
Intelligence artificielle et extraction de renseignements de diverses sources mentionnées dans les médias

 Téléchargez cet article en format PDF
Téléchargez cet article en format PDFPublié par : L’Agence de la santé publique du Canada
Numéro : Volume 46–6 : Intelligence artificielle en santé publique
Date de publication : 4 juin 2020
ISSN : 1719-3109
Soumettre un article
À propos du RMTC
Naviguer
Volume 46–6, le 4 juin 2020 : Intelligence artificielle en santé publique
Aperçu
Application d’algorithmes de traitement du langage naturel pour extraire des informations d’articles de presse dans le cadre de la surveillance événementielle
Victoria Ng1, Erin E. Rees1, Jingcheng Niu2, Abdelhamid Zaghlool3, Homeira Ghiasbeglou3, Adrian Verster4
Affiliations
1 Laboratoire national de microbiologie, Agence de la santé publique du Canada
2 Département de sciences informatiques, Université de Toronto, Toronto, ON
3 Centre de mesures et d’interventions d’urgence, Agence de la santé publique du Canada
4 Direction des aliments, Santé Canada, Ottawa, ON
Correspondance
Citation proposée
Ng V, Rees EE, Niu J, Zaghlool A, Ghiasbeglou H, Verster A. Application d’algorithmes de traitement du langage naturel pour extraire des informations d’articles de presse dans le cadre de la surveillance événementielle. Relevé des maladies transmissibles au Canada 2020;46(6):211–7. https://doi.org/10.14745/ccdr.v46i06a06f
Mots-clés : traitement du langage naturel, TLN, surveillance événementielle, algorithmes, extraction d’informations, données de sources ouvertes
Résumé
Cet article porte sur l’application du traitement du langage naturel (TLN) pour l’extraction d’informations dans les systèmes de surveillance événementielle (SSE). Nous décrivons les applications courantes de l’extraction d’informations à partir d’articles de presse et de sources médiatiques de sources ouvertes dans les SSE, les méthodes, la valeur en matière de santé publique, les difficultés et les nouveaux développements.
Contexte
Les méthodes de traitement du langage naturel (TLN) permettent aux ordinateurs d’analyser, de traiter et de tirer un sens du discours humain. Le domaine du TLN existe depuis les années 1950Note de bas de page 1; toutefois, les progrès de la technologie et des méthodes de ces dernières années ont rendu les applications de TLN plus faciles à mettre en œuvre, certaines tâches menant à des meilleurs résultats que les performances humainesNote de bas de page 2. Il existe de nombreuses applications quotidiennes du TLN, notamment la traduction automatique, la reconnaissance du pourriel et la reconnaissance vocale. Le TLN est un outil puissant dans le domaine des soins de santé en raison des volumes importants de données textuelles qui sont produites, par exemple les dossiers de santé électroniques. En effet, les dossiers de santé électroniques ont déjà fait l’objet d’applications du TLN, notamment pour la détection des proliférations mélanocytairesNote de bas de page 3Note de bas de page 4, du risque de démenceNote de bas de page 5 et des phénotypes neurologiquesNote de bas de page 6. Cependant, les applications du TLN dans le domaine des soins de santé vont au-delà des dossiers médicaux électroniques. Par exemple, il est possible d’identifier les personnes atteintes de la maladie d’Alzheimer à partir de leurs habitudes langagièresNote de bas de page 7.
Cet article porte principalement sur l’application du TLN pour l’extraction d’informations dans les systèmes de surveillance événementielle (SSE). Nous décrivons les applications courantes de l’extraction d’informations à partir d’articles de presse et de sources médiatiques de sources ouvertes dans les SSE, les méthodes, la valeur en matière de santé publique, les difficultés et les nouveaux développements.
Les SSE exploitent l’internet pour trouver des données de sources ouvertes, en s’appuyant sur des sources informelles (e.g. les activités des médias sociaux) et des sources formelles (e.g. les rapports médiatiques ou épidémiologiques des individus, des médias ou des organisations de santé) pour aider à détecter les menaces émergentesNote de bas de page 8. Les systèmes opérationnels comprennent le Réseau mondial de renseignement de santé publique (RMISP) de l’Agence de la santé publique du CanadaNote de bas de page 9, HealthMapNote de bas de page 10 et le renseignement sur les épidémies provenant de sources ouvertes de l’Organisation mondiale de la SantéNote de bas de page 11. En raison de la variété, de la rapidité et du volume croissants des informations numériques, une multitude de données non structurées à source ouverte sont générées quotidiennement, principalement sous forme de communications verbales ou écritesNote de bas de page 9. Les données de sources ouvertes non structurées contiennent des informations pertinentes sur les menaces émergentes qui peuvent être traitées pour extraire des données structurées du bruit de fond afin de faciliter la détection précoce des menacesNote de bas de page 12. Pour les SSE, cela comprend des informations sur la nature de l’événement (classification de la menace; nombre de cas), le lieu de l’événement (géolocalisation) et le moment de l’événement (informations temporelles). La capacité à identifier ces informations permet aux gouvernements et aux chercheurs de surveiller les menaces de maladies infectieuses émergentes et d’y répondre.
L’un des défis de la surveillance des maladies infectieuses, comme la COVID-19, est qu’une immense quantité de données textuelles est continuellement générée et, dans une pandémie en cours, cette quantité peut être bien supérieure à ce que les humains sont capables de traiter. Les algorithmes du TLN peuvent aider à ces efforts en automatisant le filtrage de grands volumes de données textuelles afin de trier les articles par degré d’importance et d’identifier et d’extraire les éléments d’information importants.
Dans cet article, nous discutons de certains algorithmes importants de TLN et de la manière dont ils peuvent être appliqués à la santé publique. Consultez le tableau 1 pour un glossaire de la terminologie technique courante en TLN.
| Terme | Définition |
|---|---|
| Annotation (linguistique) | L’association de notations descriptives ou analytiques avec des données linguistiques, généralement effectuée pour générer un corpus pour l’entraînement des algorithmes |
| Apprentissage automatique (AA) | Étude des algorithmes informatisés qui apprennent des modèles à partir d’expériences. Les approches de l’AA comprennent l’apprentissage supervisé (l’algorithme apprend à partir d’échantillons d’apprentissage étiquetés), non supervisé (l’algorithme créé des modèles à partir de données non étiquetées), ou semi-supervisé (l’algorithme apprend à l’aide d’une petite quantité de données étiquetées et une grande quantité de données non étiquetées) |
| Apprentissage non supervisé | Un type de méthode d’AA qui n’utilise pas données étiquetées, mais plutôt des approches analytiques de regroupement et de composantes principales afin que l’algorithme puisse trouver des attributs communs pour regrouper les données en différents résultats |
| Apprentissage supervisé | Les algorithmes issus de l’apprentissage supervisé représentent un type d’algorithme de l’AA qui apprend à partir de paires entrée-sortie étiquetées. Les attributs des données d’entrée sont extraits automatiquement grâce à l’apprentissage, et les modèles sont généralisés à partir de ces attributs afin de produire des prédictions sur les sorties. Les algorithmes communs incluent les modèles cachés de Markov (HMM), les arbres décisionnels, les modèles d’estimation basés sur l’entropie maximale, les machines à vecteur de support (SVM) et les champs conditionnels aléatoires (CRF) |
| Corpora (singulier - corpus) | Un ensemble d’articles où le texte non structuré a été annoté (étiqueté) pour identifier différents types d’entités nommées. Des corpora sont conçus pour différents domaines afin d’entraîner les algorithmes d’AA à identifier des entités nommées (e.g. le corpus WikToR d’articles Wikipédia pour les emplacements géographiques, le corpus TimeBank de nouveaux documents de rapport pour les informations temporelles) |
| Entité nommée (EN) | Un mot ou une phrase qui identifie un élément ayant des attributs particuliers qui le distinguent d’autres éléments ayant des attributs similaires (e.g. une personne, une organisation, un lieu) |
| Fils RSS | RSS signifie Really Simple Syndication ou Rich Site Summary. Il s’agit d’un type de flux Web qui permet aux utilisateurs et aux applications de recevoir des mises à jour régulières et automatisées à partir du site Web de leur choix sans avoir à visiter manuellement ces sites Web pour obtenir les mises à jour |
| Géocodage | Également appelé géorésolution, il attribue des coordonnées géographiques à des toponymes |
| Géolocalisation | Un sous-ensemble de la REN qui permet d’identifier des entités géographiques dans un texte non structuré |
| Géoparsing | Le processus combiné du géomarquage et du géocodage |
| Intelligence artificielle (IA) | Une branche de l’informatique traitant de la simulation de l’intelligence humaine par des machines |
| Linguistique computationnelle (LC) | Branche de l’informatique qui tente de modéliser le langage humain (y compris divers phénomènes linguistiques et applications liés au langage) à l’aide d’algorithmes computationnels |
| Précision (également appelée valeur prédictive positive) | Pourcentage des entités nommées trouvées par l’algorithme qui sont correctes : (vrais positifs) / (vrais positifs + faux positifs) |
| Polysémie | L’association d’un mot ou d’une phrase ayant deux ou plusieurs significations distinctes (e.g. une souris est un petit rongeur ou un dispositif de pointage pour un ordinateur) |
| Rappel | Fraction du montant total des cas pertinents qui ont été effectivement récupérés (vrais positifs) / (vrais positifs + faux négatifs) |
| Reconnaissance d’entité nommée (REN) | Le processus d’identification d’un mot ou d’une phrase qui représente une EN dans le texte. La REN est anciennement apparue dans la sixième conférence de compréhension des messages (MUC-6), à partir de laquelle les REN ont été classés en trois catégories : ENAMEX (personne, organisation, lieu), TIMEX (date, heure) et NUMEX (argent, pourcentage, quantité) |
| Score F1 | Une mesure de la performance utilisée pour évaluer la capacité du TLN à identifier correctement les EN en calculant la moyenne harmonique de précision et de rappel : F1 = 2 * Précision * Rappel / (Rappel + Précision). Le score F1 privilégie les algorithmes équilibrés, car il tend vers le nombre le plus faible, minimisant l’incidence des grandes valeurs aberrantes et maximisant l’incidence des petites valeurs |
| Semi-supervisé | En raison des coûts élevés requis pour la création de données annotées, les algorithmes issus de l’apprentissage semi-supervisé apportent un équilibre coût-performance grâce à un apprentissage combiné à partir d’une petite quantité de données étiquetées (supervisé) et une grande quantité de données non étiquetées (non supervisé) |
| Synonymes | Les mots d’une même langue qui ont la même signification ou presque |
| Toponyme | L’EN du nom d’un lieu géographique tel qu’un pays, une province et une ville |
| Traitement du langage naturel (TLN) | Un sous-domaine de l’IA pour traiter les entrées en langage humain (naturel) pour diverses applications, y compris la reconnaissance automatique de la parole, la compréhension du langage naturel, la génération du langage naturel et la traduction automatique |
Les algorithmes de TLN et leur application à la santé publique
Le moyen le plus simple d’extraire des informations à partir de données textuelles non structurées est la recherche par mot-clé. Bien qu’efficace, cette méthode omet la question des synonymes et des concepts connexes (e.g. les nausées et vomissements sont liés aux maladies de l’estomac); elle ignore également le contexte de la phrase (e.g. en anglais, Apple peut être soit le fruit ou l’entreprise). Le problème de l’identification et de la classification des mots importants (entités) en fonction de la structure de la phrase est connu sous le nom de reconnaissance des entités nommées (REN)Note de bas de page 13. Les entités les plus courantes sont les personnes, les organisations et les lieux. De nombreuses méthodes de REN étaient fondées sur des règles, identifiant et classant les mots à l’aide de dictionnaires (e.g. dictionnaire des noms d’agents pathogènes) et de règles (e.g. en utilisant « H#N# » pour classer une nouvelle souche de grippe non trouvée dans le dictionnaire)Note de bas de page 14. Les synonymes et les concepts connexes peuvent être résolus à l’aide de bases de données qui organisent la structure des mots dans la langue (e.g. WordNetNote de bas de page 15). Les méthodes de REN les plus récentes utilisent des classifications et des relations prédéfinies dans les corpora pour développer des algorithmes d’apprentissage automatique (AA) afin d’identifier et de classifier les entitésNote de bas de page 13. Aux fins de la REN, les termes sont annotés en catégories et l’algorithme apprend à reconnaître d’autres exemples de la catégorie à partir du terme et de la structure de la phrase qui l’entoure. Comme les données linguistiques sont converties en jetons de mots dans le cadre de l’analyse, les algorithmes de TLN ne se limitent pas aux langues utilisant l’alphabet latin; ils peuvent également être utilisés avec des langues à base de caractères comme le chinois.
1. Classification des articles (type de menace)
La classification des articles par mots-clés taxonomiques en types de menaces permet aux utilisateurs du SSE de hiérarchiser les menaces émergentes. Par exemple, les analystes qui surveillent un événement peuvent filtrer les articles pour se concentrer sur une catégorie de menace spécifique. La REN fondée sur des règles identifie des mots-clés afin de relier chaque article à différentes catégories de menaces pour la santé (e.g. le type de maladie). Les mots-clés sont ensuite organisés en une taxonomie multilingue prédéterminée (e.g. « virus Zika » est une maladie infectieuse humaine, « peste équine » est une maladie infectieuse animale, etc.) qui peut être mise à jour à mesure que de nouvelles menaces sont découvertes. La taxonomie tire profit d’une structure linguistique similaire à celle de WordNetNote de bas de page 16. Cela permet d’atténuer une partie du problème de la correspondance des mots-clés, car elle permet aux synonymes et aux concepts connexes de se substituer les uns aux autres. (figure 1).
Figure 1 : Classification des articles

Description textuelle : Figure 1
Figure 1 : Classification des articles
La Figure 1 illustre un organigramme du processus de classification des articles par mots clés de taxonomie en types de menaces. Tout d’abord, on extrait le texte d’un article de nouvelles et on le passe dans l’algorithme. Cet exemple utilise les titres « Les leçons apprises sur le virus du Zika » et « Interdiction des transports de chevaux pouvant contenir la peste équine » qui ont été extraits de l’article de nouvelles. Ensuite, un algorithme de reconnaissance des entités nommées basé sur des règles est utilisé pour déterminer les mots clés pertinents au domaine, dans ce cas « Zika » et « Peste équine ». Ensuite, le système de surveillance basé sur l’événement utilise une taxonomie par mot clé pour déterminer le type de menace, dans ce cas « maladie infectieuse humaine » et « maladie infectieuse animale ».
2. Géoparsing
L’identification des lieux où des événements liés à la santé sont rapportés à partir d’articles peut aider à localiser les populations sensibles. Le géoparsing consiste à attribuer des coordonnées géographiques à des entités de localisation (c’est-à-dire des toponymes tels que la ville, le pays) identifiées dans un texte non structuré. Le processus commence par la géolocalisation, un sous-ensemble de REN pour identifier les toponymes, puis se poursuit avec le géocodage pour attribuer des coordonnées géographiques à partir d’un dictionnaire comme celui des noms géographiquesNote de bas de page 17. Les utilisateurs du géoparsing font appel à des méthodes de calcul qui sont fondées sur des règles, des statistiques et l’AA. L’approche générale du géoparsing consiste à caractériser les toponymes par un ensemble d’éléments (e.g. le nom du toponyme, la position du premier et du dernier caractère dans le texte, la longueur en caractères). Les informations sur les caractéristiques sont ensuite traitées au moyen de méthodes computationnelles pour relier chaque toponyme à un nom géographique dans une base de données de localisation (e.g. GeoNamesNote de bas de page 17), puis lui attribuer les coordonnées correspondantesNote de bas de page 18.
Les avancées en géoparsing, comme d’autres applications du TLN, visent à accroître la force des textes non structurés pour résoudre les ambiguïtés. Un progrès est l’utilisation de techniques d’apprentissage semi-supervisées qui utilisent des corpora générés par des programmes pour entraîner des algorithmes d’AA à partir de plus grands ensembles de données d’exemples annotés. L’utilisation de code pour annoter des articles est plus rapide et permet d’obtenir des corpora plus grands et plus cohérents que l’annotation humaineNote de bas de page 19. L’exploitation d’un contexte plus large résulte également de l’élargissement des informations sur les caractéristiques pour qu’elles soient topologiques (relations spatiales entre les toponymes, e.g. la distance par rapport au toponyme voisin le plus proche)Note de bas de page 20. Un toponyme tiré d’une phrase comme « il y a de nouveaux cas de grippe à Londres » peut être difficile à résoudre, car il existe de multiples lieux potentiels. Les coordonnées toponymiques peuvent être résolues en attribuant un biais en faveur des zones plus peuplées, car elles sont généralement mentionnées plus souvent dans le discours; cependant, les maladies émergentes ne favorisent pas toujours les zones très peuplées (figure 2).
Figure 2 : Géoparsing
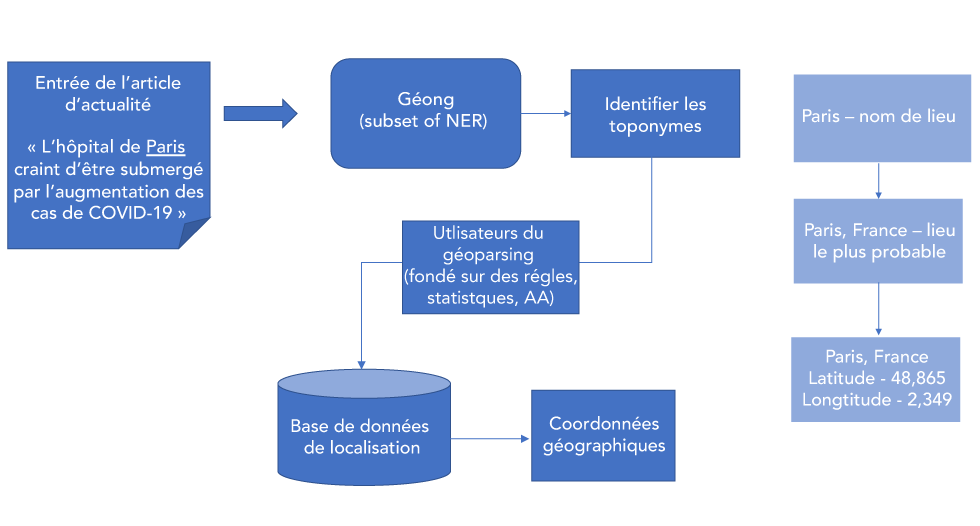
Description textuelle : Figure 2
Figure 2 : Géoparsing
La Figure 2 illustre le processus de géoparsing pour l’attribution des coordonnées géographiques aux entités de localisation. Tout d’abord, le texte d’un article de nouvelles est extrait et passé dans un logiciel de géoparsing pour extraire les renseignements géographiques, dans ce cas le texte est « L’hôpital de Paris craint d’être débordé à mesure que les cas de COVID-19 augmentent ». Le géomarquage, un sous-ensemble de reconnaissance d’entité nommée, est utilisé par les utilisateurs du géoparsing pour indiquer les toponymes, dans ce cas le nom de lieu « Paris ». Lorsqu’on a indiqué le toponyme, on utilise des algorithmes fondés sur des règles ou des statistiques d’apprentissage automatique dans le géoparsing pour produire des coordonnées géographiques, dans ce cas les coordonnées de Paris, en France (latitude 48.865 et longitude 2.349).
3. Extraction d’informations temporelles et raisonnement temporel
L’identification du moment où se produisent les événements décrits dans les articles est nécessaire pour établir une chronologie cohérente de ces événements. Il est important de pouvoir différencier un article rapportant un nouvel événement d’un article rapportant un événement antérieur connu. Les identificateurs temporels les plus courants dans les SSE sont la date de publication de l’article et la date de réception ou d’importation (l’horodatage de la réception de l’article dans le SSE). Aucune de ces dates n’extrait le moment des événements décrits dans les articles. Un sous-ensemble du TLN — l’extraction d’informations temporelles — a été développé pour extraire ces informations. L’extraction d’informations temporelles est utilisée pour identifier les jetons dans le texte qui contiennent des informations temporelles sur des événements pertinents.
Deux sous-tâches d’extraction d’informations temporelles aident à résoudre les ambiguïtés découlant de récits compliqués relatant des événements multiples. Premièrement, l’extraction de relations temporelles se concentre sur la classification des relations temporelles entre les événements extraits et les expressions temporelles. En utilisant ces relations, les SSE peuvent ancrer les événements dans le temps (e.g. dans la phrase « la première infection a été signalée le 1er mai », la relation entre l’événement « infection » et la date « 1er mai » est utilisée pour horodater la première infection). Deuxièmement, le raisonnement temporelNote de bas de page 21 se concentre sur l’ordonnancement chronologique des événements par inférence.
Plusieurs systèmes d’extraction d’informations temporelles ont été développés, notamment TimeML (développé pour l’extraction temporelle d’articles de presse dans le domaine de la finance)Note de bas de page 22; ISO-TimeML (une version révisée de TimeML)Note de bas de page 23; et THYME (développé pour l’extraction temporelle dans les dossiers des patients)Note de bas de page 24. Les résultats ont démontré l’atteinte d’une performance quasi humaineNote de bas de page 25Note de bas de page 26Note de bas de page 27Note de bas de page 28. En se fondant sur ces normes d’annotation, une norme d’annotation pour les articles de presse dans le domaine de la santé publique, Temporal Histories of Epidemic Events (THEE), a récemment été développée pour les SSE par les auteurs de cet articleNote de bas de page 29 (figure 3).
Figure 3 : Extraction d’informations temporelles et raisonnement temporel
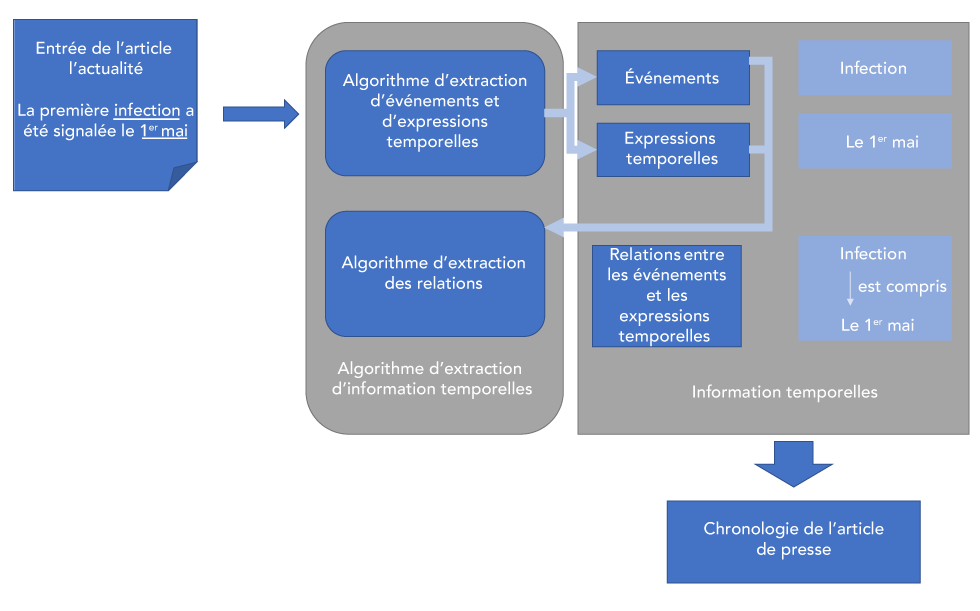
Description textuelle : Figure 3
Figure 3 : Extraction d’informations temporelles et raisonnement temporel
La Figure 3 illustre le processus d’extraction des renseignements temporels. Le texte d’un article de nouvelles est extrait, dans ce cas « La première infection a été signalée le 1er mai ». Le premier algorithme d’extraction des renseignements temporels, l’algorithme d’extraction de l’expression d’événement et de temps, est utilisé pour extraire les événements (dans ce cas « infection ») et les expressions temporelles (dans ce cas « 1er mai »). Le deuxième algorithme est un algorithme d’extraction des relations, qui indique les relations entre les événements et les expressions de temps. Dans ce cas, il indique la relation entre « infection » et « 1er mai », qui détermine la chronologie de l’article de nouvelles.
4. Extraction du nombre de cas
L’extraction du nombre de cas de maladie signalés dans les articles aiderait les utilisateurs d’un SSE à surveiller et à prévoir la progression de la maladie. Actuellement, il n’existe pas d’algorithme de TLN intégré dans les SSE capable de cette tâche. Cependant, il existe des algorithmes capables de s’attaquer à des tâches connexes qui peuvent être exploités pour développer un algorithme de comptage des cas. Les articles de presse en épidémiologie mentionnent fréquemment l’apparition de cas de maladie (e.g. « Il y a eu six nouveaux cas de Zika cette semaine »), de sorte que l’identification des cas nécessite de déterminer les relations entre une référence quantitative dans le texte (six nouveaux cas) et un terme de maladie (de Zika). De nombreux algorithmes identifient déjà les relations entre des entités dans divers domaines. Par exemple, l’algorithme RelEx identifie les relations entre les gènes qui sont enregistrés dans les résumés MEDLINE et fonctionne avec un score F1 de 0,80Note de bas de page 30. Un algorithme a été développé à partir de l’algorithme RelEx, pour identifier les phrases dans les articles de presse qui font état de cas de maladies d’origine alimentaireNote de bas de page 31.
Les auteurs de cet article développent et affinent cet algorithme pour extraire des informations sur le nombre de cas à partir de phrases qui ont été identifiés comme contenant des informations sur le nombre de cas (figure 4).
Figure 4 : Extraction du nombre de cas
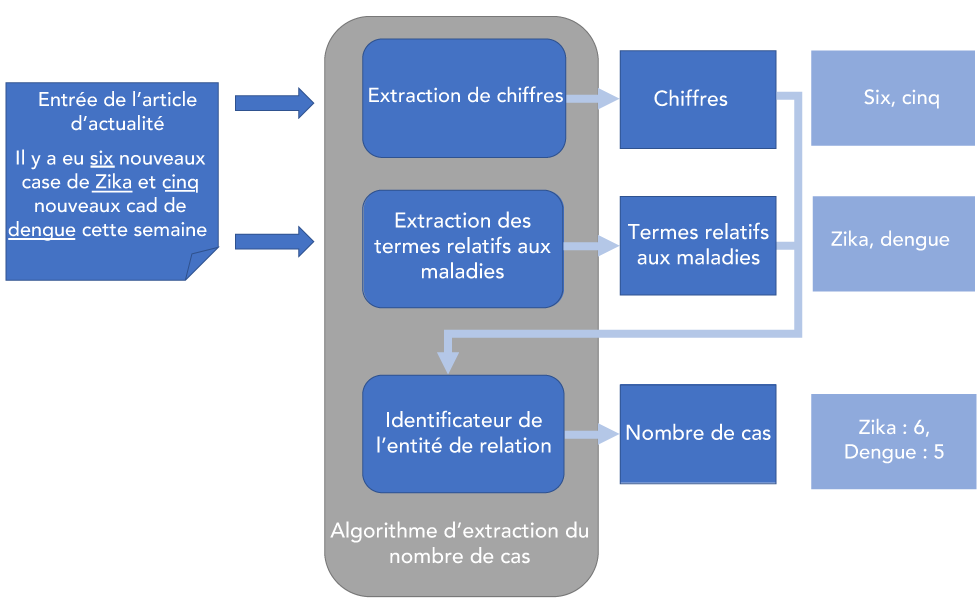
Description textuelle : Figure 4
Figure 4 : Extraction du nombre de cas
La Figure 4 illustre le processus d’utilisation d’algorithmes d’extraction du nombre de cas pour déterminer ce nombre dans les articles de nouvelles. Tout d’abord, le texte d’un article de nouvelles est extrait et passé dans l’algorithme, dans ce cas « Il y a eu six nouveaux cas de Zika et cinq nouveaux cas de dengue cette semaine ». L’algorithme d’extraction numérique indique les valeurs numérales (six, cinq) et l’algorithme d’extraction des termes liés à une maladie indique les termes liés à une maladie (Zika, dengue). Ces renseignements sont saisis dans un identificateur de relation d’entité pour déterminer le nombre de cas. Dans ce cas, il détermine un nombre de cas de six pour le Zika et de cinq pour la fièvre de dengue.
5. Résumé automatique du texte
L’objectif de la synthèse de texte est de créer rapidement et précisément un résumé concis qui conserve les informations essentielles du texte original. Le résumé de texte dans les SSE augmenterait le nombre d’articles qui peuvent être parcourus pour y détecter des menaces en réduisant le volume de texte à lire. Il existe deux principaux types de résumés de texte : soit un résumé fondé sur l’extraction et l’autre fondé sur la synthèse. La synthèse par extraction consiste à identifier les mots et phrases clés les plus importants du texte et à les combiner mot à mot pour produire un résumé. Le résumé fondé sur la synthèse utilise une technique plus sophistiquée qui consiste à paraphraser le texte original pour écrire un nouveau texte, imitant ainsi le résumé d’un texte humain.
Le résumé de texte en TLN est normalement développé à l’aide de modèles d’AA supervisés et formés sur des corpora. Dans les deux cas, soit le résumé par extraction et le résumé par synthèse, les phrases principales sont extraites du document source à l’aide de méthodes telles que le balisage des parties de discours, les séquences de mots ou d’autres méthodes de reconnaissance des formes linguistiquesNote de bas de page 32. Le résumé par synthèse va plus loin et tente de créer de nouvelles phrases et expressions à partir des phrases principales extraites. Un certain nombre de techniques sont utilisées pour améliorer le degré de synthèse, notamment des techniques d’apprentissage approfondi et des modèles de langue préformésNote de bas de page 33 (figure 5).
Figure 5 : Résumé automatique du texte
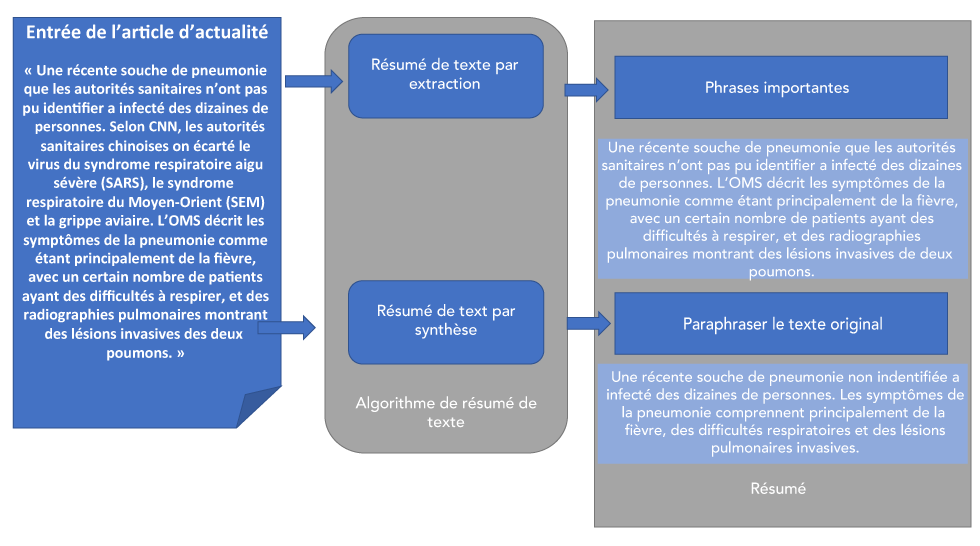
Description textuelle : Figure 5
Figure 5 : Résumé automatique du texte
La Figure 5 illustre le processus de synthèse d’un texte dans les systèmes de surveillance fondés sur les événements au moyen d’une synthèse de texte fondée sur l’extraction et l’abstraction. Tout d’abord, on extrait le texte d’un article de nouvelles et on le passe dans l’algorithme aux fins de synthèse. Dans cet exemple, le texte extrait révèle ce qui suit : « Une souche récente de pneumonie que les autorités sanitaires n’ont pas pu identifier a infecté des dizaines de personnes. Selon CNN, les autorités sanitaires chinoises ont exclu le virus du syndrome respiratoire aigu sévère (SRAS), le syndrome respiratoire du Moyen-Orient (SRMO) et la grippe aviaire. L’Organisation mondiale de la Santé (OMS) décrit les symptômes de la pneumonie comme étant principalement de la fièvre, avec un certain nombre de patients ayant des difficultés respiratoires, et des radiographies thoraciques montrant des lésions invasives des deux poumons. » Dans la synthèse du texte fondée sur l’extraction, des phrases importantes de l’article principal sont extraites textuellement, dans ce cas le résumé qui en résulte déclare ce qui suit : « Une souche récente de pneumonie que les autorités sanitaires n’ont pas été en mesure d’identifier a infecté des dizaines de personnes. L’OMS décrit les symptômes de la pneumonie comme étant principalement de la fièvre, avec un certain nombre de patients ayant des difficultés respiratoires, et des radiographies thoraciques montrant des lésions invasives des deux poumons. » Dans la synthèse de textes abstraits, le texte original est paraphrasé pour élaborer un résumé. Dans ce cas, le résumé paraphrasé déclare ce qui suit : « Une souche récente de pneumonie qui n’a pas été identifiée a infecté des dizaines de personnes. Les symptômes de la pneumonie comprennent principalement de la fièvre, des difficultés respiratoires et des lésions invasives des poumons. »
Discussion
Le domaine des soins de santé offre un nombre énorme d’applications potentielles pour le TLN en raison de l’omniprésence des données textuelles. Les dossiers de santé électroniques sont une source évidente de données pour l’application du TLN, mais les textes relatifs aux soins de santé vont bien au-delà des dossiers de santé; ils incluent les sources traditionnelles et les médias sociaux, qui sont les principales sources de données pour les SSE, en plus des rapports et documents officiels des gouvernements.
Comme les algorithmes de TLN peuvent interpréter des textes et extraire des informations essentielles de sources de données aussi diverses, ils continueront à jouer un rôle croissant dans la surveillance et la détection des maladies infectieuses émergentes. L’actuelle pandémie de COVID-19 est un exemple de cas où les algorithmes de TLN pourraient être utilisés pour la surveillance des crises de santé publique. (C’est d’ailleurs ce que plusieurs coauteurs de cet article sont en train de développer.)
Toutefois, même s’ils sont puissants, les algorithmes du TLN ne sont pas parfaits. Les principaux défis actuels consistent à regrouper plusieurs sources faisant référence à un même événement et à traiter les imperfections dans la précision de l’extraction des informations dues aux nuances des langues humaines. Les recherches en TLN sur l’extraction d’informations de la prochaine génération qui peuvent améliorer ces défis comprennent la résolution d’événements (déduplication et liaison des mêmes événements entre eux)Note de bas de page 34 et les avancées dans les approches de TLN neurales, comme les réseaux de transformateursNote de bas de page 35, le mécanisme d’attentionNote de bas de page 36 et les modèles de langage à grande échelle, comme ELMoNote de bas de page 37, BERTNote de bas de page 38 et XLNetNote de bas de page 39, visant à améliorer les performances actuelles des algorithmes.
Conclusion
Nous avons discuté de plusieurs algorithmes d’extraction de TLN communs aux SSE : la classification des articles, qui peut identifier les articles contenant des informations cruciales sur la propagation des maladies infectieuses; la géolocalisation, qui identifie où un nouveau cas de la maladie s’est produit; l’extraction temporelle, qui identifie quand un nouveau cas s’est produit; l’extraction du nombre de cas, qui identifie combien de cas se sont produits; et le résumé des articles, qui peut réduire considérablement la quantité de texte à lire par un humain.
Bien que le domaine du TLN pour l’extraction d’informations soit bien établi, de nombreux développements existants et émergents pertinents pour la surveillance de la santé publique se profilent à l’horizon. S’ils sont mis à profit, ces développements pourraient se traduire par une détection plus précoce des nouvelles menaces sanitaires ayant des répercussions immenses sur les Canadiens et le monde entier.
Conflit d’intérêts
Aucun.
Financement
E. E. Rees et V. Ng sont actuellement les co-enquêteurs principaux du Programme canadien pour la sûreté et la sécurité (PCSS), un programme financé par le ministère de la Défense nationale. La subvention est une subvention de trois ans intitulée « Incorporating Advanced Data Analytics into a Health Intelligence Surveillance System » — CSSP-2018-CP-2334.

Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution 4.0 International