
Artificial intelligence and extracting information from various media sources

 Download this article as a PDF
Download this article as a PDFPublished by: The Public Health Agency of Canada
Issue: Volume 46–6: Artificial intelligence in public health
Date published: June 4, 2020
ISSN: 1481-8531
Submit a manuscript
About CCDR
Browse
Volume 46–6, June 4, 2020: Artificial intelligence in public health
Overview
Application of natural language processing algorithms for extracting information from news articles in event-based surveillance
Victoria Ng1, Erin E Rees1, Jingcheng Niu2, Abdelhamid Zaghlool3, Homeira Ghiasbeglou3, Adrian Verster4
Affiliations
1 National Microbiology Laboratory, Public Health Agency of Canada
2 Department of Computer Science, University of Toronto, Toronto, ON
3 Centre for Emergency Preparedness and Response, Public Health Agency of Canada
4 Food Directorate, Health Canada, Ottawa, ON
Correspondence
Suggested citation
Ng V, Rees EE, Niu J, Zaghlool A, Ghiasbeglou H, Verster A. Application of natural language processing algorithms for extracting information from news articles in event-based surveillance. Can Commun Dis Rep 2020;46(6):186–91. https://doi.org/10.14745/ccdr.v46i06a06
Keywords: natural language processing, NLP, event-based surveillance, algorithms, information extraction, open-source data
Abstract
The focus of this article is the application of natural language processing (NLP) for information extraction in event-based surveillance (EBS) systems. We describe common information extraction applications from open-source news articles and media sources in EBS systems, methods, value in public health, challenges and emerging developments.
Background
Natural language processing (NLP) methods enable computers to analyse, process and derive meaning from human discourse. Although the field of NLP has been around since the 1950sFootnote 1, progress in technology and methods in recent years have made NLP applications easier to implement, with some tasks outperforming human performanceFootnote 2. There are many day-to-day applications of NLP including machine translation, spam recognition and speech recognition. NLP is a powerful tool in health care because of the large volumes of text data, for example, electronic health records, being produced. Indeed electronic health records have already been the focus of NLP applications, including detecting melanocytic proliferationsFootnote 3Footnote 4, the risk of dementiaFootnote 5 and neurological phenotypesFootnote 6. But NLP applications in health care extend beyond electronic health records, for example, it is possible to identify people with Alzheimer’s disease based on their speech patternsFootnote 7.
The focus of this article is the application of NLP for information extraction in event-based surveillance (EBS) systems. We describe common information extraction applications from open-source news articles and media sources in EBS systems, methods, value in public health, challenges and emerging developments.
EBS systems mine the Internet for open-source data, relying on informal sources (e.g. social media activity) and formal sources (e.g. media or epidemiological reports from individuals, media outlets and/or health organizations) to help detect emerging threatsFootnote 8. Operational systems include the Public Health Agency of Canada’s Global Public Health Intelligence NetworkFootnote 9, HealthMapFootnote 10 and the World Health Organization’s Epidemic Intelligence from Open SourcesFootnote 11. Due to the growing volume, variety and velocity of digital information, a wealth of unstructured open-source data is generated daily, mainly as spoken or written communicationFootnote 9. Unstructured open-source data contains pertinent information about emerging threats that can be processed to extract structured data from the background noise to aid in early threat detectionFootnote 12. For EBS systems, this includes information about what happened (threat classification; number of cases), where it happened (geolocation) and when it happened (temporal information). The ability to identify this information allows governments and researchers to monitor and respond to emerging infectious disease threats.
One of the challenges in infectious disease surveillance, such as COVID-19, is that there is an immense amount of text data continuously being generated, and in an ongoing pandemic, this amount can be far more than humans are capable of processing. NLP algorithms can help in these efforts by automating the filtering of large volumes of text data to triage articles into levels of importance and to identify and extract key pieces of information.
In this article, we discuss some important NLP algorithms and how they can be applied to public health. For a glossary of common technical terminology in NLP, see Table 1.
| Term | Definition |
|---|---|
| (Linguistic) annotation | The association of descriptive or analytic notations with language data, generally performed to generate a corpus for algorithm training |
| Artificial intelligence (AI) | A branch of computer science dealing with the simulation of human intelligence by machines |
| Computational linguistics (CL) | The branch of computer science trying to model human language (including various linguistic phenomena and language related applications) using computational algorithms |
| Corpora (singular – corpus) | A set of articles where the unstructured text has been annotated (labelled) to identify different types of named entity. Corpus are developed for different domains to train ML algorithms to identify named entities (e.g. WikToR corpus of Wikipedia articles for geographic locations, TimeBank corpus of new report documents for temporal information) |
| F1 score | A performance measure used to evaluate the ability of NLP to correctly identify NEs by calculating the harmonic mean of precision and recall: F1 = 2 * Precision * Recall / (Recall + Precision). The F1 score privileges balanced algorithms because the score tends toward the least number, minimizing the impact of large outliers and maximizing the impact of small ones |
| Geocoding | Also known as georesolution, assigns geographic coordinates to toponyms |
| Geoparsing | The combined process of geotagging and geocoding |
| Geotagging | A subset of named NER that identifies geographic entities in unstructured text |
| Machine learning (ML) | The study of computer algorithms that learn patterns from experience. ML approaches may be supervised (the algorithm learn from labelled training samples), unsupervised (the algorithm retrieve patterns from unlabeled data), or semi-supervised (the algorithm perform learning with a small set of labelled data and a large set of unlabeled data) |
| Named entity (NE) | A word or phrase that identifies an item with particular attributes that make it stand apart from other items with similar attributes (e.g. person, organization, location) |
| Natural language processing (NLP) | A subfield of AI to process human (natural) language inputs for various applications, including automatic speech recognition, natural language understanding, natural language generation and machine translation |
| Named entity recognition (NER) | The process of identifying a word or phrase that represents a NE within the text. NER formerly appeared in the Sixth Message Understanding Conference (MUC-6), from which NEs were categorized into three labels: ENAMEX (person, organization, location), TIMEX (date, time) and NUMEX (money, percentage, quantity) |
| Polysemy | The association of a word or phrase with two or more distinct meanings (e.g. a mouse is a small rodent or a pointing device for a computer) |
| Precision (also known as positive predictive value) | Percentage of named entities found by the algorithm that are correct: (true positives) / (true positives + false positives) |
| Recall | Fraction of the total amount of relevant instances that were actually retrieved (true positives / (true positives + false negatives) |
| Semi-supervised | Due to the high cost of creating annotated data, semi-supervised learning algorithms combine the learning from a small set of labelled data (supervised) and a large set of unlabeled data (unsupervised) to achieve the tradeoff between cost and performance |
| RSS feed | RRS stands for Really Simple Syndication or Rich Site Summary, it is a type of web feed that allows users and applications to receive regular and automated updates from a website of their choice without having to visit websites manually for updates |
| Supervised learning | Supervised learning algorithms is the type of ML algorithms that learn from labelled input-output pairs. Features of the input data are extracted automatically through learning, and patterns are generalized from those features to make predictions of the output. Common algorithms include hidden Markov models (HMM), decision trees, maximum entropy estimation models, support vector machines (SVM) and conditional random fields (CRF) |
| Synonyms | Words of the same language that have the same or nearly the same meaning as another |
| Toponym | A NE of the place name for a geographic location such as a country, province and city |
| Unsupervised learning | A type of ML method that does not use labelled data, but instead, typically uses clustering and principal component analytical approaches so that the algorithm can find shared attributes to group the data into different outcomes |
NLP algorithms and their application to public health
The simplest way to extract information from unstructured text data is by keyword search. Though effective, this ignores the issue of synonyms and related concepts (e.g. nausea and vomiting are related to stomach sickness); it also ignores the context of the sentence (e.g. Apple can be either a fruit or a company). The problem with identifying and classifying important words (entities) based on the structure of the sentence is known as named entity recognition (NER)Footnote 13. The most common entities are persons, organizations and locations. Many early NER methods were rule-based, identifying and classifying words with dictionaries (e.g. dictionary of pathogen names) and rules (e.g. using “H#N#” to classify a new influenza strain not found in the dictionary)Footnote 14. Synonyms and related concepts can be resolved using databases that organize the structure of words in the language (e.g. WordNetFootnote 15). Newer NER methods use classifications and relationships predefined in corpora to develop machine learning (ML) algorithms to identify and classify entitiesFootnote 13. For NER, terms are annotated to categories and the algorithm learns how to recognize other examples of the category from the term and surrounding sentence structure. Because language data are converted to word tokens as part of the analysis, NLP algorithms are not limited to languages using the Latin alphabet; they can also be used with character-based languages such as Chinese.
1. Article classification (threat type)
Classifying articles by taxonomy keywords into threat types allows EBS system users to prioritize emerging threats. For example, analysts monitoring an event can filter out articles to focus on a specific threat category. Rule-based NER identifies keywords to assign each article to different categories of health threats (e.g. disease type). Keywords are then organized into a predetermined, multilingual taxonomy (e.g. “Zika virus” is a human infectious disease, “African horse sickness” is an animal infectious disease, etc.) that can be updated as new threats are discovered. The taxonomy takes advantage of the structure of the language similar to WordNetFootnote 16. This mitigates part of the problem with keyword matching because it allows synonyms and related concepts to stand in for one another (Figure 1).
Figure 1: Article classification
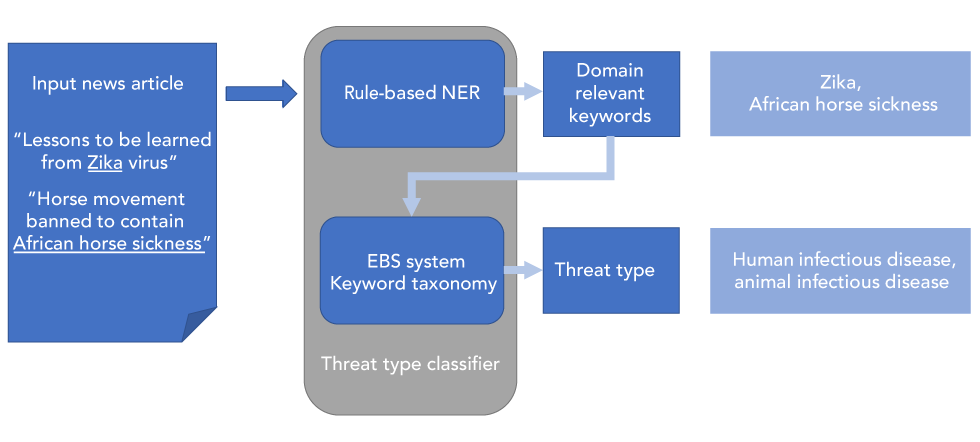
Text description: Figure 1
Figure 1: Article classification
Figure 1 depicts a flow chart of the article classification process by taxonomy keywords into threat types. First, text from a news article is extracted and run through the algorithm. This example uses the titles, “Horse movement banned to contain African horse sickness” that have been extracted from the news article. Next, a rule-based named entity recognition algorithm is used to identify domain relevant keywords, in this case “Zika” and “African horse sickness”. Then, the event-based surveillance system uses keyword taxonomy to identify the threat type, in this case “human infectious disease” and “animal infectious disease”.
2. Geoparsing
Identifying places where health-related events are reported from articles can help locate susceptible populations. Geoparsing is the task of assigning geographic coordinates to location entities (i.e. toponyms such as city, country) identified in unstructured text. The process starts with geotagging, a subset of NER for identifying the toponyms, and then geocoding to assign geographic coordinates from a dictionary such as from GeoNamesFootnote 17. Geoparsers use computational methods that are rule-based, statistical and based on ML. The general approach of geoparsing is to characterize toponyms by a set of features (e.g. toponym name, first and last character position in text, character length). Feature information is then processed by computational methods to link each toponym to a geographic name in a location database (e.g. GeoNamesFootnote 17) and then assign the corresponding coordinatesFootnote 18.
Advancements in geoparsing, like other NLP applications, focus on increasing leverage from unstructured text to resolve ambiguities. One advancement is using semi-supervised learning techniques that utilize programmatically generated corpora to train ML algorithms from larger datasets of annotated examples. Using code to annotate articles is faster and results in larger and more consistent corpora than from human annotationFootnote 19. Leveraging more context is also resulting from extending feature information to be topological (spatial relationships among toponyms, e.g. distance to closest neighbouring toponym)Footnote 20. A toponym from a phrase like “There are new cases of influenza in London” can be difficult to resolve because there are multiple potential locations. Toponym coordinates can be resolved by assigning a bias towards more populated areas because they are typically mentioned more often in discourse; however, emerging diseases do not always favour highly populated areas (Figure 2).
Figure 2: Geoparsing
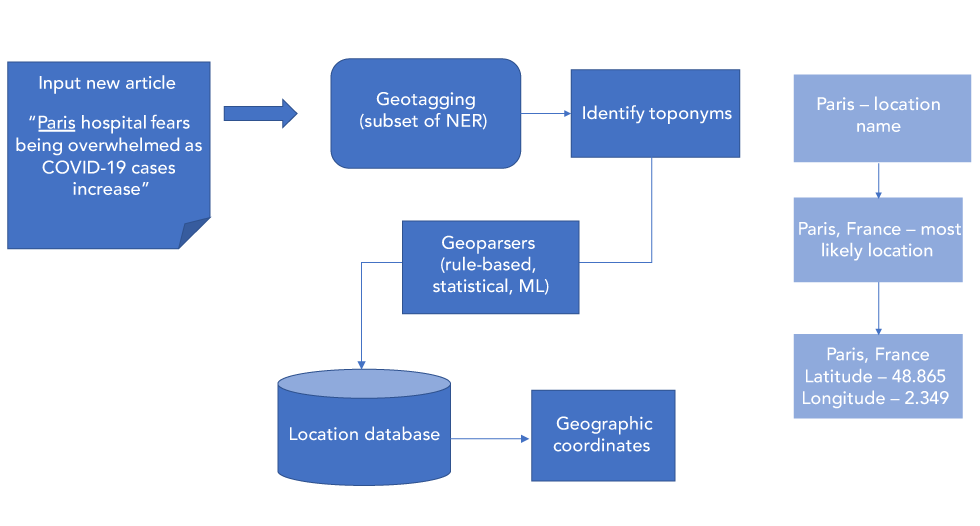
Text description: Figure 2
Figure 2: Geoparsing
Figure 2 showcases the process of geoparsing to assign geographic coordinates to location entities. First, text from a news article is extracted and run through a geoparser software to extract geographical information, in this case the text is “Paris hospital fears being overwhelmed as COVID-19 cases increase”. Geotagging, a subset of named entity recognition, is used by the geoparser to identify toponyms, in this case the location name “Paris”. Once the toponym has been identified, rule-based or statistical machine-learning based algorithms within the geoparser is used to produce geographic coordinates, in this case the coordinates of Paris, France (latitude of 48.865 and longitude of 2.349).
3. Temporal information extraction and temporal reasoning
Identifying the timing of events described in articles is necessary for coherent temporal ordering of those events. It is important to be able to differentiate an article reporting on a new event from an article reporting on a previous known event. The most common temporal identifiers in EBS systems are the article publication date and the received/import date (the timestamp for receiving the article into the EBS system). Neither of these dates extract the reported timing of event described in the articles. A subset of NLP—temporal information extraction—has been developed to extract this information. Temporal information extraction is used to identify tokens in text that contain temporal information of relevant events.
Two subtasks of temporal information extraction help resolve ambiguities arising from complicated narratives reporting on multiple events. First, temporal relation extraction focuses on classifying temporal relationships between the extracted events and temporal expressions. Using those relationships, EBS systems can anchor events to time (e.g. in the sentence “the first infection was reported on May 1st,” the relation between the event “infection” and the date “May 1st” is used to timestamp the first infection). Second, temporal reasoningFootnote 21 focuses on chronological ordering of events through inference.
Multiple temporal information extraction systems have been developed including TimeML (developed for temporal extraction of news articles in finance)Footnote 22; ISO-TimeML (a revised version of TimeML)Footnote 23; and THYME (developed for temporal extraction in patient records)Footnote 24. Results have reached near-human performanceFootnote 25Footnote 26Footnote 27Footnote 28. Based on these annotation standards, an annotation standard for news articles in the public health domain, Temporal Histories of Epidemic Events (THEE), was recently developed for EBS systems by the authors of this articleFootnote 29 (Figure 3).
Figure 3: Temporal information extraction and temporal reasoning
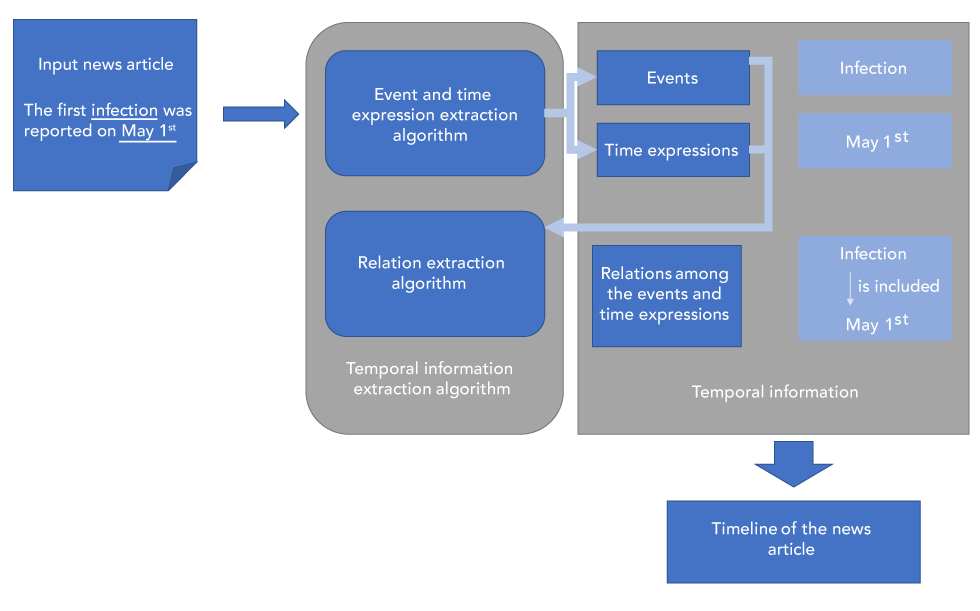
Text description: Figure 3
Figure 3: Temporal information extraction and temporal reasoning
Figure 3 showcases the temporal information extraction process. Text from a news article is extracted, in this case “The first infection was reported on May 1st”. The first temporal information extraction algorithm, the event and time expression extraction algorithm, is used to extract events (in this case “infection”) and time expressions (in this case “May 1st”). The second algorithm is a relation extraction algorithm, which identifies relations among the events and time expressions. In this case it identifies the relation between “infection” and “May 1st”, which identifies the timeline of the news article.
4. Case count extraction
Extracting the number of disease cases reported in articles would help EBS system users to monitor and forecast disease progression. Currently, there is no NLP algorithm incorporated into EBS systems capable of this task, however, there are algorithms capable of tackling related tasks that can be leveraged to develop a case count algorithm. News articles in epidemiology frequently mention the occurrence of disease cases (e.g. “There were six new cases of Zika this week”) so that identifying cases requires identifying the relationships between a quantitative reference in the text (six new cases) and a disease term (of Zika). Many algorithms already identify relationships between entities in diverse fields, for example, the RelEx algorithm identifies relations between genes that are recorded in MEDLINE abstracts and performs with an F1 of 0.80Footnote 30. Based on the RelEx algorithm, an algorithm has been developed to identify sentences in news articles that report on case counts of foodborne illnessesFootnote 31.
The authors of this article are developing and refining this algorithm to extract case count information from sentences that have been identified to contain case count information (Figure 4).
Figure 4: Case count extraction
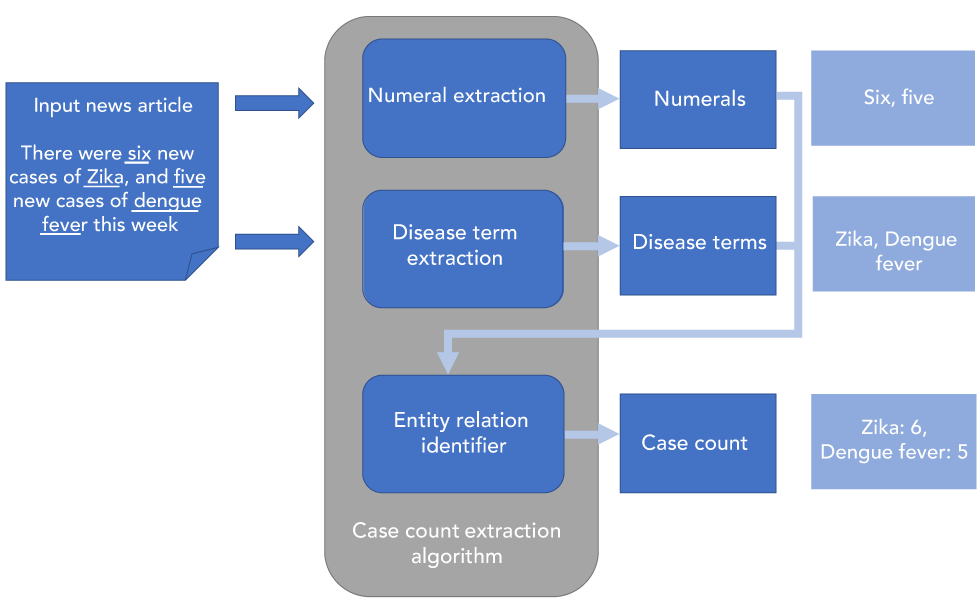
Text description: Figure 4
Figure 4: Case count extraction
Figure 4 depicts the process of using case count extraction algorithms to identify case counts in news articles. First, text from a news article is extracted and run through the algorithm, in this case “There were six new cases of Zika and five new cases of dengue fever this week”. The numeral extraction algorithm identifies the numerals (six, five) and the disease term extraction algorithm identifies disease terms (Zika, dengue fever). This information is inputted into an entity relation identifier to determine case count. In this case it determines a case count of 6 for Zika and 5 for dengue fever.
5. Automatic text summarization
The goal of text summarization is to quickly and accurately create a concise summary that retains the essential information in the original text. Text summarization in EBS systems would increase the number of articles that can be scanned for threat detection by reducing the volume of text that needs to be read. There are two main types of text summarization: extraction-based and abstraction-based. Extraction-based summarization involves identifying the most important key words and phrases from the text and combining them verbatim to produce a summary. Abstraction-based summarization uses a more sophisticated technique that involves paraphrasing the original text to write new text, thus mimicking human text summarization.
Text summarization in NLP is normally developed using supervised ML models trained on corpora. For both extraction-based and abstraction-based summarization, key phrases are extracted from the source document using methods including part-of-speech tagging, word sequences or other linguistic pattern recognitionFootnote 32. Abstraction-based summarization goes a step further and attempts to create new phrases and sentences from the extracted key phrases. A number of techniques are used to improve the level of abstraction including deep learning techniques and pre-trained language modelsFootnote 33 (Figure 5).
Figure 5: Automatic text summarization
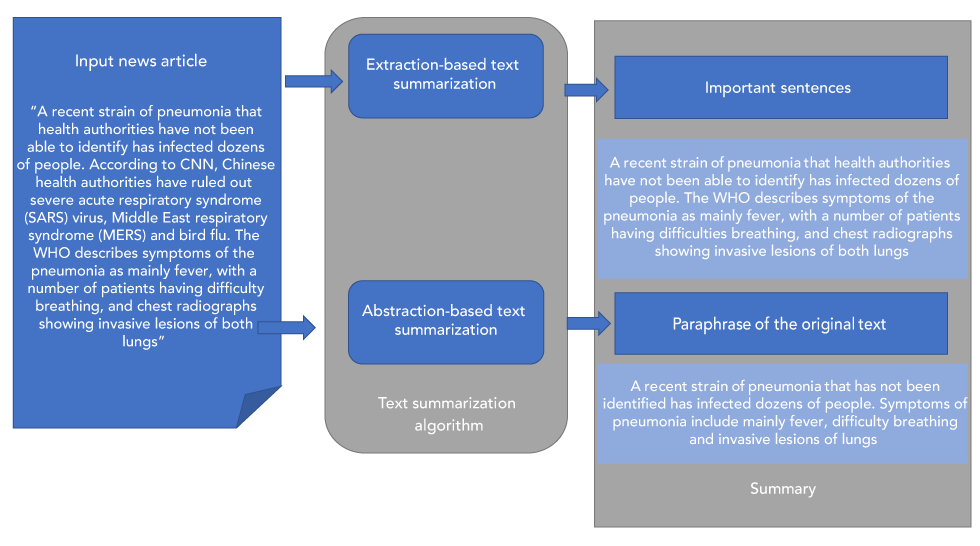
Text description: Figure 5
Figure 5: Automatic text summarization
Figure 5 showcases the process of text summarization in event-based surveillance systems through extraction-based and abstraction-based text summarization. First, text from a news article is extracted and run through the algorithm for summarization. In this example, the extracted text reads, “A recent strain of pneumonia that health authorities have not been able to identify has infected dozens of people. According to CNN, Chinese health authorities have ruled out severe acute respiratory syndrome (SARS) virus, Middle East respiratory syndrome (MERS) and bird flu. The WHO describes symptoms of the pneumonia as mainly fever, with a number of patients having difficulty breathing, and chest radiographs showing invasive lesions of both lungs”. In extraction-based text summarization, important sentences from the main article are extracted verbatim, in this case the resulting summary states, “A recent strain of pneumonia that health authorities have not been able to identify has infected dozens of people. The WHO describes symptoms of the pneumonia as mainly fever, with a number of patients having difficulty breathing, and chest radiographs showing invasive lesions of both lungs”. In abstract-based text summarization, the original text is paraphrased to develop a summary. In this case the paraphrased summary states, “A recent strain of pneumonia that has not been identified has infected dozens of people. Symptoms of pneumonia include mainly fever, difficulty breathing and invasive lesions of lungs”.
Discussion
NLP has a huge number of potential applications in health care because of the omnipresence of text data. Electronic health records are an obvious source of data for NLP application, but text relevant to health care extends far beyond health records; it includes traditional and social media sources, which are the main sources of data for EBS systems, in addition to official government reports and documents.
As NLP algorithms can interpret text and extract critical information from such diverse sources of data, they will continue to play a growing role in the monitoring and detection of emerging infectious diseases. The current COVID-19 pandemic is an example of where NLP algorithms could be used for the surveillance of public health crises. (This is, in fact, something several co-authors of this article are currently developing).
While NLP algorithms are powerful, they are not perfect. Current key challenges involve grouping multiple sources referring to the same event together and dealing with imperfections in the accuracy of information extraction due to nuances in human languages. Next-generation information extraction NLP research that can improve these challenges include event resolution (deduplication and linkage of the same events together)Footnote 34 and advancements in neural NLP approaches such as transformers networksFootnote 35, attention mechanismFootnote 36 and large-scale language models such as ELMoFootnote 37, BERTFootnote 38 and XLNetFootnote 39 to improve on the current performance of algorithms.
Conclusion
We have discussed several common NLP extraction algorithms for EBS systems: article classification, which can identify articles that contain crucial information about the spread of infectious diseases; geolocation, which identifies where a new case of the disease has occurred; temporal extraction, which identifies when a new case occurred; case count extraction, which identifies how many cases occurred; and article summarization, which can greatly reduce the amount of text for a human to read.
Although the field of NLP for information extraction is well established, there are many existing and emerging developments relevant to public health surveillance on the horizon. If capitalized, these developments could translate to earlier detection of emerging health threats with an immense impact on Canadians and the world.
Conflict of interest
None.
Funding
EE Rees and V Ng are currently co-Principal Investigators for a Canadian Safety and Security Program (CSSP), a federally-funded program from the Department of National Defence, the grant is a three-year grant titled ‘Incorporating Advanced Data Analytics into a Health Intelligence Surveillance System’ – CSSP-2018-CP-2334.
