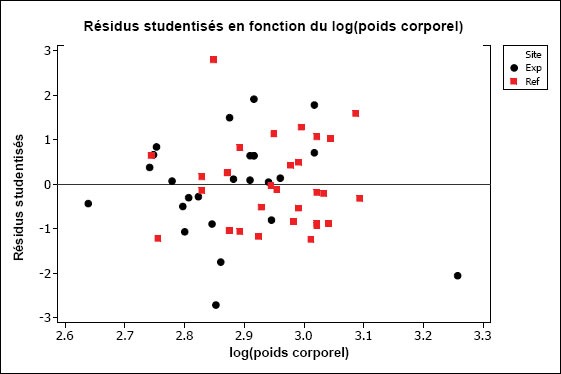
Figure A1-7 : Diagramme des résidus studentisés en fonction du log(poids corporel) de mâles de Catostomus commersoni - données ajustées au modèle d’interaction y = β0 + β1x1 + β2x2 + β3(x1 · x2) (description longue)
Normalité (testée en utilisant le test d’Anderson-Darling)
Homogénéité des variances (testée en utilisant le test de Levene)
Homogénéité des pentes de régression
β3 est significatif (p = 0,014); il y a donc une indication que les pentes ne sont pas parallèles.
Évaluation de l’influence en traçant la distance de Cook en fonction de la covariable.
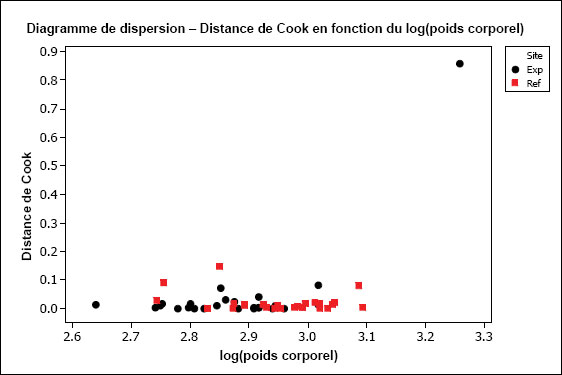
Figure A1-8 : Diagramme de la distance de Cook en fonction du log(poids corporel) de mâles de Catostomus commersoni – données ajustées au modèle d’interaction y = β0 + β1x1 + β2x2 + β3(x1 · x2) (description longue)
Une des observations parmi les données provenant du site d’exposition a une grande distance de Cook. Supprimer cette valeur et tester à nouveau l’hypothèse.
Normalité (testée en utilisant le test d’Anderson-Darling)
Homogénéité des variances (testée en utilisant le test de Levene)
Homogénéité des pentes de régression
β3 n’est pas significatif (p = 0,205), par conséquent il n’y a pas d’indication que les pentes sont non parallèles.
Poursuivre la procédure.
- Méthode 2
- « Condition » – mâles de Catostomus catostomus
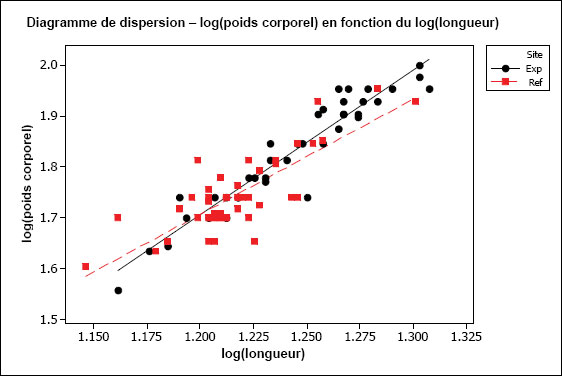
Figure A1-9 : Diagramme du log(poids corporel) en fonction du log(longueur) de mâles de Catostomus catostomus. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
β3 est significatif (p = 0,036), les pentes ne sont donc pas parallèles, mais R2 > 0,8. Ainsi, les données correspondent à un modèle à pentes parallèles, et la comparaison entre les coefficients de détermination peut être effectuée.
R2 pour le modèle à pentes parallèles est aussi > 0,8 et est moins de 0,02 (c.-à-d. 2 points de pourcentage) inférieur au R2 du modèle d’interaction. On utilise donc le modèle à pentes parallèles pour décrire les données et continuer l’analyse.
- Méthode 3
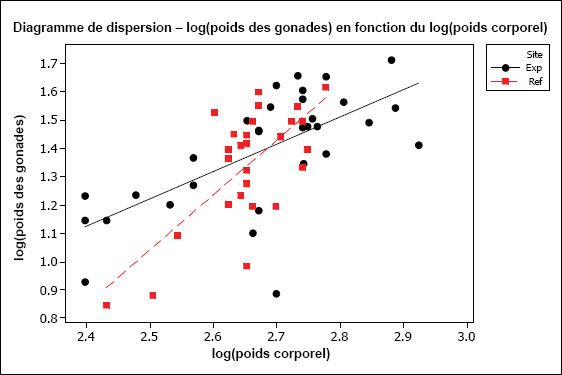
Figure A1-10a : Diagramme du log(poids des gonades) en fonction du log(poids corporel) de mâles de Catostomus catostomus. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
Homogénéité des pentes de régression
β3 est significatif (p = 0,036), un tracé de la distance de Cook en fonction de la covariable ne révèle aucun point influant et R2 < 0,8, donc l’application de la méthode 2 ne peut pas être tentée.
- Déterminer les valeurs minimales et maximales de la plage de valeurs de la covariable pour chaque site.
- Calculer les valeurs prévues de la variable dépendante pour chaque site (droite de régression) pour ces deux valeurs de la covariable.
- Calculer le pourcentage de différence (calculé ainsi : exposition – référence, exprimé en pourcentage de la valeur du site de référence) pour les deux valeurs de la covariable.
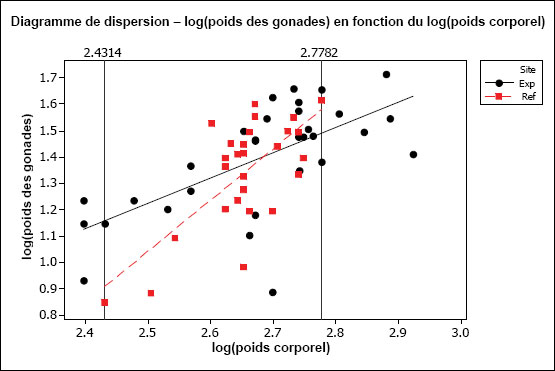
Figure A1-10b : Mêmes données que celles de la figure A1-10a, mais avec identification des valeurs minimales et maximales de la plage de chevauchement des valeurs de la covariable. (description longue)
Valeurs de la covariable : 2,4314 et 2,7782
Pour 2,4314 : les valeurs prévues de la variable dépendante sont 1,0949 (réf.) et 1,1544 (exp.).
Pour 2,7782 : les valeurs prévues de la variable dépendante sont 1,4963 (réf.) et 1,4883 (exp.).
Le calcul de la différence en pourcentage donne donc (après avoir trouvé l’antilogarithme des valeurs prévues de la variable dépendante) 14,69 % et –1,84 % respectivement pour les valeurs de la covariable 2,4314 et 2,7782. Ces valeurs sont les estimations de l’effet pour les plus petits et les plus grands poissons, respectivement, et elles peuvent être comparées à un seuil critique d’effet.
A1.6 Analyse de covariance non paramétrique
« Poids relatif des gonades » – femelles de Catostomus commersoni
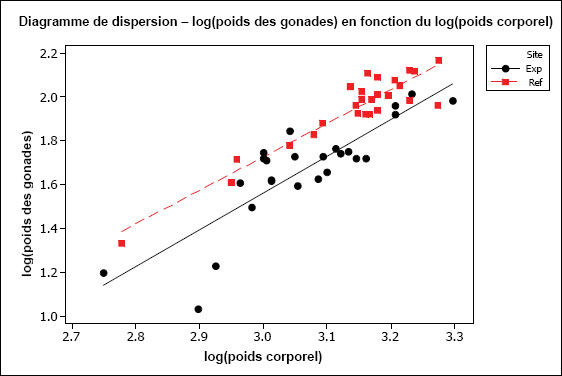
Figure A1-11 : Diagramme du log(poids des gonades) en fonction du log(poids corporel) de femelles de Catostomus commersoni. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
Les distributions des valeurs de la covariable pour les deux sites ne sont pas très semblables.
Taille des échantillons = 26 (réf.) et 25 (exp.)
Homogénéité des variances (testée en utilisant le test de Levene)
- Seule la condition d’homogénéité des variances n’est pas satisfaite – les tailles des échantillons sont presques égales, il est donc possible d’utliser l’ANCOVA paramétrique ou d’appliquer l’ANCOVA non paramétrique aux rangs des données.
ANCOVA non paramétrique des rangs
Variable dépendante : Rangs des poids des gonades
Covariable : Rangs des poids corporels
β3 n’est pas significatif (p = 0,364), il n’y a donc pas d’indication que les pentes sont non parallèles.
Tester les différences de la variable dépendante
β2 est significatif (p < 0,0001), il y a donc une différence significative du poids des gonades entre les deux sites.
Il est parfois possible d’effectuer des comparaisons avec les seuils critiques d’effet en calculant une différence de pourcentage en utilisant la moyenne ajustée des rangs. Cette différence de pourcentage est simplement la différence entre les moyennes ajustées des rangs, soit la valeur du site d’exposition moins celle du site de référence, exprimée en pourcentage du rang de la moyenne ajustée de référence. Les moyennes ajustées des rangs peuvent être calculées avec l’équation no 2 (présentée avec les infomrations générales sur les statistiques au début de la présente annexe) en utilisant la moyenne du rang de la covariable pour x1 et la valeur de la variable indicatrice appropriée pour x2 si l’approche par régression est utilisée pour l’ANCOVA.
Moyenne ajustée du rang du poids des gonades – site de référence : 30,8660
Moyenne ajustée du rang du poids des gonades – site d’exposition: 20,9394
Écart-type combiné = 6,31325 (rangs)
Pourcentage de différence = –31,16 % (calculé comme pourcentage de la zone de référence en utilisant les moyennes ajustées des rangs)
Note : Une ANCOVA paramétrique donnerait un pourcentage de différence de –28,90 %.
A1.7 Problèmes liés à la plage de valeurs de la covariable
Plages des valeurs de la covariable non semblables d’un site à l’autre
- Un sous-ensemble de données pour lequel il y a une plage de chevauchement des valeurs de covariable suffisamment large pour chaque site doit être cherché. Prenons comme exemple l’ensemble de données du poids relatif des gonades de mâles de Pleuronectes americanus dans la figure A1-12a. Les plages de la covariable pour les sites de référence et exposés sont assez différentes, car plusieurs poissons du site de référence sont plus petits. En prenant un sous-ensemble des données (en excluant les poissons pour lesquels le log(longueur) < 1,375), il est possible d’obtenir un ensemble de données où les plages de valeurs de la covariable sont assez semblables, avec un bon chevauchement. L’analyse peut être appliquée à ce sous-ensemble de données (illustré à la figure A1-12b). Une analyse avec toutes les données peut être effectuée à des fins de comparaison, mais l’interprétation d’une telle analyse devra être effectuée de manière circonspecte.
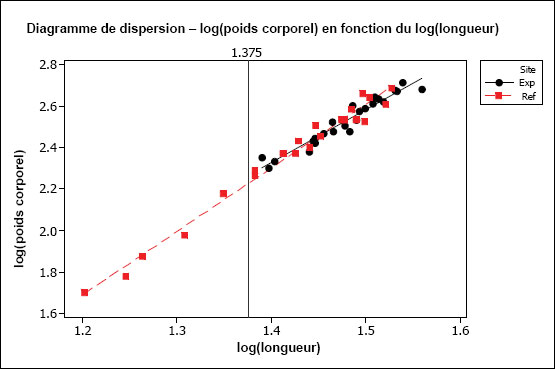
Figure A1-12a : Diagramme du log(poids corporel) en fonction du log(longueur) de mâles de Pleuronectes americanus. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
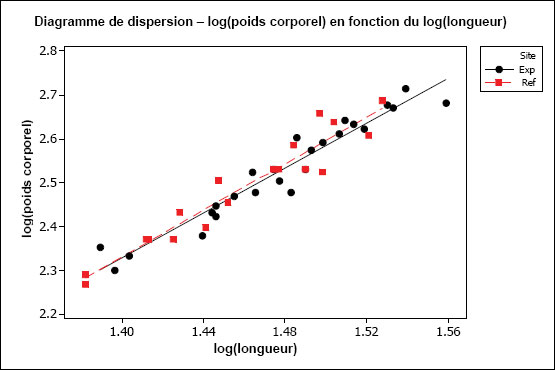
Figure A1-12b : Diagramme du log(poids corporel) en fonction du log(longueur) de mâles de Pleuronectes americanus (sous-ensemble des données de la figure A1-12a où seuls les poissons dont le log(longueur) > 1,375 sont conservés). (description longue)
Covariable observée seulement pour certaines valeurs
- La figure A1-13 est un exemple d’ensemble de données où la covariable n’est observée qu’à quelques valeurs. Ces ensembles de données sont représentatifs des analyses du poids selon l’âge de poissons de petite taille, mais ils peuvent aussi se produire avec d’autres ensembles de données. L’ANCOVA pourrait alors être non appropriée.
- Effectuer une ANOVA à un facteur du poids corporel (facteur : site) pour les poissons de un an.
- Effectuer une ANOVA à un facteur du poids corporel (facteur : site) pour les poissons de deux ans.
- Si la taille de l’échantillon pour un groupe d’âges est trop petite pour l’analyse, fournir la moyenne et la taille de l’échantillon.
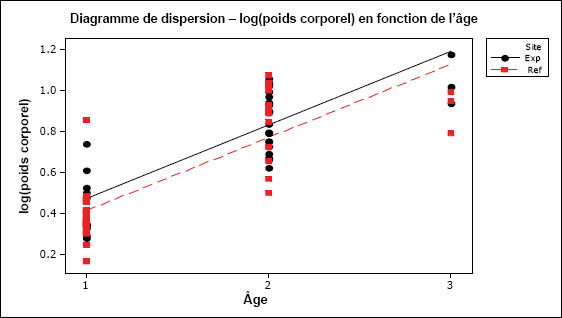
Figure A1-13 : Diagramme du log(poids corporel) en fonction de l’âge de femelles de Fundulus heteroclitus. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site. (description longue)
A1.8 Analyses de la puissance a priori
« Âge » – femelles de Perca flavescens
Nous souhaitons déterminer quel sera l’effort d’échantillonnage requis pour détecter une différence d’âge de 25 % chez des femelles de Perca flavescens. Les données suivantes proviennent de l’étude des poissons du cycle précédent pour la même fabrique. Voir la section 8.6.2.1 du présent chapitre pour plus de renseignements et des définitions de termes.
| Espèce | Sexe | Site | n | Moyenne | Ecart-type | Erreur type | Min. | Max. |
|---|---|---|---|---|---|---|---|---|
| Perca flavescens | F | Exp. | 30 | 4,100 | 1,094 | 0,200 | 3 | 8 |
| Perca flavescens | F | Réf. | 29 | 3,759 | 1,300 | 0,241 | 2 | 7 |
- Supposons une probabilité d’erreur de type I (α) de 0,05 et d’erreur de type II (β) de 0,2 (ces valeurs sont utilisées seulement à des fins d’exemple; pour la plupart des cas du Programme d’ESEE, les erreurs de type I et de type II doivent être établies de manière que α = β).
- Le coefficient de variation du site de référence peut être calculé comme suit :
- CV = 1,300/3,759 · 100 = 34,58 %.
- Notre seuil critique d’effet (SCE) est de 25 %.
- Nous commençons avec n = 20 et résolvons ce qui suit par itérations pour la valeur estimée de n (n̂)
- n̂ = 2(tα + tβ)2(CV/SCE)2
- En utilisant n = 20, α = 0,05, et β = 0,2, nous obtenons tα = 2,093 et tβ = 0,861.
[tαcalculé pour un test bilatéral à (n–1) degrés de liberté; tβ calculé pour un test unilatéral à (n–1) degrés de liberté] - n̂ = 2(2,093 + 0,861)2(34,58/25)2= 33,39 = 34
- En utilisant n = 34, α = 0,05, et β = 0,2 nous obtenons tα = 2,035 et tβ = 0,853
- n̂ = 2(2,035 + 0,853)2(34,58/25)2 = 31,9 = 32
- En utilisant n = 32, α = 0,05, et β = 0,2 nous obtenons tα = 2,040 et tβ = 0,853
- n̂ = 2(2,040 + 0,853)2(34,58/25)2 = 32,03 = 32
- n̂ = n = 32
Environ 32 femelles de Perca flavescens seront requises pour chaque zone (de référence et exposé) afin de détecter une différence d’âge de 25 %.
« Poids relatif des gonades » de femelles de Perca flavescens
Nous souhaitons déterminer quel sera l’effort d’échantillonnage requis pour détecter une différence de 25 % du poids des gonades de femelles Perca flavescens. Les résultats suivants proviennent de l’ANCOVA du cycle précédent pour la même fabrique. Voir la section 8.6.2.1 du présent chapitre pour plus de renseignements et des définitions de termes.
- Taille des échantillons : 29 (réf.), 30 (exp.)
- Écart-type combiné (des résidus) en utilisant des données soumises à une transformation logarithmique = 0,0743033 (c’est aussi égal à la racine carrée du terme erreur quadratique moyenne obtenu en ajustant les données au modèle ANCOVA à pentes parallèles).
- Supposons une probabilité d’erreur de type I (α) de 0,05 et d’erreur de type II (β)de 0,2 (ces valeurs sont utilisées seulement à des fins d’exemple; pour la plupart des cas du Programme d’ESEE, les erreurs de type I et de type II doivent être établies de manière que α = β).
- ETZ = 0,0743033
- SCEZ = log(0,25+1) = log(1,25) = 0,09691
- Nous commençons avec n = 20 et résolvons ce qui suit par itérations pour la valeur estimée de n (n̂)
- n̂= 2(tα + tβ)2(SDz/SCEz)2
- En utilisant n = 20, α = 0,05, et β = 0,2, nous obtenons tα = 2,093 et tβ = 0,861
[tα calculé pour un test bilatéral à (n–1) degrés de liberté; tβ calculé pour un test unilatéral à (n–1) degrés de liberté] - n̂ = 2(2,093 + 0,861)2(0,0743033/0,09691)2 = 10,26 = 11
- En utilisant n = 11, α = 0,05, et β = 0,2, nous obtenons tα = 2,228 et tβ = 0,879
- n̂ = 2(2,228 + 0,879)2(0,0743033/0,09691)2 = 11,34 = 12
- En utilisant n = 12, α = 0,05, et β = 0,2, nous obtenons tα = 2,201 et tβ = 0,876
- n̂ = 2(2,201 + 0,876)2(0,0743033/0,09691)2 = 11,13 = 12
- n̂ = n = 12
Environ 12 femelles de Perca flavescens seront requises pour chaque site (de référence et exposé) afin de détecter une différence de 25 % du poids relatif des gonades.
A1.9 Analyses de la puissance post hoc
« Condition » – femelles de Catostomus commersoni
Dans cet exemple, un résultat non significatif est obtenu pour le critère d’effet de la condition de femelles de Catostomus commersoni. Un exemple d’analyse de puissance est effectué pour déterminer la puissance du test réalisé afin de détecter le seuil critique d’effet. Nous obtenons les résultats d’ANCOVA suivants en utilisant le log(poids corporel) comme variable dépendante et le log(longueur) comme covariable. Voir la section 8.6.2.2 du présent chapitre pour plus d’explications et des définitions de termes.
| Source | Somme des carrés | d.l. | Carré moyen | Rapport F | p |
|---|---|---|---|---|---|
| log(longueur) | 0,121190 | 1 | 0,119427 | 119,32 | <0,001 |
| Site | 0,000046 | 1 | 0,000046 | 0,05 | 0,831 |
| Erreur | 0,027025 | 27 | 0,001001 | ||
| Total | 0,148261 | 29 |
- Le SCE pour la condition est 10 % de la moyenne de référence (converti à SCEZ par la formule suivante) et la probabilité d’erreur de type I (α) utilisée initialement pour l’ANCOVA de l’exemple ci-dessus était 0,05 (0,831 est plus grand que 0,05, et la comparaison entre le site d’exposition et le site de référence est donc non significative).
La formule du calcul de la puissance est :![]()

- SCEZ = log(f +1) , où f = SCE est représenté comme fraction de la moyenne de référence.
Donc SCEZ = log(0,1+1) = log(1,1) = 0,0413926 - n = 15 pour chaque site et, par conséquent, tα = 2,145

- tβ = 1,538 correspond à β = 0,1486
- Puissance = 1 - β = 0,8514
La puissance du test est modérée (puissance = 0,8514) pour détecter une différence de 10 %, bien que l’erreur de type II (β = 0,1486) n’ait pas été suffisamment faible pour être égale à l’erreur de type I (α = 0,05). La recommendation du Programme d’ESEE est d’établir a comme égal à β (le risque pour l’industrie est égal au risque pour l’environnement). Par conséquent, une valeur supérieure de α aurait dû être utilisée pour cette ANCOVA avant de déclarer que la comparaison n’est pas significative, pour que α = β. Dans ce cas particulier, la valeur de p de l’ANCOVA (0,831) était assez élevée, ce qui fait que la comparaison entre le site d’exposition et le site de référence serait encore déclarée non significative, même si on fixait α à une valeur aussi élevée que β = 0,1486 (p = 0,831 > 0,1486). La répétition des analyses de puissance pour des valeurs plus élevés de a entraînerait une baisse des valeurs de β. D’autres analyses post hoc ne seraient donc pas nécessaires dans ce cas pour déclarer une absence de signification. Les futurs efforts de suivi à cet endroit devraient utiliser une combinaison de plus grandes tailles d’échantillons et/ou de valeurs de α plus élevées pour avoir une puissance suffisante pour détecter le SCE d’intérêt. Ainsi, la proposition d’étude en vue du prochain suivi devrait inclure des analysesde puissance a priori appropriées.
Annexe 2 : Représentation graphique et tabulaire des données
Liste des figures :
- Figure A2-1 : Diagramme du processus de décision illustrant les traitements des données des critères d’effet pour le poisson et le benthos et renvois aux exemples de tableaux et de graphiques présentés dans cette annexe
- Figure A2-2 : Diagramme en rectangles et moustaches des statistiques descriptives de l’âge selon l’espèce de poisson et le sexe
- Figure A2-3 :Résultats de l’analyse de variance (ANOVA) de l’âge moyen des poissons prélevés dans les zones de référence et d’exposition (moyenne et erreur type)
- Figure A2-4 : Régression linéaire du poids du foie du poisson en fonction du poids corporel, comme exemple de résumé des effets sur le poids du foie ou la taille des gonades (males de Catostomus sp.)
- Figure A2-5 : Statistiques descriptives de la densité totale des invertébrés benthiques provenant d’un plan d’échantillonnage contrôle-impact
- Figure A2-6 : Résutats de l’analyse de variance (ANOVA) de la densité totale des invertébrés benthiques provenant d’un plan d’échantillonnage contrôle-impact
- Figure A2-7 : Diagramme de la densité totale des invertébrés benthiques en fonction de la distance du diffuseur provenant d’un plan d’échantillonnage par gradient linéaire
Liste des tableaux :
- Tableau A2-1 :Statistiques descriptives de l’âge selon l’espèce de poisson et le sexe
- Tableau A2-2 : Résultats de l’analyse de variance (ANOVA) de l’âge selon l’espèce de poisson et le sexe
- Tableau A2-3 : Résultats de l’analyse de covariance (ANCOVA) du poids du foie par rapport au poids corporel selon l’espèce et le sexe
- Tableau A2-4 : Tableau récapitulatif des résultats pour les poissons
- Tableau A2-5 : Statistiques descriptives de la densité totale des invertébrés benthiques
- Tableau A2-6 : Résultats de l’analyse de variance (ANOVA) de la densité totale des invertébrés benthiques
- Tableau A2-7 : Tableau récapitulatif des statistiques descriptives des invertébrés benthiques
- Tableau A2-8 : Tableau récapitulatif des résultats pour les invertébrés benthiques
- Tableau A2-9 : Résumé récapitulatif des effets sur le site
Annexe 2 : Représentation graphique et tabulaire des données
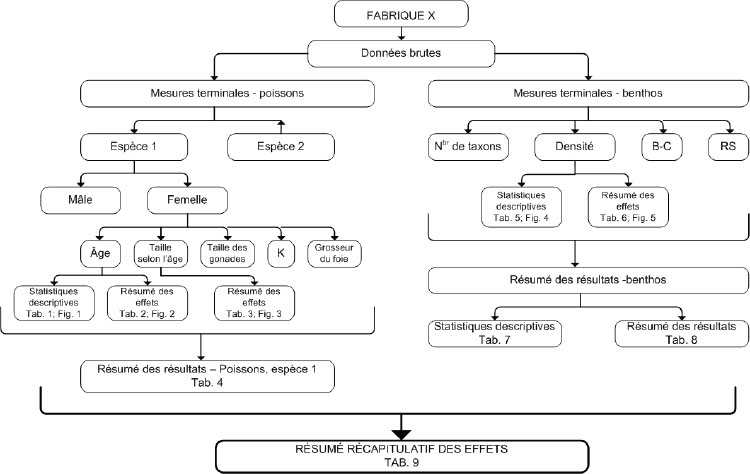
Figure A2-1 : Diagramme du processus de décision illustrant les divers traitements des données des critères d’effet pour le poisson et le benthos et renvois aux exemples de tableaux et de graphiques présentés dans cette annexe. K : coefficient de condition; B-C : indice de Bray-Curtis; RS : indice de régularité de Simpson. (description longue)
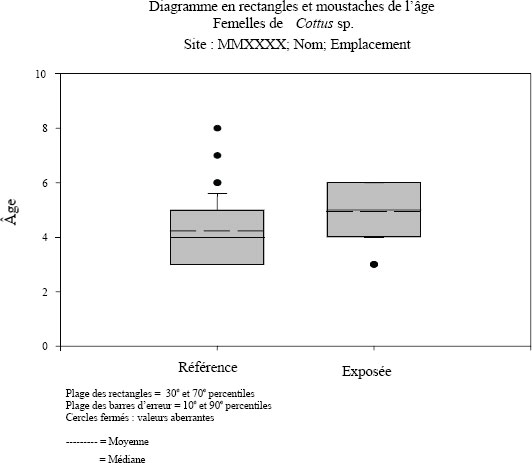
Figure A2-2 : Diagramme en rectangles et moustaches des statistiques descriptives de l’âge selon l’espèce de poisson et le sexe (description longue)
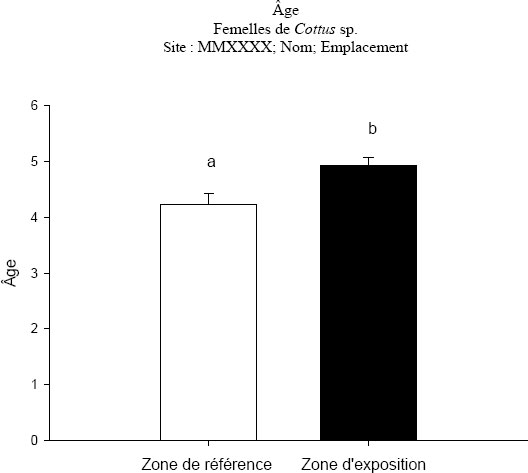
Figure A2-3 : Résultats de l’analyse de variance (ANOVA) de l’âge moyen des poissons prélevés dans les zones de référence et exposée (moyenne et erreur type) (description longue)
Note : La différence entre les bâtons identifiés par des lettres différentes est significative. La barre verticale indique la moyenne, et les barres horizontales, l’erreur type.
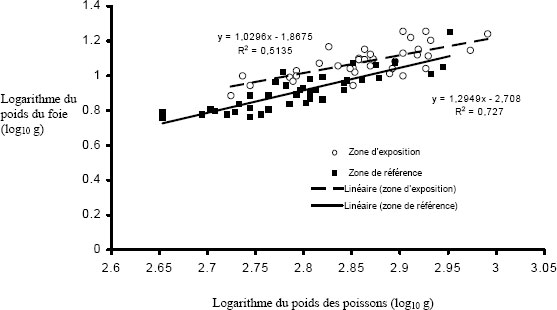
Figure A2-4 : Régression linéaire du poids du foie du poisson en fonction du poids corporel, comme exemple de résumé des effets sur le poids du foie ou la taille des gonades (males de Catostomus sp.) (description longue)
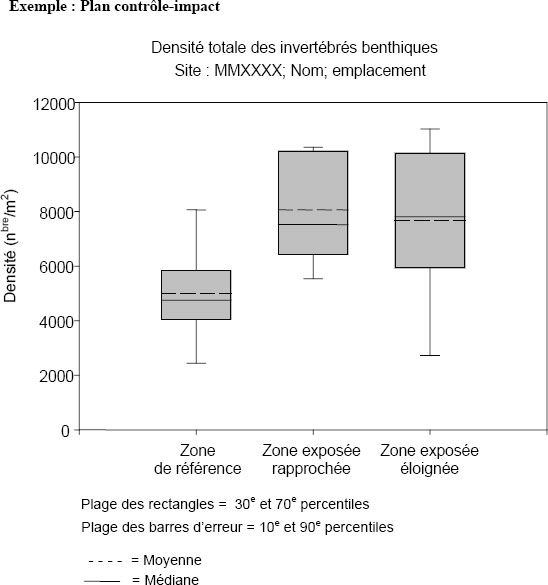
Figure A2-5 : Statistiques descriptives de la densité totale des invertébrés benthiques provenant d’un plan d’échantillonnage contrôle-impact (description longue)
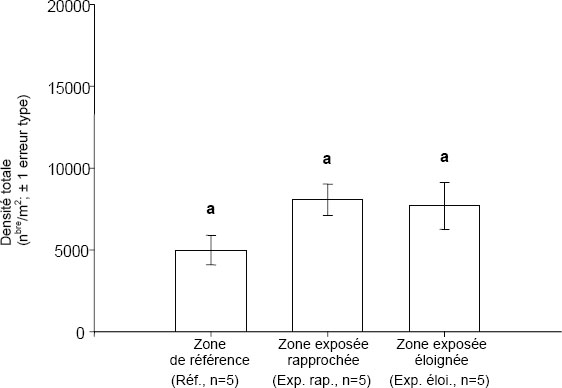
Figure A2-6 : Résultats de l’analyse de variance (ANOVA) de la densité totale des invertébrés benthiques provenant d’un plan d’échantillonnage contrôle-impact (description longue)
Note : Les bâtons identifiés par les mêmes lettres ne sont pas significativement différents. Les valeurs indiquées sont les moyennes et les erreurs types correspondantes.
Exemple : Plan par gradient linéaire
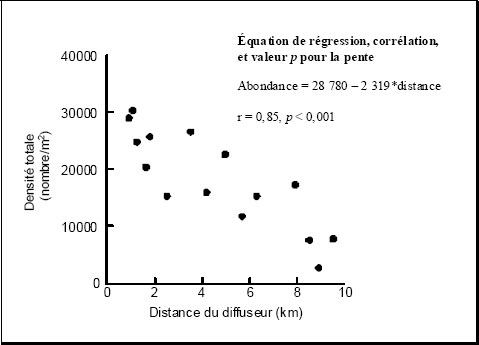
Figure A2-7 : Diagramme de la densité totale des invertébrés benthiques en fonction de la distance du diffuseur provenant d’un plan d’échantillonnage par gradient linéaire (description longue)
| Zone | Moy. | ET | Erreur type | n | Max. | Min. |
|---|---|---|---|---|---|---|
| Référence | 4,23 | 1,16 | 0,19 | 39 | 8,00 | 3,00 |
| Exposée | 4,93 | 0,93 | 0,14 | 46 | 6,00 | 3,00 |
| Sources de variation | Somme des carrés | Degrés de liberté | Carré moyen | F | p | Significatif à p < 0,05 |
|---|---|---|---|---|---|---|
| Intergroupe | 0,072624 | 1 | 0,072624 | 11,25004 | 0,001202 | oui |
| Intragroupe | 0,535802 | 83 | 0,006455 | |||
| Totale | 0,608426 | 84 |
| Zone | n | Logarithmes | (R2) | Pentes différentes? | Logarithmes | Pentes différentes? | Antilog MMC | Am- pleur de la diffé- rence |
||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pente | ET | p | Signi- fica- tif à p < 0,05 |
Moyenne des moindres carrés (MMC) | ET | p | Signi- fica- tif à p < 0,05 |
|||||
| Réf. | 39 | 1,3 | 0,0547 | 0,727 | - | - | 0,95 | 0,0624 | - | - | 8,93 | - |
| Exp. | 38 | 1,03 | 0,0632 | 0,5135 | 0,212 | Non | 1,04 | 0,0616 | 0,001 | Oui | 10,96 | 23 % |
| Niveau trophique | Espèces | Sexe | Type de réponse | Critère d’effet | Effet? | Direction | Ampleur |
|---|---|---|---|---|---|---|---|
| Poisson | Catostomus catostomus (Meunier rouge) |
F | Survie | Âge | s.o. | ||
| Utilisation d’énergie | Poids selon l’âge | s.o. | |||||
| Poids relatif des gonades | Non | ||||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 7 %2 | |||
| Poids relatif du foie | Oui | réf. < exp. | 21 %2 | ||||
| M | Survie | Âge | s.o. | ||||
| Utilisation d’énergie | Poids selon l’âge | s.o. | |||||
| Poids relatif des gonades | Oui | ||||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 6 %2 | |||
| Poids relatif du foie | Oui | réf. < exp. | 23 %2 | ||||
| Cottus ricei (Chabot à tête plate) |
F | Survie | Âge | Oui | réf. < exp. | 8 %2 | |
| Utilisation d’énergie | Poids selon l’âge | Oui | réf. < exp. | 52 %1 | |||
| Poids relatif des gonades | Oui | réf. < exp. | 57 %2 | ||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 31 %1 | |||
| Poids relatif du foie | Oui | réf. < exp. | 62 %2 | ||||
| M | Survie | Âge | Oui | réf. < exp. | 8 %2 | ||
| Utilisation d’énergie | Poids selon l’âge | Oui | réf. < exp. | 106 %1 | |||
| Poids relatif des gonades | Oui | réf. < exp. | 11 %2 | ||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 18 %2 | |||
| Poids relatif du foie | Oui | réf. < exp. | 52 %2 |
1 L’ANCOVA a été effectuée et les pentes sont significativement différentes. Consulter l’annexe 7.1 pour des directives sur le calcul de l’ampleur de l’effet.
2 L’ampleur est calculée en comparant les moyennes ajustées pour les zones de référence et exposée (si les données sont transformées en logarithmes; l’ampleur est calculée avec les antilogarithmes des moyennes ajustées). Dans le cas présent, les pentes ne sont pas significativement différentes de sorte que les moyennes ajustées peuvent être comparées. L’équation est la suivante :[(moyenne ajustée de la zone exposée – moyenne ajustée de la zone de référence)/moyenne ajustée de la zone de référence] × 100.
| Zone | Moyenne | ET | Erreur type | n | Max. | Min. |
|---|---|---|---|---|---|---|
| Référence | 4 986,85 | 2 011,21 | 899,44 | 5 | 8 062,02 | 2 442,73 |
| Exposée rapprochée* | 8 062,73 | 2 135,30 | 954,94 | 5 | 10360,31 | 5 535,88 |
| Exposée éloignée* | 7 685,04 | 3 205,63 | 1 433,60 | 5 | 11 027,65 | 2 717,00 |
* Exposée rapprochée = fortement exposée à l’effluent; Exposée éloignée = peu exposée à l’effluent
| Sources de variation | Somme des carrés | degrés de liberté | Carré moyen | F | p | Significatif à p < 0,05 |
|---|---|---|---|---|---|---|
| Intragroupe | 2,81 E + 07 | 2 | 1,41 E + 07 | 2,236 | 0,15 | Non |
| Intergroupe | 7,55 E + 07 | 12 | 6,29 E + 06 | |||
| Totale | 1,04 E + 08 | 14 |
| Critère d’effet | Zone | Moy. | ET | Erreur type | n | Max. | Min. |
|---|---|---|---|---|---|---|---|
| Nombre de taxons | Référence | 19,60 | 1,52 | 0,68 | 5 | 21 | 18 |
| Exposée rapprochée* | 21,20 | 1,48 | 0,66 | 5 | 23 | 19 | |
| Exposée éloignée* | 20,00 | 1,87 | 0,84 | 5 | 23 | 18 | |
| Densité | Référence | 4 986,85 | 2 011,21 | 899,44 | 5 | 8 062,02 | 2 442,73 |
| Exposée rapprochée | 8 062,73 | 2 135,30 | 954,94 | 5 | 10 360,31 | 5 535,88 | |
| Exposée éloignée | 7 685,04 | 3 205,63 | 1 433,60 | 5 | 11 027,65 | 2 717,00 | |
| Indice de régularité de Simpson | Référence | 0,77 | 0,03 | 0,014 | 5 | 0,82 | 0,75 |
| Exposée rapprochée | 0,81 | 0,03 | 0,015 | 5 | 0,86 | 0,78 | |
| Exposée éloignée | 0,67 | 0,04 | 0,017 | 5 | 0,71 | 0,63 | |
| Indice de Bray-Curtis | Référence | 0,24 | 0,11 | 0,05 | 5 | 0,42 | 0,14 |
| Exposée rapprochée | 0,37 | 0,10 | 0,05 | 5 | 0,48 | 0,24 | |
| Exposée éloignée | 0,44 | 0,09 | 0,04 | 5 | 0,55 | 0,34 |
* Exposée rapprochée = fortement exposée à l’effluent; Exposée éloignée = peu exposée à l’effluent
| Niveau trophique | Critère d’effet | Effet? | Direction | Ampleur1 | |
|---|---|---|---|---|---|
| % | ET | ||||
| Benthos | Densité | Non | |||
| Nombre de taxons | Non | ||||
| Indice de régularité de Simpson | Oui Oui |
référence > exposée éloignée exposée rapprochée > exposée éloigné |
13 %1 17 %1 |
3,33 ET 4,67 ET |
|
| Indice de Bray-Curtis | Oui | référence < exposée éloignée | 83 %1 | 1,82 ET | |
1 Pour un plan contrôle-impact, l’ampleur est calculée en % [(moyenne de la zone exposée – moyenne de la zone de référence)/moyenne de la zone de référence] × 100 et standardisée par rapport à l’écart-type de la zone de référence (moyenne de la zone exposée – moyenne de la zone de référence)/écart-type de la zone de référence).
| Niveau trophique | Espèces | Sexe | Type de réponse | Critère d’effet | Effet? | Observation | Ampleur3 | |
|---|---|---|---|---|---|---|---|---|
| % | ET | |||||||
| Poisson | Catostomus catostomus (Meunier rouge) |
F | Survie | Âge | s.o. | |||
| Utilisation d’énergie | Poids selon l’âge | s.o. | ||||||
| Poids relatif des gonades | Non | |||||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 7 %2 | ||||
| Poids relatif du foie | Oui | réf. < exp. | 21 %2 | |||||
| M | Survie | Âge | s.o. | |||||
| Utilisation d’énergie | Poids selon l’âge | s.o. | ||||||
| Poids relatif des gonades | Non | |||||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 6 %2 | ||||
| Poids relatif du foie | Oui | réf. < exp. | 23 %2 | |||||
| Cottus ricei (Chabot à tête plate) |
F | Survie | Âge | Oui | réf. < exp. | 8 %2 | ||
| Utilisation d’énergie | Poids selon l’âge | Oui | réf. < exp. | 52 %1 | ||||
| Poids relatif des gonades | Oui | réf. < exp. | 57 %2 | |||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 31 %1 | ||||
| Poids relatif du foie | Oui | réf. < exp. | 62 %2 | |||||
| M | Survie | Âge | Oui | réf. < exp. | 8 %2 | |||
| Utilisation d’énergie | Poids selon l’âge | Oui | réf. < exp. | 106 %1 | ||||
| Poids relatif des gonades | Oui | réf. < exp. | 11 %2 | |||||
| Stockage d’énergie | Condition | Oui | réf. < exp. | 18 %2 | ||||
| Poids relatif du foie | Oui | réf. < exp. | 52 %2 | |||||
| Benthos | Densité | Non | ||||||
| Nombre de taxons | Non | |||||||
| Indice de régularité de Simpson | Oui | réf. > exp. éloi. | 13 % | 3,33 | ||||
| Oui | exp. rap. > exp. éloi. | 17 % | 4,67 | |||||
| Indice de Bray-Curtis | Oui | réf. < exp. éloi. | 83 % | 1,82 | ||||
1 L’ANCOVA a été effectuée et les pentes sont significativement différentes. Consulter l’annexe 7.1 pour les directives sur le calcul de l’ampleur de l’effet.
2 L’ampleur a été calculée en comparant les moyennes ajustées pour la zone de référence et la zone exposée (si les données sont transformées en logarithmes, l’ampleur est calculée avec l’antilogarithme des moyennes ajustées). Dans le cas présent, les pentes ne sont pas significativement différentes de sorte que les moyennes ajustées peuvent être comparées. L’équation est la suivante : [(moyenne ajustée de la zone exposée – moyenne ajustée de la zone de référence)/moyenne ajustée de la zone de référence] × 100.
3 Pour les études des communautés d’invertébrés benthiques suivant un plan contrôle-impact, l’ampleur est calculée en % [(moyenne de la zone exposée – moyenne de la zone de référence)/moyenne de la zone de référence] × 100 et standardisée par rapport à l’écart-type de la zone de référence (moyenne de la zone exposée – moyenne de la zone de référence)/écart-type de la zone de référence).
Annexe 3 : Étude de cas – ANCOVA et analyse de puissance pour l’étude des poissons
Ce cas est founi pour montrer un exemple d’application des méthodes recommandées dans le présent document. Les données ont été recueillies au cours d’une étude précédente sur les poissons adultes à une fabrique de pâtes et papiers canadienne. Dans cet exemple, la fabrique produit de la pâte kraft et rejette un effluent dans un milieu récepteur lacustre. La zone de référence était une baie adjacente du lac dont l’habitat naturel possède des caractéristiques semblables à celles de l’habitat de la zone exposée rapprochée (fortement exposée à l’effluent), et elle ne reçoit pas de déversements allochtones. L’espèce sentinelle choisie pour l’étude est le Meunier noir (Catostomus commersoni). Les tailles des échantillons étaient proches de celles recommandées pour l’étude des poissons, à l’exception du nombre de mâles dans la zone exposée rapprochée :
| Zone exposée rapprochée (fortement exposée à l’effluent) |
Zone de référence |
|
| Mâles | 12 | 22 |
| Femelles | 26 | 24 |
L’ensemble de données comprend des renseignements sur la longueur, le poids total, le poids du foie, le sexe, le poids des gonades et l’âge des meuniers adultes mâles et femelles. Il n’y avait pas d’estimations de la fécondité.
Après l’étape initiale visant à assurer que l’ensemble des données était exempt d’erreurs de transcription, la moyenne et l’écart-type de chaque variable ont été calculés par sexe et par zone d’échantillonnage (tableau A3-1). Les opérations mathématiques ont été exécutées séparément pour les mâles et les femelles. Des courbes de distribution normale des erreurs ont été produites pour chaque variable (par sexe et par zone) pour repérer les valeurs aberrantes et évaluer la normalité des données. L’examen de ces diagrammes n’a révélé aucune valeur aberrante évidente, à l’exception d’un mâle de la zone exposée rapprochée. Les diagrammes des résidus d’ANOVA/ANCOVA peuvent aussi être utilisés pour examiner les données.
| Sexe | Zone | Longueur à la fourche (cm) |
Poids corporel (g) |
Poids des gonades (g) |
Poids du foie (g) |
Âge (ans) |
|---|---|---|---|---|---|---|
| Femelle | Référence | 44,4 ± 2,4 (24) |
1135,1 ± 150,4 (24) |
46,0 ± 7,5 (24) |
15,8 ± 2,1 (24) |
10,8 ± 3,4 (24) |
| Exposée rapprochée* | 41,5 ± 3,0 (26) |
1081,7 ± 228,4 (26) |
36,9 ± 15,9 (26) |
17,8 ± 7,5 (16) |
11,1 ± 3,0 (26) |
|
| Mâle | Référence | 41,4 ± 1,8 (22) |
975,9 ± 90,1 (22) |
66,4 ± 11,1 (21) |
10,8 ± 1,6 (22) |
10,5 ± 3,0 (22) |
| Exposée rapprochée* | 39,3 ± 1,8 (12) |
950,9 ± 166,6 (11) |
48,0 ± 15,5 (12) |
18,4 ± 8,4 (12) |
12,3 ± 3,0 (12) |
* Exposée rapprochée = fortement exposée à l’effluent
Tel que mentionné précédemment, la plupart des résultats ont été obtenus en utilisant une ANCOVA. À titre d’exemple, une description détaillée est présentée pour le paramètre de la taille (longueur) selon l’âge de Meuniers noirs femelles (une critères d’appui de l’étude des poissons). Pour ces calculs, les données de la longueur et de l’âge ont été transformées en log10.
La première étape est de procéder au test préliminaire d’égalité des pentes. L’énoncé du modèle pour l’analyse de la taille selon l’âge est représenté par l’équation suivante :
log(longueur) = constante + zone + log(âge) + zone*log(âge)
où le terme d’interaction zone*log(âge) représente le test de l’égalité des pentes des droites de régression des zones, et log(âge), la covariable. D’après le tableau d’ANCOVA, il est évident que le terme d’interaction zone*log(âge) n’est pas significatif (p = 0,376) (tableau A3-2a). Cela indique que les pentes des droites de régression pour chaque zone peuvent être traitées comme étant approximativement parallèles. Ce résultat indique aussi que le terme d’interaction peut être éliminé du modèle et que nous pouvons continuer avec le modèle d’ANCOVA suivant :
log(longueur) = constante + zone + log(âge)
où « zone » représente le test des différences des moyennes ajustées. L’erreur quadratique moyenne (EQM) tirée de la table d’ANCOVA résultante fournira l’estimation de la variabilité (EQM = 0,00033) de la longueur selon l’âge (tableau A3-2b). Pendant que les analyses susmentionnées sont menées, les résidus du modèle préliminaire et du modèle d’ANCOVA peuvent être conservés pour l’évaluation des conditions de normalité et d’homogénéité de la variance.
| Source | Somme des carrés |
d.l. | Carré moyen | Rapport F | p |
|---|---|---|---|---|---|
| Zone | 0,00086 | 1 | 0,00086 | 2,62639 | 0,11193 |
| Log(âge) | 0,02126 | 1 | 0,02126 | 64,58474 | < 0,0001 |
| Zone*log(âge) | 0,00026 | 1 | 0,00026 | 0,79780 | 0,37640 |
| Erreur | 0,01514 | 46 | 0,00033 |
| Source | Somme des carrés |
d.l. | Carré moyen | Rapport F | p |
|---|---|---|---|---|---|
| Zone | 0,01240 | 1 | 0,01240 | 37,57576 | < 0,0001 |
| Log(âge) | 0,02167 | 1 | 0,02167 | 65,66667 | < 0,0001 |
| Erreur | 0,01541 | 47 | 0,00033 |
Calcul de la taille de l’échantillon
Pour calculer la taille de l’échantillon, l’équation de la puissance avec les valeurs de Z peut être utilisée. À titre de rappel, l’équation est :
n = 2 (Zα + Zβ)2 (ET/SCE)2 + 0,25(Zα)2
La racine carrée de l’EQM du modèle d’ANCOVA remplace l’écart-type (ET) dans l’équation de la puissance. Le seuil critique d’effet (SCE) correspond à l’effet ou à la différence de paramètre qu’on souhaite déceler. Aux fins du présent exemple et pour les autres paramètres de l’étude de cas, la taille de l’échantillon a été calculée pour des SCE de 5, 10, 20, 50 et 100 % (c.-à-d. les différences entre les zones).
Bon nombre des paramètres calculés pour l’étude des poissons suivent généralement une distribution log-normale et exigent des transformations logarithmiques. Pour calculer la taille de l’échantillon, l’ET et le SCE doivent être exprimés en logarithmes. Il est à noter qu’aux fins de l’étude des poissons de l’ESEE, il ne faut pas ajouter 1 aux valeurs avant de les transformer en logarithmes, car cela a des effets indésirables sur les variances calculées lorsqu’on change les unités de mesure. L’expression d’une différence en logarithme équivaut à multiplier ou à diviser cette différence par un certain facteur. Par exemple, si la différence dans le log de la longueur entre deux zones est de 0,301, les poissons d’une zone ont alors une longueur deux fois supérieure (antilog de 0,301 = 2) aux poissons de l’autre zone. Dans le tableau suivant, le SCE a été exprimé en logarithme avec l’antilog correspondant; ces valeurs de SCE correspondent en gros à celles utilisées pour des données non transformées :
| Seuil critique d’effet (logarithme) | 0,0212 | 0,0414 | 0,0792 | 0,176 | 0,301 |
| Seuil critique d’effet(antilog) | 1,05 | 1,10 | 1,20 | 1,50 | 2,00 |
| % d’augmentation* | 5 | 10 | 20 | 50 | 100 |
| % de diminution† | 5 | 9 | 17 | 33 | 50 |
* Dans la zone exposée comparativement à la zone de référence.
† Dans la zone exposée comparativement à la zone de référence.
Par conséquent, dans le cas de la longueur selon l’âge (log10 des données) :
- ET = (EQM)0,5 = (0,00033)0,5 = 0,01817
- Zα (test bilatéral) = 1,96
- Zβ (test unilatéral) = 1,282
- SCE = 5 % (voir tableau ci-dessus)
n = 2 (1,96+1,28)2 (0,01817/0,0212)2 + 0,25(1,96)2
n = 16,4 (ou, arrondi, n=17)
De même, pour les autres SCE, les tailles de l’échantillon estimées (c.-à-d. le nombre de poissons à prélever par zone) seraient :
| SCE | 5 % | 10 % | 20 % | 50 % |
| n | 17 | 5 | 3 | 2 |
L’estimation de la variabilité et les calculs de la taille de l’échantillon pour le poids des gonades, le poids du foie et la condition des mâles et des femelles de meuniers sont effectués de la même façon que celle décrite pour la longueur selon l’âge (tableau A3-3). Dans tous les cas, sauf un, les pentes des droites de régression de la zone de référence et de la zone exposée rapprochée étaient égales, et l’EQM du modèle d’ANCOVA a été employée pour estimer la variabilité. En ce qui concerne les Meuniers noirs mâles, les pentes des régressions du log(poids) en fonction du log(longueur) (c.-à-d. la condition) n’étaient pas égales d’une zone à l’autre (p = 0,0068). Pour déterminer si la seule valeur aberrante (mâle, zone exposée rapprochée) a pu influer sur l’ANCOVA, les calculs ont été refaits en omettant cette donnée. Cette fois, les régressions étaient homogènes entre les zones. Ces résultats découlent partiellement du fait que la taille de l’échantillon était petite (c.-à-d. un effet accru de la valeur aberrante sur la régression) et cela devrait être signalé dans le rapport sur les données.
Dans le cas de l’âge moyen, l’EQM de l’ANOVA unilatérale a été utilisée pour estimer la variabilité (tableau A3-3).
Les résultats finaux des calculs de la taille des échantillons (tableau A3-3) indiquent que le nombre maximal de poissons qu’il faut prélever dans chaque zone était d’environ 703 mâles et de 738 femelles pour déceler une différence entres les zones (SCE) de 5 %; de 185 mâles et de 194 femelles, pour déceler une différence de 10 %; de 52 mâles et de 54 femelles pour déceler une différence de 20 % et de 12 mâles et de 12 femelles pour déceler une différence de 50 %. Parmi tous les paramètres, l’âge moyen était le plus variable et nécessitait la plus grande taille d’échantillon pour déceler des différences.
| Critère | Sexe | Modèle | Log | Taille de l’échantillon estimée (nombre de poissons/zone) | |||
|---|---|---|---|---|---|---|---|
| EQM | SCE 5 %
|
SCE 10 %
|
SCE 20 %
|
SCE 50 %
|
|||
| Longueur selon l’âge | Mâle | ANCOVA | 0,00014 | 8 | 3 | 2 | 2 |
| Femelle | ANCOVA | 0,00033 | 17 | 5 | 3 | 2 | |
| Poids selon l’âge | Mâle | ANCOVA | 0,00211 | 100 | 27 | 9 | 3 |
| Femelle | ANCOVA | 0,00295 | 139 | 38 | 11 | 3 | |
| Condition | Mâle | ANCOVA1 | s.o. | - | - | - | - |
| Femelle | ANCOVA | 0,00100 | 48 | 14 | 5 | 2 | |
| Poids du foie | Mâle | ANCOVA | 0,00994 | 466 | 123 | 35 | 8 |
| Femelle | ANCOVA | 0,00626 | 294 | 78 | 22 | 6 | |
| Poids des gonades | Mâle | ANCOVA | 0,00881 | 413 | 110 | 31 | 7 |
| Femelle | ANCOVA | 0,01013 | 475 | 126 | 35 | 8 | |
| Âge moyen | Mâle | ANOVA | 0,01499 | 703 | 185 | 52 | 12 |
| Femelle | ANOVA | 0,01574 | 738 | 194 | 54 | 12 | |
1 L’analyse préliminaire (test des pentes), première étape de l’ANCOVA, était significative (soit pentes non parallèles).
Figures et tableaux
Le tableau 8-1 présente le degré de précision attendu et les statistiques sommaires des valeurs exigées pour l’étude des poissons. Les valeurs devant être évaluées sont la longueur, le poids corporel total, l’âge, le poids des gonades, le poids des œufs, la fécondité, le poids du foie ou de l’hépatopancréas, les anomalies et le sexe. Pour chaque valeur exigée, le degré de précision attendu et les statistiques sommaires à fournir sont indiqués.
Le tableau 8-2 présente les indicateurs et les critères d’effets pour différents plans d’étude s’appliquant à l’étude de la population de poissons. Les principaux indicateurs d’effets comprennent la croissance, la reproduction, la condition et la survie. Chaque indicateur d’effet est accompagné par la liste des critères d’effets pour chacun des trois plans d’étude : échantillonnage létal, échantillonnage non létal et étude fondée sur les mollusques sauvages.
Le tableau 8-3 présente les critères d’appui à utiliser pour les analyses complémentaires. Les indicateurs d’effets, soit l’utilisation de l’énergie et le stockage de l’énergie, sont associés aux critères d’appui et aux méthodes statistiques nécessaires.
Le tableau 8-4 présente un résumé des critères d’effets analysés au moyen de l’ANCOVA. Les principaux critères d’effets comprennent la condition, le poids relatif du foie, le poids relatif des gonades, le poids selon l’âge, la taille selon l’âge et la fécondité relative. Chaque critère d’effet correspond à une variable dépendante et à une covariable.
Le tableau 8-5 présente les critères d’effets et les critères d’appui pour l’exploitabilité des poissons, ainsi que les méthodes statistiques. Les variables et les méthodes statistiques des critères d’effets et des critères d’appui sont fournies.
Le tableau 8-6 illustre la méthode statistique utilisée pour déterminer la présence d’un effet pour chacun des sept plans d’étude. Chaque plan d’étude correspond à une méthode statistique.
Le tableau 8-7 présente les tailles d’échantillon nécessaires pour détecter une différence de ± 2 ET relativement aux valeurs indiquées de a (0,01, 0,05 et 0,10) et 1-b (0,99, 0,95, 0,90 et 0,80).
La figure A1-1 est un diagramme de dispersion illustrant le poids des gonades en fonction du poids corporel de Catostomus macrocheilus femelles. L’axe des x représente le poids corporel, alors que l’axe des y représente le poids des gonades. La ligne du graphique représente un indice gonadosomatique = 1 %.
La figure A1-2 est un diagramme de dispersion illustrant le poids des gonades en fonction du poids corporel de Lota lota femelles. L’axe des x représente le poids corporel, alors que l’axe des y représente le poids des gonades. La ligne du graphique représente un indice gonadosomatique = 1 %.
La figure A1-3 présente des diagrammes en rectangles et moustaches de femelles de Catostomus commersoni par sites. L’image A illustre une valeur aberrante détectée sur le site exposé, tandis que sur l’image B, cette valeur a été supprimée.
Le tableau A1-1 présente les statistiques sommaires de la « longueur ». Chaque espèce est associée à différents facteurs, notamment le sexe, le site, le nombre, la longueur moyenne, l’écart-type, l’erreur type, la longueur minimale et la longueur maximale.
La figure A1-4 est un diagramme de dispersion illustrant les résidus studentisés en fonction de l’ordre des observations pour l’ANOVA de la longueur de Catostomus commersoni femelles. L’axe des x représente l’ordre des observations, tandis que l’axe des y représente les résidus studentisés.
La figure A1-5 est un diagramme de dispersion illustrant le poids corporel en fonction de la longueur de Rhinichthys cataractae mâles. L’axe des x représente la longueur, tandis que l’axe des y représente le poids corporel. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site.
La figure A1-6 est un diagramme de dispersion illustrant le poids des gonades en fonction du poids corporel de Catostomus commersoni mâles. L’axe des x représente le poids corporel, alors que l’axe des y représente le poids des gonades. Les données sont ajustées à deux droites de régression distinctes, une pour chaque site.
La figure A1-7 est un diagramme de dispersion illustrant les résidus studentisés en fonction du poids corporel de Catostomus commersoni mâles; les données sont ajustées au modèle d’interaction y = β0 + β1x1 + β2x2 + β3(x1 · x2). L’axe des x représente le poids corporel, alors que l’axe des y représente les résidus studentisés.
La figure A1-8 est un diagramme de dispersion illustrant la distance de Cook par rapport au poids corporel de Catostomus commersoni mâles; les données sont ajustées au modèle d’interaction y = β0 + β1x1 + β2x2 + β3(x1 · x2). L’axe des x représente le poids corporel, alors que l’axe des y représente la distance de Cook.
La figure A1-9 est un diagramme de dispersion illustrant le poids corporel en fonction de la longueur de Catostomus catostomus mâles. L’axe des x représente la longueur, tandis que l’axe des y représente le poids corporel. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site.
La figure A1-10a est un diagramme de dispersion illustrant le poids des gonades en fonction du poids corporel de Catostomus catostomus mâles. L’axe des x représente le poids corporel, alors que l’axe des y représente le poids des gonades. Les données sont ajustées à deux droites de régression distinctes; une pour chaque site.
La figure A1-10b est un diagramme de dispersion illustrant les mêmes données que celles de la figure A1-10a, auxquelles s’ajoutent les valeurs minimales et maximales de la plage de chevauchement des valeurs de la covariable entre les sites établis.
La figure A1-11 est un diagramme de dispersion illustrant le poids des gonades en fonction du poids corporel de Catostomus commersoni femelles. L’axe des x représente le poids corporel, alors que l’axe des y représente le poids des gonades. Les données sont ajustées à deux droites de régression distinctes, une pour chaque site.
La figure A1-12a est un diagramme de dispersion illustrant le poids corporel en fonction de la longueur de Pleuronectes americanus mâles. L’axe des x représente la longueur, tandis que l’axe des y représente le poids corporel. Les données sont ajustées à deux droites de régression distinctes, une pour chaque site.
La figure A1-12b est un diagramme de dispersion illustrant le poids corporel en fonction de la longueur de Pleuronectes americanus mâles, et présentant un sous-ensemble des données de la figure A1-12a où seuls les poissons dont la longueur est supérieure à 1,375 sont conservés. L’axe des x représente la longueur, tandis que l’axe des y représente le poids corporel.
La figure A1-13 est un diagramme de dispersion illustrant le poids corporel en fonction de l’âge de Fundulus heteroclitus femelles. L’axe des x représente l’âge, tandis que l’axe des y représente le poids corporel. Les données sont ajustées à deux droites de régression distinctes, une pour chaque site.
La figure A2-1 est un diagramme décisionnel présentant les divers traitements des données des critères d’effets pour le poisson et le benthos. Ce diagramme indique les tableaux et les graphiques de l’annexe en lien avec ces méthodes.
La figure A2-2 présente des diagrammes en rectangles et moustaches sur les statistiques descriptives de l’âge selon l’espèce de poisson et le sexe. La plage des rectangles se situe entre le 30e et le 70e centiles, tandis que la plage des barres d’erreur, entre le 10e et le 90e centiles. L’âge moyen est représenté par une ligne pointillée, et l’âge médian est représenté par une ligne continue.
La figure A2-3 est un graphique illustrant les résultats de l’analyse de variance (ANOVA) de l’âge moyen des poissons prélevés dans les zones de référence et exposée. Les barres verticales représentent l’âge moyen, tandis que les barres horizontales représentent l’erreur type.
La figure A2-4 est un graphique illustrant la régression linéaire du poids du foie du poisson en fonction du poids corporel, comme exemple de résumé des effets sur le poids du foie ou la taille des gonades, au moyen de l’exemple d’un Catostomus mâle. L’axe des x représente le poids des poissons, tandis que l’axe des y représente le poids du foie.
La figure A2-5 est un graphique illustrant les statistiques descriptives de la densité totale des invertébrés benthiques provenant d’un plan contrôle-impact. La plage des diagrammes en rectangles se situe entre le 30e et le 70e centiles, tandis que la plage des barres d’erreur, entre le 10e et le 90e centiles. La densité moyenne est représentée par une ligne pointillée, et la densité médiane, par une ligne continue.
La figure A2-6 est un graphique illustrant les résultats de l’analyse de variance de la densité totale des invertébrés benthiques au moyen d’un plan contrôle-impact. Les valeurs indiquées sont les moyennes et les erreurs types correspondantes.
La figure A2-7 est un diagramme de dispersion illustrant la densité totale des invertébrés benthiques en fonction de la distance du diffuseur provenant d’un plan d’échantillonnage par gradient linéaire. L’axe des x représente la distance du diffuseur (en kilomètres), alors que l’axe des y représente la densité totale (le nombre d’individus par mètre carré).
Le tableau A2-1 présenteles statistiques descriptives de l’âge selon l’espèce de poisson et le sexe. À l’aide de l’exemple de femelles de Cottus sp., des renseignements sur la zone, l’âge moyen, l’écart-type, l’erreur type, le nombre de spécimens, l’âge maximal et l’âge minimal sont fournis.
Le tableau A2-2 présente les résultats de l’analyse de variance de l’âge selon l’espèce de poisson et le sexe. Les sources de variation comprennent les sources intergroupes, les sources intragroupes et le total. D’autres renseignements, comme la somme des carrés, les degrés de liberté, le carré moyen, le rapport F, la valeur p et la signification lorsque p est inférieure à 0,05 sont inclus.
Le tableau A2-3 présente les résultats de l’analyse de covariance du poids du foie par rapport au poids corporel selon le sexe et l’espèce. À l’aide de l’exemple de mâles de Catostomus sp., les résultats de l’ANCOVA pour la zone de référence et la zone exposée sont indiqués. Pour chaque zone, le nombre de spécimens, la pente de la droite de régression (données transformées en log), l’écart-type et le coefficient de détermination (R2) sont fournis. Pour répondre à la question « les pentes sont-elles différentes? », la signification de la valeur p indiquée est comparée à une valeur p de 0,05. De même, le moyenne des moindres carrés (MMC) et l’écart-type de chacune des deux zones sont indiqués, tout comme l’antilog des MMC et, enfin, l’ampleur de la différence sous forme de pourcentage. Pour la deuxième question : « les moyennes sont-elles différentes? », la réponse est fournie par une comparaison entre la valeur p indiquée et une valeur p de 0,05.
Le tableau A2-4 est un tableau sommaire des résultats sur les poissons. Les renseignements fournis comprennent notamment le niveau trophique (poissons), l’espèce, le sexe, le type de réponse, le critère d’effet, la présence d’effet, la direction et l’ampleur.
Le tableau A2-5 présente les statistiques descriptives de la densité totale des invertébrés benthiques. Les principales statistiques descriptives comprennent la zone, la moyenne, l’écart-type, l’erreur type, le nombre d’échantillons, la densité maximale et la densité minimale.
Le tableau A2-6 présente les résultats de l’analyse de variance de la densité totale des invertébrés benthiques. Les sources de variation comprennent les sources intergroupes, les sources intragroupes et le total. D’autres renseignements, comme la somme des carrés, les degrés de liberté, le carré moyen, le rapport F, la valeur p et la signification lorsque la valeur p indiquée est inférieure à 0,05 sont inclus.
Le tableau A2-7 présente un sommaire de toutes les statistiques descriptives sur les invertébrés benthiques. Les principales statistiques descriptives comprennent le critère d’effet, la zone, l’écart-type, l’erreur type et le nombre d’échantillons. Les moyennes, les valeurs maximales et les valeurs minimales sont indiquées par rapport aux taxons, à la densité, à l’indice de régularité de Simpson et à l’indice de Bray-Curtis.
Le tableau A2-8 illustre un sommaire de tous les résultats relatifs aux invertébrés benthiques. Le niveau trophique (benthos), le critère d’effet, la présence d’effet, la direction et l’ampleur sont fournis. Les critères d’effets comprennent notamment la densité, le nombre de taxons, l’indice de régularité de Simpson et l’indice de Bray-Curtis.
Le tableau A2-9 présente un sommaire global des effets sur les sites. Le niveau trophique (poissons d’abord, benthos ensuite) est indiqué; ensuite, pour les poissons : l’espèce, le sexe, le type de réponse, le critère d’effet, la présence d’effet, la direction et l’ampleur sont fournis; et pour le benthos : le critère d’effet, la présence d’effet, la direction et l’ampleur sont fournis.
Le tableau A3-1 présente la moyenne, l’écart-type et la taille de l’échantillon (n) pour les mesures effectuées sur le Meunier noir (Catostomus commersoni) au cours de l’étude. Les mesures consignées sont exprimées selon le sexe et la zone, et comprennent notamment la longueur à la fourche, le poids corporel, le poids des gonades, le poids du foie et l’âge.
Le tableau A3-2 illustre la taille selon l’âge(longueur) en fonction de l’âge du Meunier noir femelle au moyen d’une analyse de covariance. Les renseignements sont présentés dans deux tableaux. Le tableau (a) présente une analyse préliminaire de l’égalité des pentes. Les sources comprennent la zone, le log(âge), la zone multipliée par le log(âge) et l’erreur. Les renseignements établis pour chacune des sources comprennent la somme des carrés, les degrés de liberté, le carré moyen, le rapport F et la valeur p. Le tableau (b) est la table du modèle d’ANCOVA (test des moyennes ajustées). Les sources comprennent notamment la zone, le log(âge) et l’erreur. Comme dans le cas du tableau (a), pour chacune des sources du tableau (b), la somme des carrés, les degrés de liberté, le carré moyen, le rapport F et la valeur p sont indiqués.
Le tableau A3-3 présente un exemple d’étude du nombre de poissons requis pour déceler des différences significatives dans les critères reliés aux poissons entre les zones; l’erreur quadratique moyenne (EQM) du modèle a été utilisée comme estimation de la variabilité. Les tailles de l’échantillon ont été calculées selon un seuil critique d’effet = 0,90 et a = 0,05. Toutes les données ont été transformées en log.